
[Multi-Modal Fusion] DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal (CVPR'22)
2022. 12. 26. 00:53ㆍDevelopers 공간 [SOTA]
728x90
반응형
- Paper : https://openaccess.thecvf.com/content/CVPR2022/papers/Li_DeepFusion_Lidar-Camera_Deep_Fusion_for_Multi-Modal_3D_Object_Detection_CVPR_2022_paper.pdf
- Authors
- Google + Johns Hopkins Univ, CVPR’22
- Main Idea
- Image와 Lidar간의 correspondence를 향상시킬 수 있는 방법 제시
- Tasks : 3D Object Detection
- Results : Waymo
<구성>
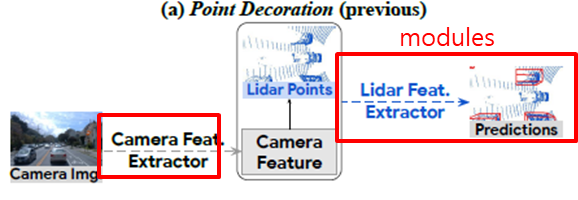
1. Problem : Mid-Level Fusion과 Point Decoration 기법의 문제점
2. Approach : InverseAug & LearnableAlign 기법
a. InverseAug
b. LearnableAlign : ≒ cross attention
3. Results
a. Setting
b. Results
글효과 분류1 : 논문 내 참조 및 인용
글효과 분류2 : 폴더/파일
글효과 분류3 : 용어설명
글효과 분류4 : 글 내 참조
1. Problem : Mid-Level Fusion과 Point Decoration 기법의 문제점
- Mid-level fusion(Deep Fusion)
- ex) Contfuse[18], EPNet[14], 4DNet[23]
- 카메라와 라이다 feature간의 효율적인 alignment mechanism이 부족하다.
- 왜필요한가?
- 성능을 위해서
- 여러개의 라이다 포인트는 Voxel로 aggregated 되는데, 하나의 복셀은 많은 카메라에 해당하는 정보를 가지고 있고, 이 정보는 각각 중요성이 동등하지 않기 때문에.
- Point Decoration
- ex) PointPainting[34], PountAugmenting[36]
- 기존엔, 잘학습된 detection과 segmentation model을 feature extractor로 활용하고, 이후에 3D point cloud에 덮어 씌워 졌다.
- 위 방법은 충분히 더 나아질 가능성이 있다. 왜?
- 카메라 정보가 카메라 정보를 처리하기 위한 모듈이 아닌, 3D PC에 최적화된 네트워크로 들어가고 있기 떄문에.
** PC : Point Clouds - camera extractor가 다른 독립된 task로부터 학습되었기 때문에.
- 다른 독립된 task로 학습하면 아래의 문제가 생깁니다.
--> domain gap
--> annotation efforts : annotation에 드는 품
--> additional computation cost : 추가 연산량
--> sub-optimal extracted features : 가장 최적화된 feature가 아닙니다.
- 다른 독립된 task로 학습하면 아래의 문제가 생깁니다.
- 카메라 정보가 카메라 정보를 처리하기 위한 모듈이 아닌, 3D PC에 최적화된 네트워크로 들어가고 있기 떄문에.
- 위 두가지의 공통 적인 Biggest challenges는 카메라와 라이다간의 correspondence를 찾아내는 것입니다.
2. Approach : InverseAug & LearnableAlign 기법
- 그럼 어떻게 correspondence를 찾아낼 것인가?
- 효율적인 Deep Feature-Fusion Pipeline을 만들어봅니다.
- Point-decoration fusion 기법에서 시작해, 위 언급된 두가지 단점을 없앤 mid-level fusion 기법을 만듭니다.
- 기존의 mid-level fusion의 문제점을 해결해 봅니다.
- Point-decoration fusion 기법에서 시작해, 위 언급된 두가지 단점을 없앤 mid-level fusion 기법을 만듭니다.
- Deep Feature-Fusion Pipeline
- 기존의 Voxel-based 3D detection을 활용
- PointPillars[17], CenterPoint[44]
- Point Decoration의 두가지 문제를 극복해봅니다
- 문제 : 카메라를 위해 3D PC에 최적화된 네트워크를 활용했다.
- raw points 들이 아닌 camera features와 lidar features를 fusion 합니다 (mid-level fusion)
- 이렇게 하면 camera signals이 PC에 최적화된 모듈에 직접적으로 들어가지 않습니다.
- 문제 : camera extractor가 다른 독립적인 tasks에서 학습이 되었다.
- convolutional layers를 활용해 end-to-end로 학습합니다.
- 문제 : 카메라를 위해 3D PC에 최적화된 네트워크를 활용했다.
- 위 방법을 통한 장점
- 많은 contextual 한 정보를 가진 Camera feature가 잘못되게 voxelize 되는 일이 없습니다.
- end-to-end이기 때문에 domain gap과 annotation issues가 덜어집니다.
- 위 방법에도 아직 남은 단점
- input-level decoration에 비해 deep feature level에서는 alignment가 부정확합니다.
- 이에 따라 아래 a.InverAug와 b.LearnableAlign 기법을 활용해 극복해봅니다.
- 기존의 Voxel-based 3D detection을 활용
- 효율적인 Deep Feature-Fusion Pipeline을 만들어봅니다.
a. InverseAug
- data augmentation에서 alignment의 중요성 (PPBA[6] 기법)
** PPBA : Improving 3d object detection through progressive population based augmentation (ECCV’20)
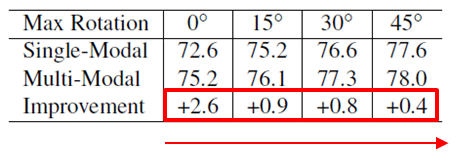
- Table 1 :다른 모든 augmentation을 disable하고, Random Rotation에 따른 변화를 보았습니다.
- camera images는 그대로 두고, point cloud에만 적용했습니다.
- 때문에, multi-modal에서 geometry 관련된 augmentation은 alignment를 악화할 것입니다.
- Single-modal : accuracy 가 충분히 boosted되는 것을 보아 augmentation 자체의 중요성을 확인 가능합니다.
- Multi-modal : rotation angle이 커질 수록 single-modal에 비해 multi-modal은 augmentation 효과가 줄어듭니다.
- 이는 alignment가 굉장히 critical하다는 것을 확인할 수 있습니다.
- 특히 point cloud는 z-축으로 rotate하고, image는 random flip을 한다면 더 문제는 커집니다.
- Table 1 :다른 모든 augmentation을 disable하고, Random Rotation에 따른 변화를 보았습니다.
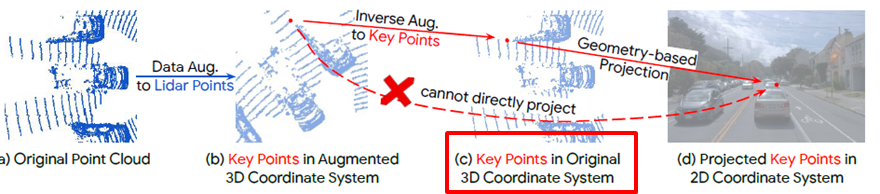
- InverseAug (Inverses geometric-related data augmentations)
- data augmentation 이후에 어떤 문제가 생길까?
- augmented된 공간에 있는 3D key point들은 단순히 lidar와 camera간의 파라미터를 통해 2D공간으로 위치시키는 것이 불가합니다.
- 그럼 어떻게 할까?
- geometry 관련 augmentation을 하는 경우, augmentation 파라미터 들을 저장합니다. (ex] rotation 각도)
- 퓨전 단계에서, 위 값을 활용해 모든 data augmentation들을 역으로 돌려 원래의 3D Key point를 찾습니다.
- 이후에 3D Key point에 일치하는 2D 좌표들을 가져옵니다.
- 이는 2D, 3D모두에 augmentation이 되어도 적용가능합니다.
- 그럼 어떤 augmentation을 적용할 것인가? PPBA augs[6]를 참고해 순서대로 아래와 같이 했다.
- RandomRoation (Geometry-related)
- WorldScaling (Geometry-related)
- GlobalTranslateNoise (Geometry-related)
- RandomFlip (Geometry-related)
- Frustum Dropout
- RandomDropLaserPoints
- data augmentation 이후에 어떤 문제가 생길까?

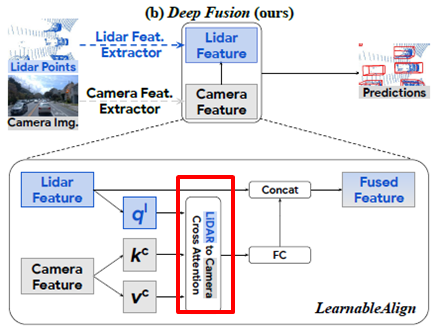
b. LearnableAlign : ≒ cross attention
-
-
- 현재 문제점
- 기존에는 3D Lidar point에 1:1로 매핑되는 camera pixel들을 찾아 퓨전했다.
- 하지만 현재 Deep feature-fusion을 사용하므로..
- Lidar feature 각각은 points의 부분집합(voxel)일 것이고,
- Camera feature는 polygon형태로 존재할 것이다.
- 즉, 이제는 "one voxel to many pixels"의 alignment 문제이다.
- 어떻게 alignment를 맞출 것인가?
- 가장 순수한 방법 : 한 voxel에 해당하는 모든 pixel들을 평균내기
- 하지만 한 voxel에 포함되는 모든 pixel들이 동등하게 중요하지는 않다.
- 즉, 어떤 pixel은 되게 중요한 카메라의 중요한 정보이지만, 어떤 pixel은 background정보를 가진 중요하지 않은 정보다.
- Learnable Align
- 두개의 modality간의 correlation을 dynamic하게 잡아내자
- 어떻게? standard Attention module + dynamic voxelization [45]
** dynamic voxelization : End-to-End multi-view fusion for for 3d object detection in lidar point clouds (CORL’20)
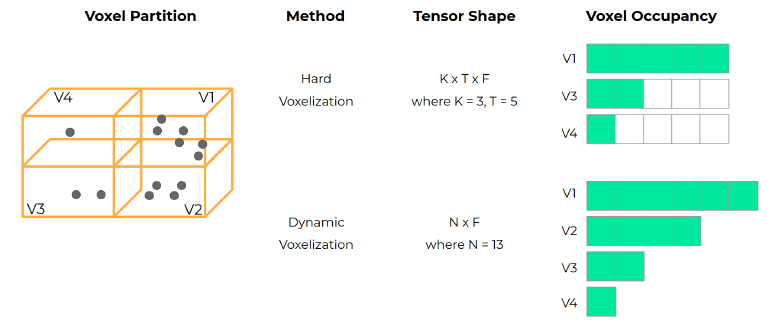
- voxel들은 dynamic voxelization을 통해 얻어냅니다.
- 아래 그림과 같이 voxel당 point의 개수가 정해져 있지 않습니다.
- 3개의 FC layers(256 filters) : Lidar, Camera 각각을 embedding 하기 위해서
- 1개 the voxel의 embedding ≫ query
- camera features의 embedding ≫ key, value
- attention module
- attention affinity matrix를 만들기 위해 query와 key 간의 내적을 합니다.
- 1x N correlations가 생깁니다. (1 voxel과 N개의 카메라 features의 관계)
- attention affinity matrix에 Softmax를 통해 weight할 준비를 마치고
- attention affinity matrix와 value를 곱해 aggregate합니다.
- FC layer(192 filters) : feature dimension을 맞춥니다.
- Concatenation : 기존 라이다 feature와 concat
- FC layer : channel을 줄이기 위해
- voxel들은 dynamic voxelization을 통해 얻어냅니다.
- 이후 3D OD network로 보내집니다. (CenterPoint[44], PointPillars[17])
- 가장 순수한 방법 : 한 voxel에 해당하는 모든 pixel들을 평균내기
- 현재 문제점
-
3. Results
a. Setting
- Datasets
- Waymo : 3D detection
- point cloud(nuScenes보다 dense합니다) + images (250° FOV)
- metric : AP, APH
- AP : 3D IoU
- Level1, Level2(Waymo에서 주요 metric)
- APH : heading 정확도로 weight 한 결과
- AP : 3D IoU
- Waymo : 3D detection
- Models
- 하기 3개의 유명한 Voxel-based 3D object detection를 재구현 했습니다.
- PointPillars[17], CenterPoint[44], 3D-MAN[43]
- 위 세개의 네트워크는 더 많은 MLP layer를 사용하고(256 hidden 사이즈), ReLU를 SILU로 바꾸는 등 개선된 버전도 만들었습니다.
- ex) PointPillars++, CenterPoint++, 3D-MAN++
- 하기 3개의 유명한 Voxel-based 3D object detection를 재구현 했습니다.
b. Results
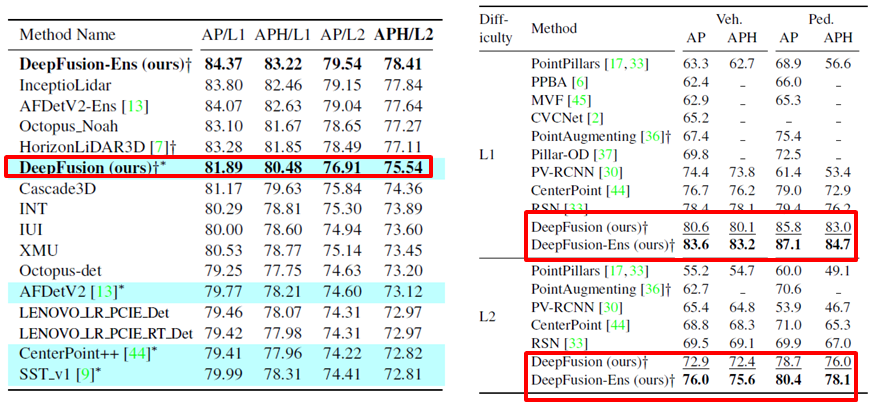
- Waymo Challenge(아래 첫번째 그림 왼쪽) : SOTA인 AFDetV22보다 2.42APH/L2 만큼 향상 된 결과를 보였습니다.
** Ens : Ensemble(앙상블) 기법 사용
** + : multi-modal 방법들 - Waymo Validation Set (아래 첫번째 그림 오른쪽) : 다른 기법들에 비해 상당히 앞선 결과를 보였습니다.
- 널리 퍼진 3D OD 프레임워크에 넣어 만들었으므로, 상당히 generic하다고 볼 수 있습니다.
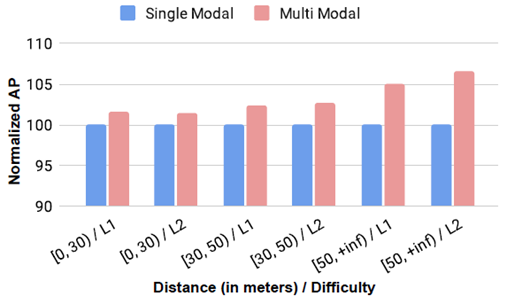
- 어디서 이런 향상 효과가 일어나게 되었을 까? (아래 두번째 그림) : long-range 오브젝트에 대해서 더욱 정확한 결과를 얻는 것을 볼 수 있었습니다.
- Learnable Align의 Attention map을 visualize한 결과 (아래 그림)
- 하얀색 박스 : 3D point pillar의 하나를 visualize한 것입니다. (voxel과 비슷한 개념)
- 빨간색 포인트 : attention map이 가리키고 있는 지역
- 결과 해석
- 구분력이 강한 지역에 집중해서 보는 경향이 있습니다.
ex) 사람의 머리부분 (라이다의 경우는 찾기가 힘들 것입니다.) - camera signals이 object의 boundary를 찾는데 도움을 주는 경향이 있습니다.
ex) 사람의 등 부분
- 구분력이 강한 지역에 집중해서 보는 경향이 있습니다.

후기 : camera parameter-free 하게 cross attention을 활용한 논문은 아니다. voxel 내부의 point와 camera pixel(이미 3D 공간으로 배치된)간의 weighted matching을 위한 논문으로 보인다.
728x90
반응형