
2023. 11. 8. 22:35ㆍDevelopers 공간 [SOTA]
- Paper : https://arxiv.org/pdf/1508.01211.pdf
- Authors
- Lvmin Zhang et al + Google Brain, ICASSP'16
- Main Idea
- 기존 DNN-HMM 모델과 다르게 (Acoustic Model, Pronunciation Model, Language Model)을 jointly하게 학습가능합니다.
- 기존 CTC와 다르게 단어 간의 indenpendence 가정 없이 학습이 가능합니다.
- Tasks : ASR(Automatic Speech Recognition)
- Results : Google Voice Search Tasks
<구성>
0. Before Start ...
a. 용어 정리
b. NLP(Natural Language Processing)
c. ASR(Automatic Speech Recognition)
d. ASR 모델의 예시
1. Problem
a. Traditional DNN-HMM
2. Approach
a. Listener's Listen
b. Speller's AttendAndSpell
c. Learning & Decoding
3. Results
a. Setting
b. Results
글효과 분류1 : 논문 내 참조 및 인용
글효과 분류2 : 폴더/파일
글효과 분류3 : 용어설명
글효과 분류4 : 글 내 참조
글효과 분류5 : 글 내 참조2
글효과 분류6 : 글 내 참조3
0. Before Start ...
Conversational AI에는 아래와 같은 다양한 task가 존재합니다.
- ASR(Automatic Speech Recognition)
- TTS(Text-To-Speech Synthesis)
- LLM(Large Language Models)
- NLP(Natural Language Processing)
이중에 ASR 분야의 핵심 논문인 LAS(Listen, Attend and Spell)을 소개하겠습니다.
시작 하기 전에 사전지식이 필요할 수도 있어 자세하게 내용을 정리해보았습니다. 중요한 개념의 경우 빨간색 형광펜으로 표시했습니다.
a. 용어 정리
1. 단어 관련
- 문장 분해
- Corpus(말뭉치) : 글 또는 말 텍스트들을 모아 놓은 NLP 학습에 사용되는 데이터
- Setenece(문장) : 의사 전달의 최소 단위
** Utterance : 발화 문장 단위
ex) 하늘이 참 높고 푸르다 - 어절 : 문장을 구성하는 마디 혹은 띄어쓰기 단위
ex) 하늘이, 참, 높고, 푸르다 - Word(단어,낱말) : 분립해 쓸 수 있는 말이나 문법적 기능 단위
ex) 하늘, 이, 참, 높고, 푸르다 - Morpheme(형태소) : 의미를 가지는 쪼개질 수 없는 최소의 단위.
ex) 하늘,이,참,높,고,푸르,다 - Syllable(음절) : 발음의 기본 단위, 자소로 이루어짐 (초성onset+중성nucleus+종성coda)
ex) 하,늘,이,참,높,고,푸,르,다
- 음절 분해
- Letter(글자) : 우리가 알고있는 글자
ex) 비,빔,밥,… - Phoneme(음소, 낱소리) : 소리를 구분하는 가장 작은 단위의 소리,
- 음운(Phoneme) = 음소(Phoneme) + 운소(Prosodeme)
** Phoneme이라는 영어가 겹치지만, Phoneme은 '음운'보다 '음소'로 더 많이 쓰임
음소 : 음운론 상 최소 단위로 자음 혹은 모음
운소 : 의미 분화에 관여하는 운율적 특징, 높낮이(고저)+길이(장단)+세기(강약) 등
음운 : 말의 뜻을 구별해주는 가장 작은 단위 - vs Phone(음성) : Phoneme은 인식하는 소리, Phone은 물리적인 소리
ex) 영어에서 "비빔밥"의 "비"는 p, "빔"은 b, "밥의 받침"은 p로 3개의 같은 소리로 들리는 Phoneme이 다른 Phone을 가진다. - vs Grapheme(자소) : Phoneme은 소리상의 요소, Grapheme은 표기상의 요소
ex) 국물의 중간 ㄱ을 예로, Phoneme ㅇ이지만, Grapheme은 ㄱ - Monophone, Triphone : phoneme을 표기하는 방법들
ex) /비빔빱/ = ㅂ,ㅣ,ㅂ,ㅣ,ㅁ,ㅃ,ㅏ,ㅂ
- 음운(Phoneme) = 음소(Phoneme) + 운소(Prosodeme)
- Grapheme(자소, 문자소) : 소리 단위를 대변하는 표기상 글자, Phoneme개수와 같다.
- 자소는 음소를 그대로 표현하도록 고안되어 대부분 1:1 대응한다. 즉, 문자가 소리를 직접적으로 표현
- g2p(graphene to phoneme) : 자소를 음소로 바꿔주는 것
** 반대 방향은 방법이 없어, dictionary를 만들거나 특별한 방법이 필요합니다.
ex) 비빔밥(ㅂ,ㅣ,ㅂ,ㅣ,ㅁ,ㅂ,ㅏ,ㅂ) → 비빔빱(ㅂ,ㅣ,ㅂ,ㅣ,ㅁ,ㅃ,ㅏ,ㅂ)
- Phone(음성) : 물리적인 소리로, 하나의 음소가 두개 이상의 음성으로 실현되기도한다.
ex) 비빔밥 : /비빔빱/의 ㅂ처럼 (Phoneme) 같은 소리로 인식될 수도 있지만 실제 표기는 [pi.bim.p͈ap̚](Phone)
- Letter(글자) : 우리가 알고있는 글자
- 기타 단위
- Frame : 음성인식 window 단위
2. 오디오 품질(음질) 관련 용어
- Sample-rate(kHz) : Analog 오디오에서 초당 취득되는 digital sample 수, 높을 수록 오디오 품질 및 선명도가 높아진다.
- 8kHz : 표준 전화 통신
- 16kHZ : 표준 전화 통신
- 22kHz : 오디오 스트리밍
- 44.1kHZ : 오디오 스트리밍
- Bit-rate(kbps) : Digital 오디오 파일에 포함된 데이터의 양으로 초당 전송하는 data 양. 높을 수록 오디오 품질이 좋아진다.
- Bit-rate = Sample-Rate * Bit-depth * Channels
ex) 44.1(kHz) * 16bits * 2(Stereo) = 1,411 Kbps - ex) CD음원 : 1411 kbps
- ex) MP3 : 256 kbps, 320kbps
- Bit-rate = Sample-Rate * Bit-depth * Channels
------------------------------------------------------------------------------
<LP와 CD를 비교하며 보는 Digital 과 Analog 의 차이>
1. Analog Audio (Tape, LP)
- 특징 : 많은 noise(-), 짧은 수명(-), 더 많은 정보(+)
** 사람 귀는 아날로그 sine 파 만을 듣는다 - 오디오 프로세스 = Analog input → AD converter → 믹싱,마스터링 → DAconvert[Analog]→output[Analog]
** Analog 사인파는 빨간색으로, Diginal 신호는 파란색으로 표시했습니다. - 시각 프로세스 = Digital input → Digital Processing → output
** 사람 눈은 디지털/아날로그 구분하지 못한다. - AD Converter의 과정과 문제점
- Step1. Sampling(표본화) : Sampling Rate에 따른 오차 발생
- Step2. Quantization(양자화) : 정해놓은 규칙에 의해 양자화 레벨을 정하므로 오류 발생
- Step3. Coding(부호화) : 문제 X
- 추가 문제점 Jitter(지터) : clock과 시간축으로 다름으로 인해 다르게 인식 되는 것
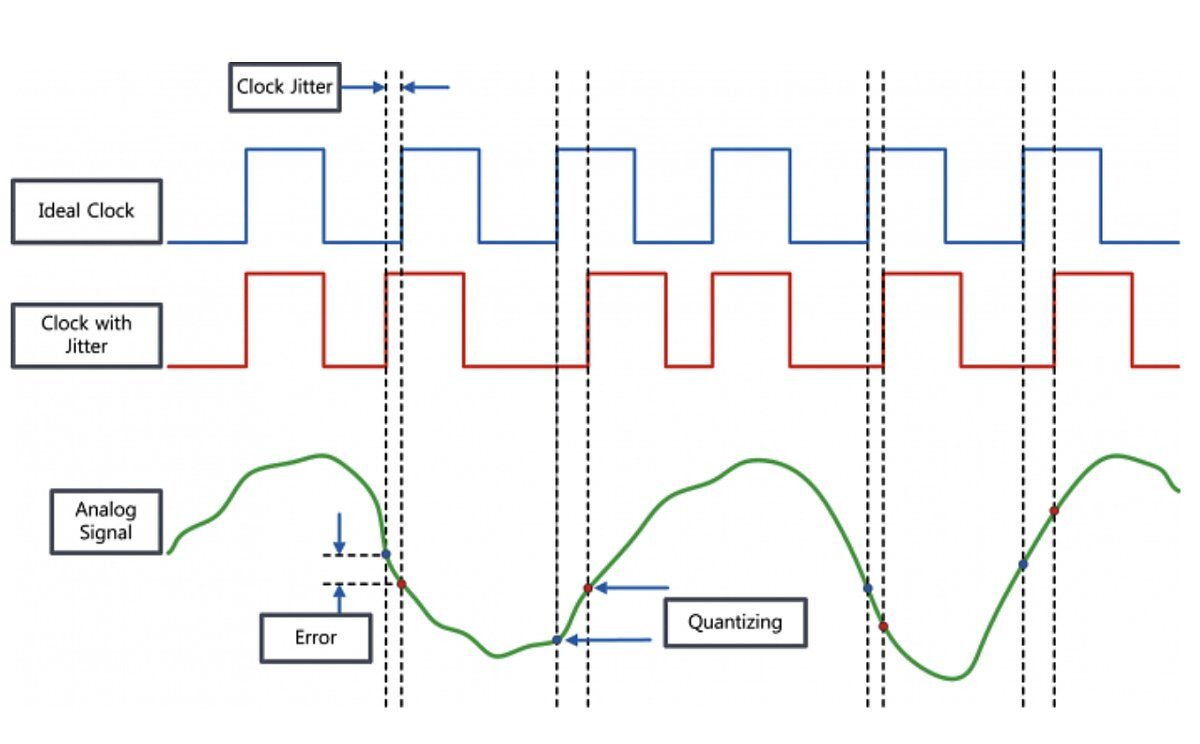
- DA Converter 는 위와 반대 순서
- 원래 음파의 완벽한 소리를 만들 수 없지만 최소화한 것이 “uncompressed” 혹은 ”lossless”
2. Digital Audio(CD, Streaming) :
- 특징 : 내구성(+), noise 해방(+), 긴수명(+), 편리함(+)
- Digital Audio file 은 기존의 Analog 오디오 데이터를 변환해 저장매체에 저장해놓은 것일 뿐.
------------------------------------------------------------------------------
- Audio Codec(Compression-Decompression) : Digital audio로 압축(Coder)하고 압축해제(Decoder)하는 알고리즘. HD코덱을 사용시 높은 품질의 오디오를 제공.
- 협대역 : 좁은 주파수 범위(300~3.4kHz)
ex) AMR(Adaptive Multi-Rate) 음성코덱 - 광대역 : 넓은 주파수 범위(50~7kHz)
ex) AMR_WB(AMR Wideband) 음성 코덱
- 협대역 : 좁은 주파수 범위(300~3.4kHz)
- Audio File Format : 코덱을 활용해 저장하는 오디오 파일의 포맷
ex) WAV(Waveform Audio Format) : 무손실, 무압축
ex) FLAC(Free Lossless Audio Codec) : 무손실, 압축
ex) ALAC(Apple Lossless Audio Codec) : 무손실, 압축
ex) AIFF(Apple Interchange File Format) : 무손실, 무압축
ex) MP3(MPEG-1/MPEG2 Audio Layer-3) : 손실, 압축 - Bandwidth : 결국 오디오품질에 가장 좋은요소로, 업로드 속도가 낮으면 광대역이 아닌 협대역을 사용하기 때문에 "협대역 오디오 코덱"을 사용하게 되므로 품질이 낮아진다.
3. Audio 신호에서 추출한 Feature의 종류
음성 신호를 처리하기 위한 Feature에 대해 살펴보고자합니다.

- Spectrum : 아래와 같이 프레임(frame)을 20ms~40ms로 나누어 FFT를 적용한 결과, 주파수 domain입니다.
** FFT(Fast Fourier Transform) : 신호(Signal)를 주파수(Frequency) 성분으로 변환하는 알고리즘

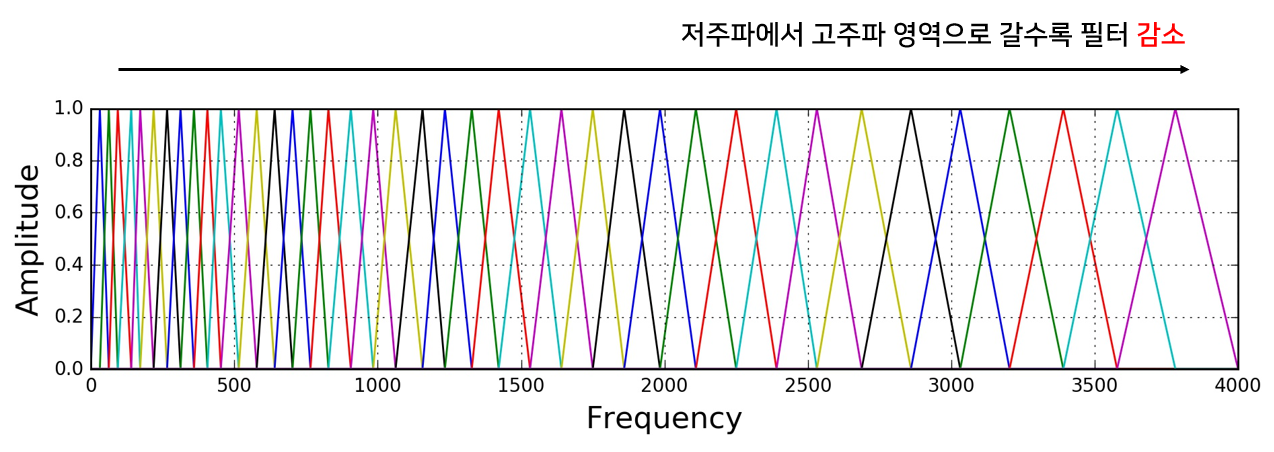
- Mel Spectrum : 사람의 청각기관은 high frequency보다 low frequency에 더 민감하므로, 사람이 인식하는 주파수의 관계(Mel Scale)을 반영해 표현한 것, 아래 그림과 같은 Filter Bank라는 방법을 활용해 표현합니다.
** 인간의 가청주파수(Audible Frequency) : 20~20000Hz
** low frequency : 저음, 저주파, 150~1500Hz, 파장이 길어 멀리 전달 & 회절 잘 됨(장애물 통과)
** high frequency : 고음, 고주파, 3.2kHz
- log스케일로 나타내면 log Mel-Spectrum이라고 할 수 있습니다.
- 연산량이 많지만, specific domain의 학습 데이터에 적합
- MFCc(Mel-Frequency Cepstral coefficients) : Log Mel Spectrum에 Cepstral 분석을 한 결과
- 아래 그림과 같이 Formants를 찾아 Spectral Envelope을 찾고, Inverse FFT를 적용해 시간 domian으로 변경하면 MFCc가 됩니다.
** 포먼트(Formants) : 음파의 주파수 중 피크(peak)로, 신호의 지배적인 주파수 영역을 의미합니다. 포먼트들은 배음을 만나 선명하게 되는 필터 역할을 합니다. - 이 결과로 인해 배음 구조를 유추해, 소리의 고유한 특징을 찾을 수 있습니다.
** 배음(Harmonics) : 기본 주파수의 정수배를 의미하며, 소리는 여러가지의 배음으로 구성됩니다. - 연산량이 적고, general한 학습 데이터에 적합
- 아래 그림과 같이 Formants를 찾아 Spectral Envelope을 찾고, Inverse FFT를 적용해 시간 domian으로 변경하면 MFCc가 됩니다.

- Spectrogram : 소리나 파형을 시각화한 도구, (가로 time, 세로 Frequency, 색깔 amplitude)

b. NLP(Natural Language Processing)
자연어(Natural Language)란 우리가 일상생활에서 사용하는 언어를 의미합니다. 한국어는 "교착어"로, 어근에 접사가 붙어 의미와 문법적 기능이 부여됩니다. 교착어에는 한국어, 중국어, 몽골어 등이 있으며, 이와 다른 예로 어순이 중요시되는 "고립어"인 영어나 중국어와 단어의 형태가 변함으로써 문법적 기능이 정해지는 "굴절어"인 라틴어, 독일어, 러시아어가 있습니다.
자연어 처리(natural language processing)란 이러한 자연어의 의미를 분석해 컴퓨터가 다양한 task를 수행하도록 하는 것인데, 아래와 같은 다양한 task가 있습니다.
- 음성 인식(Speech Recognition)
- 내용 요약(Summarization)
- 번역(Machine Translation)
- 사용자의 감성 분석(Sentiment Analysis)
- 텍스트 분류 작업(스팸 메일 분류, 뉴스 기사 카테고리 분류)
- 질의 응답 시스템(Question Answering)
- 챗봇(Chatbot)
이런 자연어를 처리하는 딥러닝의 일반적인 순서는 아래와 같이 이루어집니다.

텍스트를 전처리(Pre-processing)하기 위해 앞의 두 과정인 Tokenization 혹은 Representation하는 방법에 대해 먼저 살펴보고, Network에 대해 간단히 살펴보겠습니다.
1. Tokenization
Tokenization이란 주어진 Corpus에서 어떤 단위로 나눠 언어를 분석할 지를 결정하는 과정을 의미합니다.
- Word-based : 단어 단위로 쪼개는 것으로, 신조어를 unknown으로 처리하는 OOV(Out-Of-Vocab) 문제가 있습니다. 또한 vocab에 많은 단어를 넣으면 가능한 복합수가 너무 많기 때문에 많은 메모리를 요구하고, vocab에 단어가 적으면 성능이 떨어집니다.
- Character-based : 글자 단위로 쪼개는 것으로(한국어로는 초성 중성 종성, 혹은 음절), 문장의 길이 자체가 길어지기 때문에 vanishing gradient가 발생하거나 학습이 어렵습니다(sequence가 길어질수록 성능이 떨어집니다). word-based에 비해 필요한 vocab의 수가 줄어들기는 하지만 (영어의 경우 영어 문자 26개+특수문자) 너무 단위가 작아 정보를 담기 어렵습니다.
- Subword-based : Character-based과 Word-based의 중간으로 character-based에 비해서는 sequence가 짧아 성능이 좋지만 word-based에 비해서는 단어가 쪼개져 복합수가 적어질 수 있으며, OOV문제를 해결할 수 있습니다.
- Byte Pair Encoding(BPE) : 통계학적 방법이며 GPT에서 활용되었습니다.
- Unigram Language Modeling : BPE와 같이 pre-tokenized 된 것을 활용해 모든 단어의 substring들을 만들고 trim해내 가는 방법입니다.
- Word Piece : vocab을 추가한 뒤, merge할지를 likelihood를 최대화하는 방향으로 결정하는 방법입니다. Bert, DistillBert, Electra에 활용되었습니다.
- Sentence Piece : 새로운 알고리즘이라기 보다는 pre-tokenization없이 기존에 존재하던 unigram, BPE와 같은 tokenizer들을 모든 언어에 대해 적용이 가능하도록 일반화하고 개선해 만든 tokenizer입니다. ALBert, XLNet, T5에서 활용되었습니다.
----------------------------------------------------------------------------
<Subword-based 예시>
1. N-gram Model
기존의 전통적인 SLM(Statistical Language Model)은 전체 corpus 내의 단어를 count하는 접근을 사용하므로, “문장이 길어질 수록” 확률을 계산하고 싶은 문장이나 단어가 담기지 않을 수도 있습니다. 따라서 짧은 시퀀스의 일부 주변 단어만을 참고해 만든 모델이 N-gram입니다. 이 때 몇개의 단어를 참조할지에 따라 N이 달라집니다.
- unigrams : an, adorable, little, boy, is, spreading, smiles
- bigrams : an adorable, adorable little, little boy, boy is, is spreading, spreading smiles
- trigrams : an adorable little, adorable little boy, little boy is, boy is spreading, is spreading smiles
- 4-grams : an adorable little boy, adorable little boy is, little boy is spreading, boy is spreading smiles
하지만 여전히 모든 단어가 담기도록 확률을 높일 수는 없기에 Sparsity Problem이 존재합니다. n이 클수록 sparsity problem이 커지는 문제가 있고, n이 낮으면 현실 분포와 멀어지는 문제가 있으므로 trade-off가 존재합니다.
2. Byte Pair Encoding(BPE)
원래 정보압축에 쓰이던 것으로, 1994년부터 Language에 쓰였던 알고리즘입니다. 빈도가 많을 수록 단어가 merge.txt가 바뀌므로 어떤 데이터로 만들지가 중요합니다.
예를 하나 보이겠습니다. hug, pug, pun, bun, hugs라는 단어를 가지고 BPE를 동작하겠습니다.
①. pre-tokenizing : 아래 표가 결과입니다.
** 영어 : 빈칸으로 쪼개는 것을 주로 활용합니다.
** 한글 : 형태소로 쪼개는 것을 주로 활용합니다.
| word | # |
| hug | 10 |
| pug | 25 |
| pun | 12 |
| bun | 4 |
| hugs | 5 |
②. initial vocab : [h,u,g,p,n,b,s] 가 있습니다.
③. bigram 으로 세서 가장 많이 나온 것 선택
– h+u : 15, u+g : 12, …
④. merge.txt에 포함시키기 : [hu], [ug]...
⑤. ③, ④ 반복 : 원하는 vocab size가 되면 stop (보통 32000개면 충분)
⑥ 결과
- Initial vocab : [h,u,g,p,n,b,s,hu,ug,hug, …<unk>]
- Merge.txt : [hu, ug, hug …]
⑦ pug, bug, mug 인풋이 들어온다면?
- merge.txt를 앞에서 순서대로 보고 해당 인풋들을 뭉치기 : [p,ug],[b,ug],[m,ug]
- initial vocab을 보고 labeling 하기 : [3,7], [5,7],…
----------------------------------------------------------------------------
----------------------------------------------------------------------------
<Special Token의 종류>
Out Of Vocab : 단어가 없다는 뜻의 토큰 ex) <oov>
Begin Of Sentence : 문장의 시작 토큰 ex) <sos>, <bos>, <s>
End Of Sentence : 문장의 끝 토큰 ex) <eos>, </s>
Unknown : 알 수 없는 단어를 포괄하는 토큰 ex) <unk>
----------------------------------------------------------------------------
Tokenization 라이브러리는 여러가지가 있습니다. 관련 글(https://tkayyoo.tistory.com/160)을 참조하세요.
2. Language Representation
위와 같은 Tokenization을 통해 결정된 단위를 컴퓨터가 효율적으로 처리하게 하기 위해 수치화하는 방법입니다. 표현하는 방법에 따라 성능이 많이 달라지기 때문에 다양한 많은 방법이 있습니다.
이렇게 표현된 Representation 벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되는 방법을 sparse representation이라고 하며, 이와 반대로 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞추는 것을 dense representation(혹은 word embedding)이라고 합니다.
또한 표현을 하려고 할 때 해당 단어 그 자체만 보고 단어를 표현하는 방법을 local representation(혹은 discrete representation)이라고 하며, 그 단어를 표현하고자 주변을 참고하여 단어를 표현하는 방법을 continuous distribution(혹은 distributed distribution) 이라고 합니다.

2-a. One-hot vector (Sparse Representation) + RNN/LSTM
- 해당 단어의 인덱스만 1로 표현하는 방법입니다. Sparse Vector이기 때문에 Sparse Representation이라고 합니다.
ex) Cat : [1,0,0,0,0,0…], Dog : [0,1,0,0,0,0…] - 문제점 : 단어의 개수가 많아 짐에 따라 한없이 차원이 커지는 문제가 있으며, 비슷한 vector같의 유사성을 표현할 방법이 없다는 문제가 있습니다.
ex) 위 Cat과 Dog 간의 cos-similarity(inner-dot product)는 0입니다.
2-b. 빈도 표현 : Count 기반
- 자연어 처리를 할 때, 단어가 몇번 나타나는 지를 표현하는 방법입니다.
ex) BoW(Bag of Words), DTM(Document-Term Matrix), TDM(Term-Document Matrix), TF-IDF(Term Frequency-Inverse Document Frequency) - 예시1. BoW : 순서와 상관없이 출현 빈도만 가지고 표현하는 방법입니다.
ex) Vocab : {Cat:0, Dog:1, is:2, ...}, BoW : [1, 1, 5, ...] - 예시2. DTM : BoW의 확장이며, 문서가 여러개 있을 때 문서마다의 단어들의 빈도를 행렬로 표현한 방법입니다.
- 예시3. TF-IDF : TF(특정 문서에서 특정 단어 t의 등장 횟수)와 IDF("특정 단어 t가 등장한 문서의 수"의 역수)를 곱한 값을 의미합니다. 즉, 특정 문서에서만 자주 등장하는 단어는 그 문서내에서만 중요하므로, 이를 반영하는 방법입니다.
2-c. 밀도 표현 (Dense Representation) : Density 기반
- 사용자가 설정한 차원으로 벡터 표현을 맞춰 실수 값을 가지는 함으로써, Sparse Representation과 다르게 “근처에 있으면 닮은 표현이다"라는 것을 반영한 방법입니다. 이로 인해 차원문제를 해결한 방법이지만, 요즘은 많이 사용하지는 않습니다.
ex) I = [0.1, 0.2, 0.3], love = [0.2, 0.1, 0.2], you = [0.2, 0.3, 0.6]
ex) Word2Vec, FastText 방법 - 예시. Word2vec (dense representation) + RNN/LSTM
- 먼저 랜덤 값을 통해 초기화 한 이후에, 모델 학습 전에 pre-training 합니다.
ex) CBOW(Continuous Bag of Words), Skip-Gram - Word2vec 학습방식 의 예 : CBOW
- sliding window를 활용해 중심 단어(center word)의 주변 단어(context word)를 반영하는 방법입니다. 즉, 아래 그림과 같이 One-Hot벡터를 M 차원을 갖는 표현으로 변경 하는 방법입니다.
- 아래 그림은 The fat cat sat on the mat 이라는 문장이 있고 window size가 1일 때, sat주변에 cat과 on이 붙어 있으므로, 아래와 같이 W와 W' 두가지를 학습합니다.
- 먼저 랜덤 값을 통해 초기화 한 이후에, 모델 학습 전에 pre-training 합니다.

2-d. 빈도와 밀도의 중간 : Glove + RNN/LSTM
앞서 언급한 빈도 표현과 밀도 표현을 복합적으로 사용하는 방법입니다.
2-e. Contextual Representation
사전에 훈련된 Pre-trained 모델을 활용해 표현하는 방법입니다. 기존에 Word2Vec(2-c)나 Glove(2-d)의 경우 서로 다른 문맥에서의 단어의 의미가 바뀌는 것들을 "문맥에 따라서 다르게" 임베딩할 수 있도록 표현하는 방법입니다.
기본적으로 컨셉은 사전에 훈련된 "언어모델"을 활용하자는 컨셉이므로 LM을 학습하는 구조로 진행되는 것이 많으며, 현재 사용하는 LM들은 대부분 Contextual Representation을 활용합니다.
** LM(Language Model, 언어모델) : 확률을 통해 문장의 적절성을 판단하는 것으로, 이 확률을 기반으로 다음 단어의 등장 확률의 순위를 알 수 있고 따라서 다음단어가 어떤 것일지 예측할 수도 있습니다. 통계학적 언어모델과 인공신경망 기반의 언어모델이 있습니다.
- 예시1. ELMO(Embeddings from LM) : Bi-LSTM을 활용해 앞에 나온 단어들을 참조해 다음 나올 단어를 예측합니다.
- 예시2. BERT : Transformer를 활용하며, masking을 활용해 masking된 단어를 예측합니다. 따라서 Masked LM(MLM)이라고 부르기도 합니다.
** BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
3. Network
자세히는 설명이 길어지기 때문에 가장 중요한 Attention까지의 등장과정을 설명하겠습니다.
- Seq2Seq
- Sequence to Sequence Learning with Neural Networks(‘14)
- 기계 번역 task를 진행하기 위해, 고정된 차원의 input/out sequence를 가지는 DNN의 한계를 극복하기 위한 논문입니다.
- Sequence를 받는 Encoder와 Sequence를 출력하는 Decoder로 분리한 특징을 가집니다. 그리고 둘 사이에는 고고정된 크기의 context vector가 있습니다.
- auto-regressive하게 동작합니다.
** AR(Auto-Regressive, 자기회귀) : 이전 입력의 결과를 가져와 다음 입력으로 사용하는 것을 반복
** AE(Auto-Encoder) : 입력 데이터를 일종의 정답으로 삼아 학습하는 Unsupervised Learning 기법 - (-) 고정된 크기의 context벡터에 압축하다보니, 문장이 길어질 수록 context vector의 정보가 손실 되며(bottleneck), gradient vanishing/exploding 현상이 발생합니다.
- Attention Mechanism
- Neural Machine Translation by Jointly Learning to Align and Translate(‘15)
- 기계 번역 task로, Context vector의 bottleneck을 막기 위해 encoder의 매시점 은닉 상태(hidden state)들을 모두 사용하자는 방법입니다.
- 기존에 Seq2Seq에 attention 메커니즘를 더한 방법입니다. Attention Score를 얻어 이들을 모은 Attention Distribution 및 이들을 weighted sum한 Attention Value를 구하고 t시점의 decoder 입력과 함께 t시점의 state를 구해냅니다.
** Attention Score : Score function을 통해 구한 t시점의 encoder state와 decoder의 t-1시점 hidden state간의 유사도
** Score function : 다양한 방법을 통해 attention score를 구할 수 있습니다. - RNN 구조를 활용하기 때문에 병렬화가 불가능하며, 멀리있는 항목간의 관계성을 학습하기 어려운 문제(Long Distance Dependency)가 있습니다.
- Transformer
- Attention is All you need(‘17)
- RNN구조를 사용하지 않고, Positional Encoding을 활용한 attention으로 병렬문제와 Long Distance Dependency를 해결했습니다.
c. ASR(Automatic Speech Recognition)
음성인식의 개괄에 대해 설명하겠습니다. 전체적인 과정은 아래와 같을 것입니다.

음성인식의 경우 결국 어떤 Audio가 들어왔을 때 이에 일치하는 Word를 도출해내는 것이 목표입니다. 이 것은 Bayes Rule을 활용해 표현해보면 아래와 같을 것입니다.
아래 식과 같이 결국 우리의 목표는 "어떤 Audio가 들어왔을 때 이에 일치하는 Word일 확률" p(W|O)을 찾는 것이 목표일 것입니다. 하지만 이를 직접 구하기는 힘드므로, "어떤 Word가 Audio형태를 가질 확률" p(O|W)과 "어떤 Word를 가질 확률" p(W)를 합쳐 만들어내게 됩니다.

-------------------------------------------------------------------------
<ASR 개괄>
ASR의 과거부터 현재까지 다양한 역사를 이해할 필요가 있기도 합니다. 따라서 ASR의 역사를 간단히 한눈에 알아볼 수 있게 정리 해보았습니다.
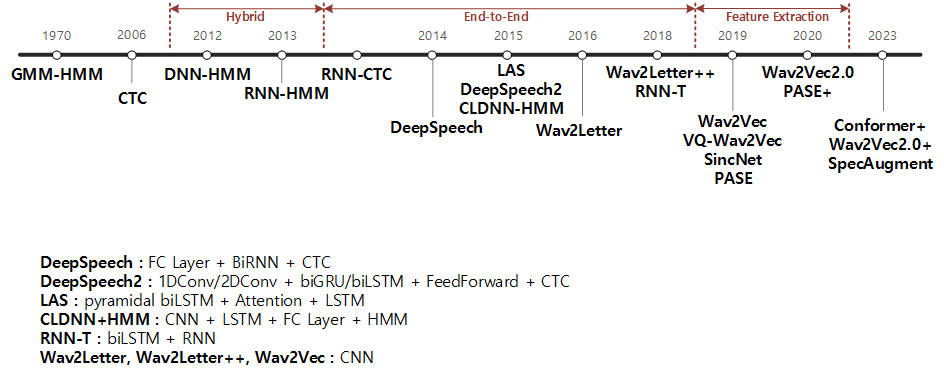
-------------------------------------------------------------------------
이외에도 Error Rate(https://tkayyoo.tistory.com/166)에 대한 개념과 Decoding(https://tkayyoo.tistory.com/164)에 대한 자세한 개념을 알면 좋으나 관련 페이지로 대체하겠습니다.
d. ASR 모델의 예시
ASR모델을 크게 분류하면 전통적인 GMM-HMM 모델(Hybrid ASR System, Integrated Search)과 E2E(End-To-End) 모델로 나눌 수 있습니다.
GNN-HMM모델은 Acoustic 모델과 Pronunciation Model(Lexicon), 그리고 LM(Language Model)을 각각의 따로 최적화를 하게되며, 이들을 WFST(Weighted Finite-State Transducer)로 함께 Decoding 하는 구조 입니다. 하지만 이들은 세개의 모델이 각각 서로 다른 목적을 가지고 따로 학습된다는 문제를 가지고 있습니다.
-----------------------------------------------------------------------
<GMM-HMM에 대해서>
기존의 전통적인 GMM-HMM 모델에 대해 설명하고자 합니다.
1. GMM (Gaussian Mixture Model)
GMM은 다수 개의 서로 다른 정규분포의 가중 합으로 어떤 모델을 표현한 것입니다. 기존에 음성의 특징을 모델링하기 위해서 GMM을 활용했다고 합니다.
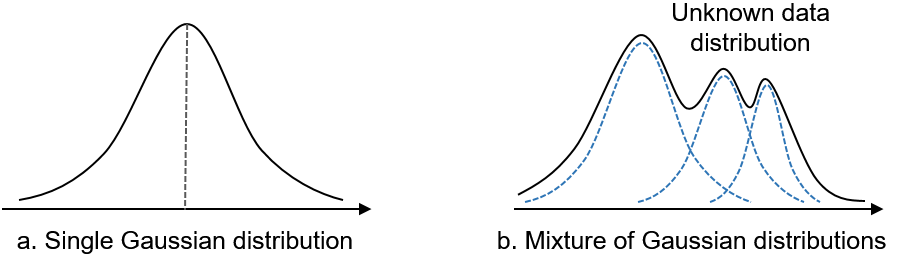
2. HMM (Hidden Markov Model)
HMM을 설명하기 위해 아래와 같은 상황을 가정합니다.
어떤 HMM Model λ에 대해 아래에서 관측할 수 있는 것은 Observation O뿐인데, Observation의 내부에는 State가 은닉(Hidden) 되어있고, 각각의 State들은 Markov Chain을 따르고 있을 것이라는 가정에서 시작합니다.

이때 두가지 전이 확률(Transition Probability)와 방출 확률(Emission Probability)는 아래와 같습니다.
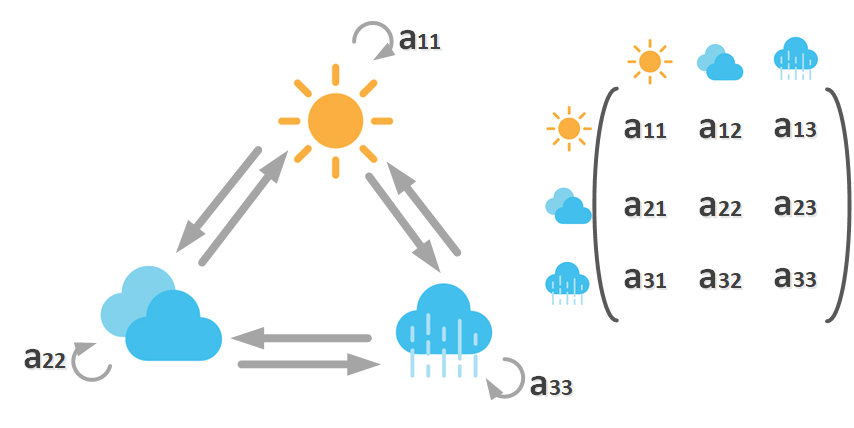
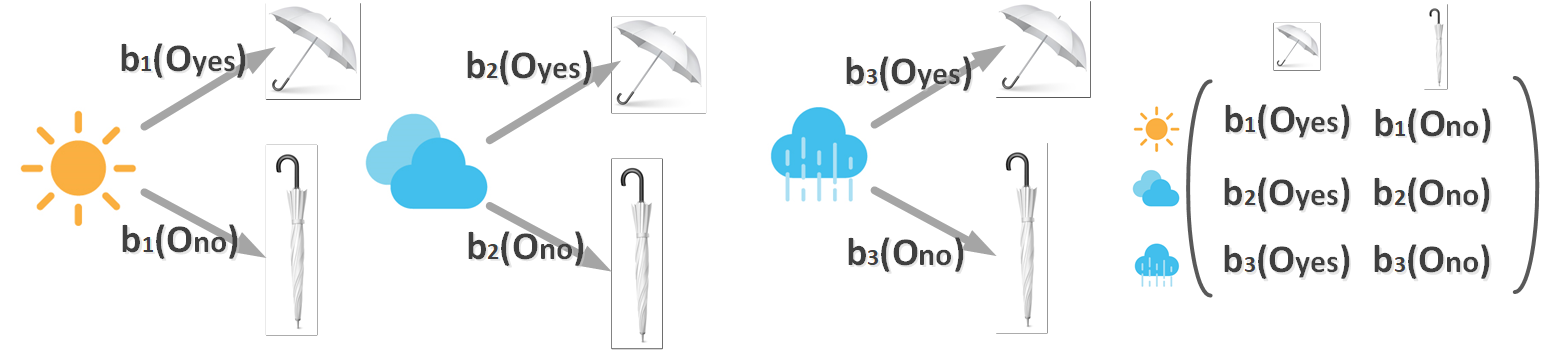
자 그럼 다시 돌아와서 관측치 O가 있을 때, 어떤 모델 λ에서 왔을 likelihood인 P(O|λ)는 어떻게 구할 수 있을까요? 방법은 forward algorithm과 backward algorithm이 있습니다.
먼저 아래와 같은 상황에서,시간 t=2에서 state1일 forward probability α를 구해보겠습니다.
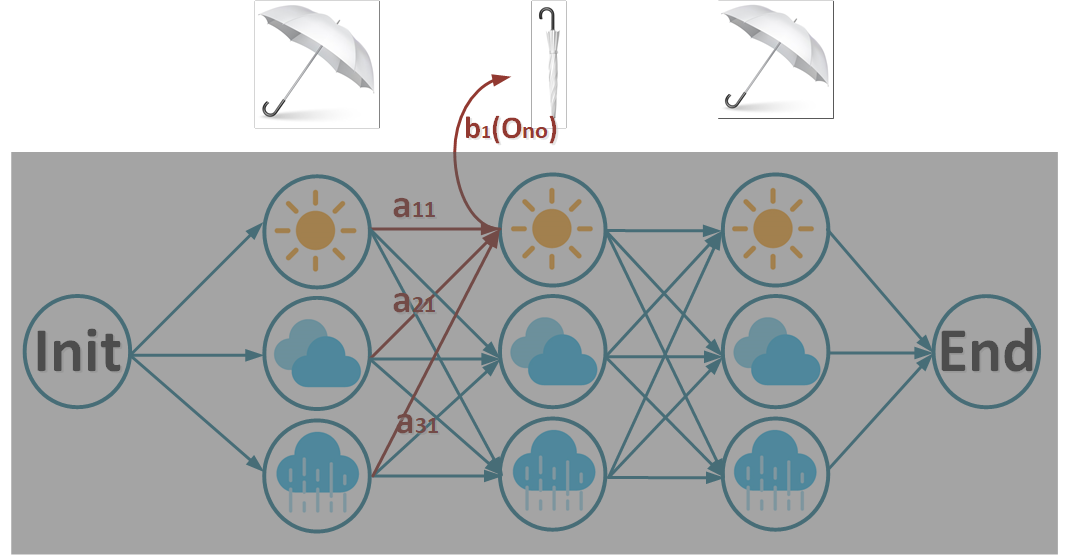
위 그림을 수식화 하면 forward probability α는 아래와 같습니다.
이런 forward probability를 구하는 forward algorithm을 활용해 구하는 likelihood P(O|λ)는 아래와 같습니다.
$$P(O|\lambda )= \alpha _3(1)+\alpha _3(2)+\alpha _3(3)$$
반대로 backward probability β를 구하는 backward algorithm은 아래와 같습니다.
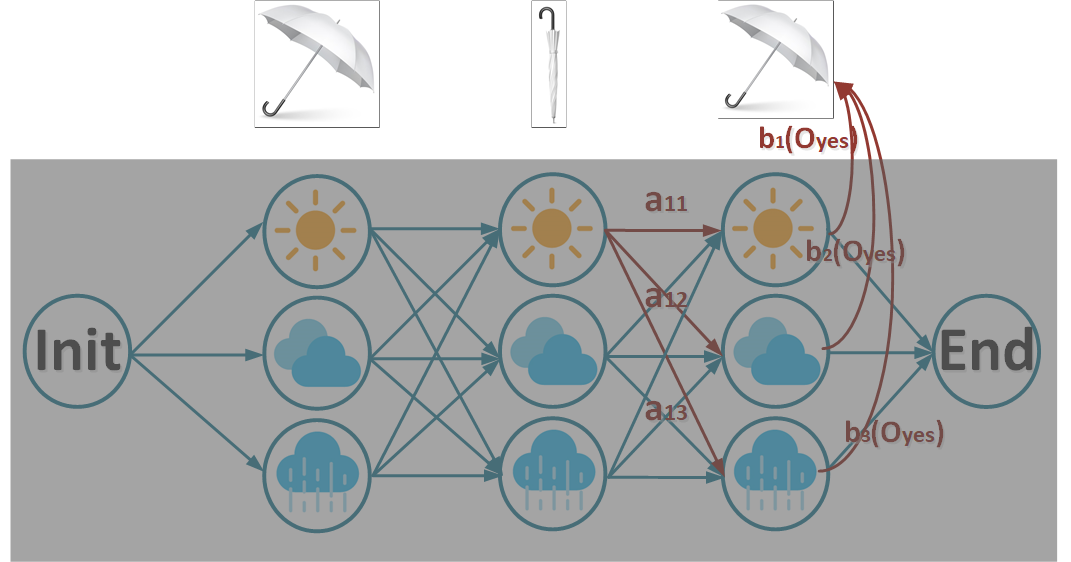
수식은 아래와 같습니다.
$$\begin{matrix}
\alpha _2(1)& = & \alpha _1(1)\times a_{11}\times b_1(O_{no}) +\\
& & \alpha _1(2)\times a_{21}\times b_1(O_{no}) +\\
& & \alpha _1(3)\times a_{31}\times b_1(O_{no}) \\
P(O_{no}|t=2,\lambda )& =& \alpha _2(1)+\alpha _2(2)+\alpha _2(3) \\
\end{matrix} $$
자 이제 어떤 Observation일 때의 확률을 구하는 방법을 알았으니, 어떤 Observation일 때의 hidden state 중 가장 가능성이 높은 path를 찾는 방법(Decoding)은 어떻게 하면 좋을까요?
위 forward 알고리즘과 비슷하지만, 전부 다 더하는 forward probability α 가 아니라 해당 state 중 가장 확률 viterbi probability v를 저장해 구하는 viterbi algorithm을 활용합니다. 일종의 Dynamic Programming이며, path backtracking이라고 부르기도 합니다.
$$\begin{matrix}
v_2(1)&=&max(v_1(1)\times a_{11}\times b_1(O_{no}),\\
& & v_1(2)\times a_{21}\times b_1(O_{no}),\\
& & v_1(3)\times a_{31}\times b_1(O_{no}))\\
\end{matrix} $$
마지막으로, 어떤 Observation들이 있지만 전이확률과 방출확률을 모르는 상황에는 어떻게 찾을 수 있을까요? EM(Expectation Maximization) 알고리즘 중에 하나인 Baum Welch Algorithm을 활용합니다. 간단히 설명하면, 아래와 같습니다.
- Expectation Step : 전이확률과 방출확률을 고정하고, 업데이트 량을 구합니다.
- Maximization Step : 업데이트 량을 반영해 전이확률과 방출확률을 업데이트하고, 전이확률과 방출확률이 수렴할 때까지 진행합니다.
이런 HMM을 구성할 때의 방출확률을 GMM으로 한다면 GMM-HMM이며, DNN으로 한다면 DNN-HMM입니다.
-----------------------------------------------------------------------
따라서 이런 disjoint한 학습 법을 개선하기 위해 등장한 것이 E2E모델이며, 이들은 크게 두가지로 분류해 볼 수 있습니다.
- Neural Transducer
- RNNT(RNN-Transducer)
- Sequence Transduction with RNN (ICML’12)
- Transformer-Transducer
- Transformer Transducer : e2e speech recognition with self-attention (arxiv’19)
- Transformer Transducer : a streamable speech recognition model with transformer encoders and RNN-T loss (ICASSP’20)
- RNNT(RNN-Transducer)
- AED(Attention-based Encoder-Decoder)
- Attention-based models for speech recognition (NIPS’15)
- Neural Machine Translation by jointly learning to align and translate (ICLR’15)
- Listen, Attend, and Spell : A NN for large vocabulary conversational speech recognition (ICASSP’16)
Neural Transducer구조는 Encoder, Predictor, Joint 네트워크로 구성되어있으며, Input의 time차원을 Encoder의 time차원에 대응시켜 Decoding을 진행할 수 있습니다. 따라서 매시간 들어오는 오디오 데이터를 처리할 수 있는 streamable 특성을 가지고 있다고 볼 수 있습니다.
하지만, predictor 네트워크가 internal LM과 같이 보일 수 있으나 acoustic encoder에 조화롭게 학습되기 때문에 LM 기능을 한다고 보기는 힘듭니다. 따라서 text만으로 학습한 LM을 효율적으로 활용할 LM Adaption기법이 필요한데, 아래와 같은 다양한 방법들이 제안되기도 했습니다.
- FNT : Acoustic 모델 내부에 standalone LM모델을 학습시키는 구조를 채용하는 것
- FACTORIZED NEURAL TRANSDUCER FOR EFFICIENT LANGUAGE MODEL ADAPTATION (arxiv'21)
- FAST AND ACCURATE FACTORIZED NEURAL TRANSDUCER FOR TEXT ADAPTION OF END-TO-END SPEECH RECOGNITION MODELS(arxiv'23)
- External Language Model Integration for Factorized Neural Transducers(arxiv'23)
- TTS(Text-To-Speech) : 타겟 도메인의 텍스트를 활용해 오디오를 합성하는 방법. 연산량이 너무 많기 때문에 빠른 adaption이 필요한 경우에 단점이 있습니다
- LM fusion : 외부 LM을 target 도메인 텍스트에 학습시킨 후 shallow fusion이나 density ratio based integration을 활용해 합치는 방법. 하지만 fusion에 필요한 weight가 task 의존적이기 때문에 human-tune이 필요한 단점이 있습니다.
- Rescoring & Reranking: 디코딩 이후에 외부 LM을 활용해 score를 업데이트하고 n-best 혹은 lattice 결과를 reranking하는 방법입니다.
** decoding 후보를 만드는 방법에는 lattice(격자) 구조를 활용하거나 n-best tree를 만드는 방법이 있습니다.

반면, AED구조는 Encoder와 Decoder로 구성되어 있으며, 성능이 굉장히 좋은 반면 Input이 bidirectional-RNN형태로 Encoder를 통과하기 때문에 차원이 구분이 되지 않아 streamable하지 않습니다. 다만 이런 단점을 극복하기 위해 아래 방법을 활용해 극복하는 방법도 제안되었습니다.
** unidirectional-RNN을 사용하면 가능하겠지만, 성능이 떨어지겠죠..?
- Chunk-wise Attention
Monotonic chunkwise attention (ICLR'18) - Tiggered Attention
Triggered attention for end-to-end speech recognition (ICASSP'19)
Reducing the latency of end- to-end streaming speech recognition models with a scout net- work (Interspeech'20)
이번 글에서 설명할 LAS는 바로 이 AES구조의 E2E모델의 시초입니다.
1. Problem
논문에서 제기하는 문제점에 대해 먼저 짚고 넘어가겠습니다.
a. Traditional DNN-HMM
기존 전통적인 DNN-HMM은 Acoustic Model, Acoustic Model, Pronunciation Model이 분리되어 학습되어, 이런 disjoint한 학습을 개선하기 위해 CTC와 seq2seq방법이 제안되었습니다. 각자의 특징과 문제점에 대해 살펴보겠습니다.
CTC(Connectionist Temporal Classification)은 input 음성 frame sequence와 타겟 단어 sequence 간의 alignment 정보가 없을 때, DP(Dynamic Programming) 알고리즘을 활용해 RNN을 위한 새로운 cost function을 제안한 논문입니다. Blank Symbol을 추가하고 alignment를 DP알고리즘을 찾으므로, input의 unsegmented data의 sequence를 예측하는 Sequence Learning Task을 가능하게 할 수 있습니다.
** Unsegment Data : input 음성의 frame당 무슨 음운 인지 모르지만, 최종적인 전체 label인 단어 sequence는 아는 상태를 의미합니다. 즉, 단어들이 어디에 매칭되는지 segment되지 않은 상태의 데이터입니다.
** unsegmented data를 라벨링하는 task 를 sequence learning 혹은 sequence labeling이라고 합니다.
하지만, CTC는 생성되는 단어 사이의 conditionally independence 가정이 있는 단점이 있습니다. 즉, encoder에 decoder 없이 학습하기 때문에 RNNT나 LAS와 같이 autoregressive하게 이전 결과에 dependent하게 결과가 나오지는 않습니다.
** [10] CTC : Connectionist Temporal Classification : Labelling Unsegmented Sequence Data with RNN (ICLR’06)
seq2seq는 가변 길이 sequence를 input으로 받아 가변 길이 sequence를 output으로 하기 위한 방법 중 하나 입니다.
이전에는 이 문제를 해결하기 위해 RNN과 다른 sequential 모델과의 결합을 통해 문제를 해결했는데, 그 것이 HMM과 CRF입니다. 하지만 이들은 end-to-end로 쉽게 학습이 불가능하고, 단어 간의 독립성 등의 가정이 필요하다는 단점이 있었습니다.
** [22] HMM : Statistical Inference for Probabilistic Functions of Finite State Markov Chains (’66)
** [23] CRF : Conditional Random Fields : Probabilistic Models for Segmenting and Labeling Sequence Data (ICML’01)
---------------------------------------------------
<CRF(Conditional Random Field)란?>
CRF는 통계적 모델링 방법 중 하나로, ”조건부 무작위 장"이라는 뜻이며 Softmax regression 의 일종입니다.
** Softmax regression : logistic regression 의 일반화버전으로, 클래스가 2보다 많은 n개일 때, n개의 대표벡터를 학습하는 것입니다.
이웃하는 표본들을 고려하여 예측하는 방법으로, potential functions(혹은 feature function)의 결과를 softmax regression 통해 얻어내는 과정입니다. 이 때 potention function은 현재 '해당 데이터 전체'와 인덱스, 그리고 '현재와 이전 관측값'을 활용해 정보 벡터를 얻어내는 것입니다.
HMM과 비교하면 아래와 같습니다.
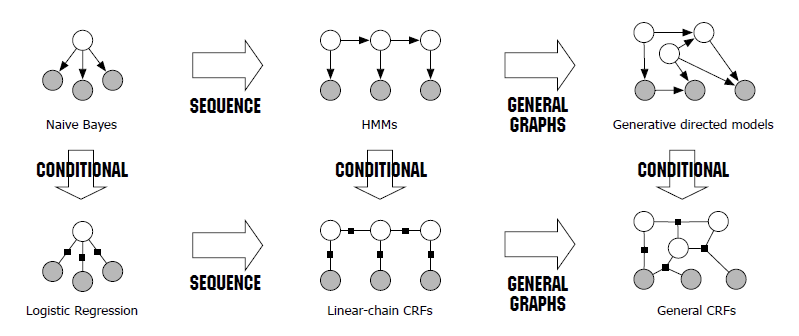
자세한 설명은 사용되는 task로 나눠 살펴보겠습니다.
1. Sequence Labeling
Sequence Labeling을 수행할 때, 다양한 상호작용 특징이 존재하는 경우나 관측값에서 긴범위의 의존성이 발견되는 경우, 이들 모델에 대한 추론이 다루기 힘든(intractable) 문제가 되어버린다는 단점이 있습니다. 이에 CRF는 관측 시퀀스의 독립적이지 않은 특징들을 고려해 레이블 사이의 의존성을 고려할 수 있습니다.
보통 LSTM + CRF 모델을 많이 활용하는데, 이전에 독자적으로 존재해왔던 CRF를 bi-LSTM 모델 위에 하나의 층으로 추가하여 활용하는 것입니다. CRF 층은 LSTM의 결과인 Label Sequence에 대해서 가장 높은 점수를 가지는 시퀀스를 예측하는 레이어입니다.
input sequence x에 대한 output sequence y의 수식은 아래와 같습니다.
$$P(y|x)=\frac{exp(\sum^m_{j=1}\sum^{n}_{i=1}\lambda _jf_j(x,i,y_i,y_{i-1}))}{\sum _{y'}exp(\sum^m_{j=1}\sum^{n}_{i=1}\lambda _jf_j(x,i,y'_i,y'_{i-1}))}$$
위에 말씀드린 것과 같이 potention function을 활용하며, j 번째 potential function과 그에 대응하는 weight lambda는 n 개의 단어열을 high dimensional sparse vector로 표현하는데 사용됩니다. 이는 m차원의 sparse vector에 대해 모두 수행합니다.
2. Segmentation
DeepLab : Semantic Image Segmentation With Deep Convolutional Nets And Fully Connected CRF (arxiv'14)
위 논문에서는 DCNN이 spatial invariance(spatial insensitivity)라는 특징을 가지고 있어 classification 문제에 뛰어나지만 정확한 위치를 필요로 하는 segmentation에서는 한계가 있다고 합니다.
** spatial invariance : 물체의 방향, 위치와 같은 상태가 변해도 그 물체를 인식할 수 있는 불변성
따라서 전체 픽셀을 모두 연결한 fully connected CRF 방법으로 이를 극복하는데 수식은 아래와 같습니다. Image input x에 대해서 픽셀 i,j를 고려한 수식은 아래와 같습니다.
$$E(x)=\sum _i\theta _i(x_i)+\sum _{ij}(x_i,x_j)$$
위 식 중 첫번째 Term은 DCNN의 segmentation label 확률인 Unary Term이며, 두번째 Term은 픽셀 간의 디테일한 예측을 하는 Pairwise Term입니다.
이중 Pairwise Term은 아래와 같이 두개의 gaussian kernel을 활용해 구해냅니다. 이때 두개의 gaussian kernel은 아래와 같은데, 픽셀의 위치(position) p와 픽셀의 컬러값(intensity) I를 활용해 구해냅니다.
$$w_1exp(-\frac{|p_i-p_j|^2}{2{\sigma _\alpha }^2}--\frac{|I_i-I_j|^2}{2{\sigma _\beta }^2}) +w_2exp(-\frac{|p_i-p_j|^2}{2{\sigma _\gamma }^2})$$
---------------------------------------------------
그래서 등장한 것이 seq2seq입니다. seq2seq는 input을 고정길이의 벡터로 매핑하는 encoder RNN과 해당 벡터를 가변길이 sequence로 생성하는 decoder RNN으로 이루어져 있었습니다. 학습시에는 GT를 decoder의 input을 넣어주지만, inference시에는 beam search를 통해 적절한 후보를 step별로 생성합니다. 하지만 이는 encoder의 정보를 단 한번에 전달합니다.
** [17] Sequence to Sequence Learning with Neural Networks (NIPS’14)
따라서 [16]에서는 attention mechanism을 활용해 이를 해결합니다. encoder의 input sequence에 대해 attention vector를 활용해 어떤 정보에 집중할지를 파악하고, 해당 attention vector와 decoder의 마지막 hidden state를 활용해 매 time step마다 output 토큰을 만들기 때문에, 이전과 다르게 encoder의 정보를 decoder에 time step에 맞춰 전달 할 수 있었습니다.
** [16] Neural Machine Translation by jointly learning to align and translate (ICLR’15)
이런 seq2seq 프레임워크는 아래와 같은 많은 응용 분야에 쓰였는데, 이런 기법에 근간해 speech recognition에 적용한 것이 바로 이 논문인 LAS입니다.
- machine translation
- image captioning
- parsing
- conversational modeling
LAS는 HMM에 의존하지 않으며, CTC와 같이 label sequence의 indenpendence 가정이 없다는 장점이 있습니다.
2. Approach
이 논문의 가장 큰 기여도에 맞게 Encoder에 해당하는 Listner와 Decoder에 해당하는 Speller를 jointly하게 학습할 수 있습니다. Listener는 Listen()함수를 수행하며, Speller는 AttendAndSpell()함수를 수행합니다.
먼저 Listen()은 Pyramidal RNN(Bidirectional-LSTM)로 구성되어 있으며, in/out은 low-level speech 시그널이라고 할 수 있는 Filter Bank Spectra를 받아 high-level features를 얻어 냅니다. 또한 key role은 time step 길이의 고차원 데이터를 저차원으로 줄여주는 역할을 하고 있습니다.
다음으로 AttendAndSpell()은 Attention-based RNN으로 구성되어 있으며, in/out은 앞서 encoder에서 나온 high-level features를 받아 Characters Utterances들을 뱉어 냅니다. 즉, 문자 sequence들에 대한 확률분포를 명시해줍니다. 또한 key role은 "문자"로 뱉어주는 것이라고 할 수 있는데, 이 특징은 아래와 같은 장점을 가지고 있습니다.
- 기존 DNN-HMM과 다르게 문자 자체로 뱉어주기 때문에 rare words 문제나 OOV(Out-Of-Vocabulary)문제를 해결할 수 있습니다.
- 음성에 따라 다양한 spelling이 가능한 것들을 자연스럽게 생성할 수 있습니다. 이것은 conditional independence을 가정하는 기존의 CTC에서는 불가능합니다.
ex) triple a > “aaa”, “triple a”
아래는 LAS의 전체 구조 입니다.

그림 내의 notation에 대해서 먼저 정리하겠습니다.
1. Input
filter bank spectra features인 input sequence 입니다.
$$x = (x_1, ..., x_T)$$
2. Output
character의 sequence 입니다.
$$y = (<s>, y_1, ... y_S, ,</s>)$$
내부적으로 들어가는 y_i값에 대해서는 아래오 ㅏ같은 다양한 문자들이 가능합니다.
$$y_i \in \begin{Bmatrix}
a,b,c,...z,0,...9,<space>,<comma>,<period>,<apostrophe>, <unk>
\end{Bmatrix}$$
3. Model
결국 input x에 대한 y의 probability distribution을 구해내는 것이 목표인데, 해당 index i 이전까지의 문자와 input에 dependent하게 결과를 도출하므로 아래와 같이 표현할 수 있습니다.
$$P(y|x)=\prod_iP(y_i|x,y<i)$$
조금 자세히 살펴보겠습니다. Listen()함수를 통해 encoder는 정보를 얻어낼 것이고 이를 h라고 표현해보겠습니다.
$$h = Listen(x)$$
이때 나온 feature인 h는 아래와 같습니다.
$$h=(h_1, ...h_U)\ when\ U\ \leq\ T$$
이렇게 얻은 encoder의 결과 h와 이전까지의 문자 y를 활용해, AttendAndSpell()함수를 통과시키면 문자들에 대한 probability distribution을 얻을 수 있습니다.
$$P(y|x) = AttendAndSpell(h,y)$$
a. Listener's Listen
그럼 Listener의 Listen()을 조금 더 자세히 들여보겠습니다. Listener의 구조는 아래와 같습니다.

앞서 언급했다시피 pyramidal BLSTM로 구성되어있으며 3 layer로 구성되어 있습니다. 주 목적은 dimension을 감소시키는 것이 목표 이며, 이는 두가지 장점이 있습니다.
먼저, computational complexity을 줄일 수 있습니다. 기존에 T길이 의 input이 들어오기 때문에 complexity가 O(TS)였던 반면 U길이의 feature로 줄여줌으로써 complexity를 O(US)로 줄일 수 있습니다.
또한, pyramidal 구조를 활용하지 않는 경우 모델 학습이 converge가 굉장히 느려진다고 합니다. 논문에서는 한달이 지나도 결과가 굉장히 좋지 않았다고 합니다. 이는 뒤에 나올 AttendAndSpell이 관련된 정보를 추출하기에 input time step이 너무 길다고 하고 있습니다. 하지만 pyramid구조를 3layer 활용해 time resolution을 2^3배 줄임으로써 뒤에 나올 이 문제를 해결했습니다.
notation을 조금 더 디테일 하게 살펴보겠습니다. input은 위에서 살펴보았다 시피 아래와 같습니다.
$$x_1,x_2...x_T$$
또한 output인 feature는 아래와 같을 것입니다.
$$h_1,h_2...h_U$$
모델은 BLSTM을 활용하는데, pyramidal 구조를 활용하고 있으므로 아래와 같이 표현할 수 있습니다.
$$h^j_i=pBLSTM(h^j_{i-1},[h^{j-1}_{2i},h^{j-1}_{2i+1}])$$
즉, j-1 layer에서 가져올 때는 pyramid구조를 활용해 가져오며, j layer에서 state를 가져올 때는 이전 time step i-1에서 가져오겠다는 뜻입니다.
첨언으로, bi-directional LSTM을 활용했기 때문에 streamable하지 않을 것입니다. 즉, time step별로 처리할 수 있으려면 encoding과정에서 time step별로의 feature를 뽑아낼 수 있어야하는데, bi-LSTM을 활용했기 때문에 앞 뒤 정보가 합쳐져 구분이 힘들어진다는 뜻입니다. 이를 극복하려면 uni-directional LSTM을 활용하면 되겠지만, 성능은 조금 떨어질 것 같습니다.
b. Speller's AttendAndSpell
다음으로 Speller의 AttendAndSpell()를 살펴보겠습니다. Speller의 구조는 아래와 같습니다.
(notation이 논문상에 조금 틀린 것 같아 필자가 수정을 조금 했습니다.)

앞서 언급한 바와 같이 Attention-based LSTM transducer 구조를 활용했습니다. 이는 [15][16] 논문에서 활용한 구조와 비슷합니다.
** [15] Attention-Based Models for Speech Recognition (arxiv’15)
** [16] Neural Machine Translation by jointly learning to align and translate (ICLR’15)
Speller의 notation을 조금 디테일 하게 살펴보겠습니다. 앞서 살펴본 것과 같이 input feature와 output 문자들의 distribution은 아래와 같을 것입니다.
$$\begin{matrix}
input:h_1,h_2...h_U \\
feature:y_1,y_2...y_{S-1}
\end{matrix}$$
중간에 쓰이는 decoder states와 context에 대한 notation은 아래와 같습니다.
$$\begin{matrix}
states = s_1,s_2...s_{S-1}\\
context = c_1,c_2...c_{S-1}
\end{matrix}$$
이제 모델을 살펴보겠습니다. 먼저 RNN layer를 활용해 state s_i를 뽑아 낼 것 입니다. RNN은 2 layer LSTM을 활용했습니다.
$$s_i=RNN(s_{i-1}, y_{i-1}, c_{i-1})$$
실제 torch로 구현 된 LAS 코드(https://github.com/AzizCode92/Listen-Attend-and-Spell-Pytorch)에 따르면 구현된 내용은 아래와 같습니다.
rnn_input = torch.cat([output_word,context.unsqueeze(1)],dim=-1)
rnn_output, hidden_state = self.rnn_layer(rnn_input,last_hidden_state)
rnn_output과 hidden_state의 차이를 참조하시려면 아래 더보기를 참조하세요.
------------------------------------------------------------------------
<RNN의 구조>
RNN의 In/Out을 조금 살펴보겠습니다.
torch.nn.LSTM layer(https://pytorch.org/docs/master/generated/torch.nn.LSTM.html#torch.nn.LSTM)에 따르면 함수의 선언
LSTM의 구조는 아래와 같습니다.
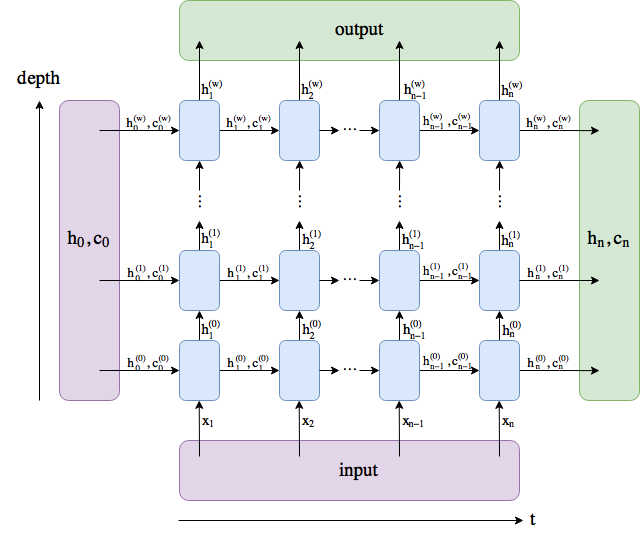
다른 블로그에 LSTM의 output dimension을 분석해놓은 내용이 있어 아래와 같이 첨부했습니다.
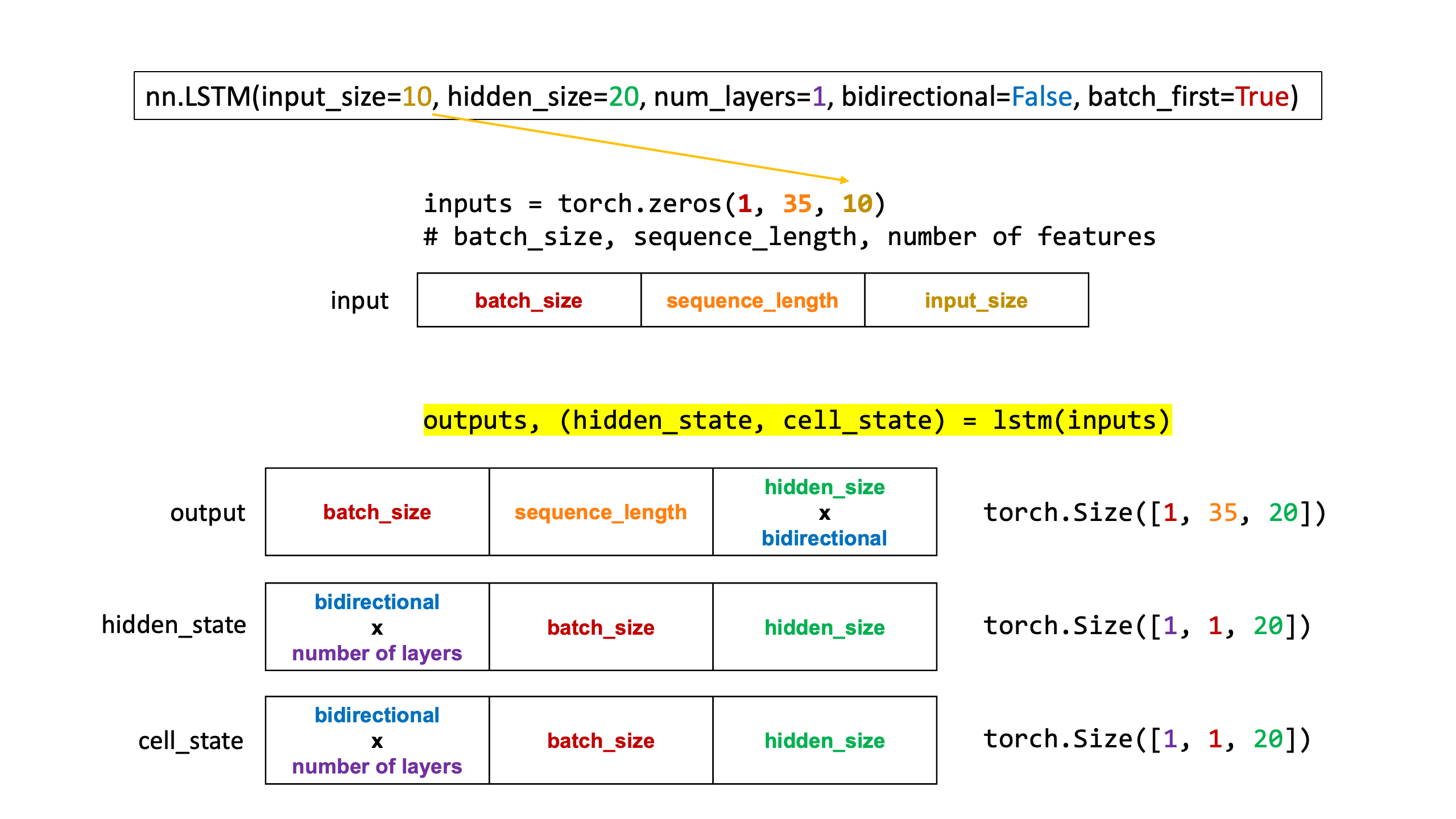
즉, output은 "마지막 layer"의 결과이며 output을 만들어내기 위해 주로 사용하고, hidden_state는 "마지막 sequence"의 결과이며 다음 LSTM연산을 위한 state를 넘겨줄 때 주로 사용합니다.
hidden_state와 cell_state의 차이는 short term memory에 대한 state인지 long term memory에 대한 state인지의 차이입니다.
------------------------------------------------------------------------
다음으로 앞서 얻은 RNN state s_i를 기반으로 현재 word가 encoder의 결과물인 h 중 어떤 것과 관련이 되어있는지에 대한 contexet를 얻어내야 합니다. 간단히 표현하면 아래와 같습니다.
$$c_i = AttentionContext(s_i,h)$$
과정을 조금 더 자세히 살펴보겠습니다. 먼저 s_i에 대해서 encoder output의 각각 u번째 결과와의 attention인 α를 구합니다. 해당 α를 구하기 전 각각의 s_i와 h_u은 MLP를 통하여 scalar engergy라는 중간 값을 얻어내고 softmax function을 통하면 최종적으로 attention score α가 됩니다.
$$\alpha _{i,u}= s_i\leftrightarrow h_u\ (content-based\ attention)$$
이때의 attention은 실제로 encoder output h에 대해 몇개의 frame에서만 sharp한 특성을 가지고 있다고 합니다.
그다음으로 해당 attention α과 각각의 encoder output의 u 번째 결과를 곱한 합을 통해 "i번째 state가 encoder의 output과 얼마나 연관되어있는지를 나타내는" context vector를 얻어냅니다.
$$c_i = \sum_u\alpha _{i,u}h_u$$
실제 코드에서는 아래와 같이 구현되어있습니다.
attention_score, context = self.attention(rnn_output, listener_feature)
listener_feature는 Listener에서 나온 U 길이의 feature이며, 이전에서 구한 RNN결과 중 output인 rnn_output을 활용했습니다.
위에서 활용한 attention을 구하는 방법은 다양한 방법이 있는데, 이 논문에서는 content-based attention을 활용했다고 합니다.
-----------------------------------------------------------------------
<Attention의 다양한 종류>
Attention의 컨셉이 등장한 하기 논문에서 뿐만 아니라 다양한 논문에서 다양한 Attention이 소개되었는데, 이들을 소개하겠습니다.
Neural Machine Translation by Jointly Learning To Align And Translate(ICLR’15)
먼저, 위 논문에서 등장한 Attention의 과정에 대해서 간단히 설명해보겠습니다. 먼저 용어에 대해서 설명하면 아래와 같습니다.
$$\begin{matrix}
s_i : decoder\ hidden\ state(for\ target\ y) \ at\ dim\ i \\
h_j : encoded\ output(from\ input\ x) \ at\ dim\ j
\end{matrix}$$
먼저, 이들을 이용해 input x와 target y 간의 attention score를 아래와 같이 구합니다.
$$\alpha _{i,j}=align(y_i,x_j)=\frac{exp(score(s_{i-1},h_j))}{\sum ^n_{j'=1}exp(score(s_{i-1}, h_{j'}))}$$
다음으로 context vector를 아래와 같이 구합니다.
$$c_i=\sum ^{n}_{j=1}\alpha _{i,j}h_j$$
Attention은 크게 아래와 위치와 상관없는 Content-based와 위치의 정보를 포함시키기 위한 Location-based로 나뉩니다.
1. Content-based Attention
하기 논문에서 소개된 Content-based attnetion는 기본적으로 아래와 같이 cosine similarity를 이용해 구하는 방식입니다.
Neural Turing Machines(arxiv’14)
$$score(s_i, h_j) = cossim(s_i, h_j) \approx \frac{ {s_i}^\top \cdot h_j}{|s_i||h_j|}$$
하지만 이외에도 아래와 같은 다양한 방법도 Content-based로 분류됩니다.
- Additive Attention (bahdanau attention, concat)
W1과 W2는 trainable weight matrix를 의미합니다.
Neural Machine Translation by Jointly Learning To Align And Translate(ICLR’15)
$$score(s_i, h_j) = V^\top tanh(W_1s_i+W_2h_j)$$ - Dot-Product Attention (Loung Attention)
Effective Approaches to Attention-based Neural Machine Translation(arxiv’15)
$$score(s_i, h_j) = {s_i}^\top \cdot h_j$$
- Scale Dot-Product Attention
Dot-Product와 다른 n 은 scaling factor로, input이 너무 길어서 softmax 결과가 너무 작은 gradient를 갖는 경우 사용하는 값 입니다.
Attention Is All You Need (NIPS’17)
$$score(s_i, h_j) = \frac{{s_i}^\top \cdot h_j}{\sqrt{n}}$$
- Scale Dot-Product Attention
- General Attention
Effective Approaches to Attention-based Neural Machine Translation(arxiv’15)
$$score(s_i, h_j) = {s_i}^\top Wh_j$$
2. Location-based Attention
하기 논문에서 소개된 Location-based attnetion은 alignment를 target에만 의존해서 만들어냅니다.
Effective Approaches to Attention-based Neural Machine Translation(arxiv’15)
$$\alpha _{i, j}=softmax(Ws_i)$$
-----------------------------------------------------------------------
마지막으로 얻어낸 이전에 얻은 RNN state s_i와 context를 기반으로 output distribution을 얻어냅니다. CharacterDistribution은 MLP와 softmax로 구성되어있습니다.
$$P(y_i|x, y<i) = CharacterDistribution(s_i,c_i)$$
실제 코드에서는 아래와 같습니다. raw_pred는 어떠한 과정을 통해 output_word를 얻어내게 됩니다.
concat_feature=torch.cat([rnn_output.squeeze(dim=1),context], dim=-1)
raw_pred = self.softmax(self.character_distribution(concat_feature))
output_word = conditional_function(raw_pred)
rnn_input = torch.cat([output_word,context.unsqueeze(1)],dim=-1)c. Learning & Decoding
마지막으로 학습시의 특징과 Decoding한 방법에 대해서 살펴보겠습니다.
먼저 학습시에는 당연히 Listen()과 AttendAndSpell()를 jointly하게 학습했으며, seq2seq와 같이 이전의 문자들을 활용해 다음 step prediction을 찾아내고, encoder에서 얻은 문장 전체에 대해 누적이 끝나면 해당 log probability를 최대화하는 과정으로 학습됩니다.
하지만 가끔 inference과정에서는 bad prediction이 나왔을 때, 그 다음 단어 예측이 힘들어지는 문제가 발생합니다. 이런 bad prediction문제는 데이터를 충분히 줌으로써 해결할 수도 있겠지만, resiliency를 주기 위해 GT만을 활용하지 않고 가끔은 직접 얻은 character distribution도 활용한다고 합니다.
즉, 이 방법을 활용하지 않는 경우 아래와 같이 다음 단어에 대해 step prediction을 진행하겠지만
$$GT_1, GT_2, ...GT_{k-1} \rightarrow Prediction_k$$
아래와 같은 방법도 함께 사용하는 것입니다.
$$GT_1, GT_2, ...Prediction_{k-1} \rightarrow Prediction_k$$
첨언하자면 기존의 GT만을 활용하는 기법인 전자는 Teacher Forcing이라고 부르기도 합니다. 이는 RNN의 위와 같은 문제점을 개선하기 위해 사용하지만 overfitting이나 generalization 감소와 같은 단점이 있기도 합니다. 또한 Inference과 Training간의 차이(discrepancy)가 큰 문제인 노출 편향 문제(Exposure Bias Problem)이 생길 수도 있습니다.
** Label Smoothing : overfitting과 overconfidence문제를 해결하기 위해 one-hot encoding된 hard label(0,1,0) 대신 soft label(0.1, 0.2, 0.8)을 활용하는 regularization 기법입니다. 추가적인 내용은 정리된 논문(https://arxiv.org/pdf/1909.08723.pdf)이 있으니 참조하세요.
수식으로 정리하면 아래와 같습니다.
$$\begin{matrix}
\underset{\theta}{max}\sum_ilogP(y_i|x,y^*_{<i};\theta)\rightarrow \underset{\theta}{max}\sum_ilogP(y_i|x,\tilde{y}_{<i};\theta)\\
y^*:ground\ truth\ of\ the\ previous\ characters\\
\tilde{y}:randomly\ sampled\ from\ the\ model
\end{matrix}$$
얼마의 비율로 진행할지에 관한 sampling rate에 대해서, 이 방법을 제안한 논문에서 scheduled sampling을 한 것과는 다르게 10%의 constant sampling rate를 처음부터 주었다고 합니다.
** [19] Scheduled Sampling for Sequence Prediction with RNN (arxiv'15)
또한 본 논문에서는 pre-training이 필요없다고 하고 있습니다. 즉, 실제로 Listen()에 softmax를 붙여 multi-frame phoneme state를 예측하도록 해보거나, GMM-HMM에서 생성된 음소들을 활용해 pre-training을 해보았는데 실제 개선이 없었다고 합니다.
다음으로 Decoding은 단순히 left-to-right beam search를 사용했으며 partial hypotheses의 개수는 β라고 부릅니다.
또한 유효한 단어만 생성해 search space를 제한하도록 dictionary를 선택적으로 추가할 수도 있다고 했지만, 모델이 real words를 잘 생성해내기 때문에 불필요했다고 합니다.
마지막으로, 앞서 사용한 beam search와 함께 따로 학습된 LM을 활용해 rescoring을 진행했는데, 아래 식과 같이 모델의 output인 P(y|x)를 normalize한 후에 λ값을 활용해 shallow fusion했다고 합니다. 여기서 normalization을 해준 이유는 log probability를 문장이 끝날 때까지 더해주기 때문에 score값이 음수 - 값으로 계속해서 작아져 긴문장들이 너무 무시되기 때문에 짧은 utterance들에 조금은 bias가 되어있기 때문에 normalize후에 진행했다고 합니다.
** Shallow Fusion : 서로 다른 두개의 모델을 사용합니다.
** Deep Fusion : End-to-End로 학습을 통해 한개의 모델을 만듭니다.
$$s(y|x) = \frac{logP(y|x)}{|y|_c}+\lambda logP_{LM}(y)$$
위식의 λ는 hold-out 된 validation set을 활용해 결정했다고 합니다.
3. Results
마지막으로 실험 결과에 대해 설명해보겠습니다.
a. Setting
먼저 실험 셋팅 환경에 대해 설명하겠습니다.
1. Dataset : 3M Google voice search utterances (2000 hrs)
- 모든 training set은 anonymized(익명화)되었고 hand-trascribed(전사)한 데이터 입니다.
- 10시간의 utterances는 랜덤하게 선택되어 hold-out validation set으로 활용되었습니다.
- 16시간의 utterances(22K)는 따로 분리되어 test set으로 활용되었습니다.
2. Augmentation : Room Simulator
- noise와 reverberations(잔향)을 추가해주었습니다.
- noise 소스는 YouTube와 환경 recordings자료 를 활용했다고 합니다.
- 결과적으로 20배 가량 데이터를 augmentation할 수 있었습니다.
3. Data Process
- Listener의 인풋은 40-D의 log-mel-filter bank features이며, 이는 10ms마다 계산되었다고 합니다.
** 위 10ms는 window의 shift size를 의미할 것입니다. feature를 만들때 window size는 보통 25ms, 30ms등을 활용하며 shift size는 이보다 작은 10ms, 15ms를 활용합니다. - 라벨 text는 문자들을 lower case로 만들어주고(text normalization), <space>, <comma>, <period>, <apstrophe>와 같은 구두점들은 유지했다고 합니다.
4. Baseline : CLDNN-HMM
- CLDNN은 bidirectional구조보다는 unidirectional구조가 이점이 있어, unidirectional구조를 활용했다고 합니다.
- WER : 8.0% (clean testset), 8.9% (noisy testset)
5. Model
- Listen : 3 layers (512 pB-LSTM nodes)
- Spell : 2 layers (512 LSTM nodes)
- init : uniform distribution (-0.1, 0.1)
- Beam Width (β) : 32
6. Optimizer : Asynchronous SGD
- loss : 0.2
- LR decay : 매 3M utterances 혹은 1/20 epoch마다 아래와 같이 step decay했다고 합니다.
$$L_t = L_{t-1}0.98$$ - validation set이 더이상 개선이 없을 때까지 학습했으며, 이는 2주가량 걸렸다고 합니다.
----------------------------------------------------------------------
<LR Decay에 대해서>
Learning Rate(LR)이 높은 경우 loss 값을 빠르게 줄일 수는 있지만, 최적의 학습을 벗어나게 만들기도 합니다. 또한 낮은 경우 최적의 학습이 가능하도록 할 수 있지만 그 단계까지 너무 오랜 시간이 걸리게 됩니다.
따라서 등장한 것이 LR Decay이며, 처음 시작시 LR 값을 크게 준 후 일정 epoch 마다 값을 감소시켜서 최적의 학습까지 더 빠르게 도달할 수 있게 하는 방법입니다. 아래와 같은 다양한 decay방법이 있습니다.
0. Constant : 특정한 상수 값을 사용하는 방법입니다.
$$L_t=L_0$$
1. Step Decay : 특정 epoch를 기준으로 해당 비율로 감소시키는 방법입니다. 예를 들어 30 epoch마다 0.9배합니다. 다만, 연속적이지 않아 hyper parameter를 정하기 어려운 문제가 있습니다.
2. Exponential Step : 지수함수를 활용한 decay
$$L_t = L_0e^{-kt}$$
3. Geometric Step : 특정 값을 계속 곱해주는 decay
$$L_t = L_0r^{t}$$
4. Cosine Decay : Cosine을 활용한 연속적인 decay
$$L_t = \frac{1}{2}L_0(1+cos(\frac{t\pi}{T}))$$
5. Linear Decay : Linear 함수를 활용한 연속적인 decay
$$L_t = L_0(1-\frac{t}T)$$
6. Inverse Sqrt Decay : 제곱근을 활용한 연속적인 decay
$$L_t = \frac{L_0}{\sqrt{t}}$$
7. Adaptive Decay : 다양한 모델과 데이터에 따라서 다른 방법으로 LR을 조절하는 방법이 Optimizer에 포함되어 소개되었습니다.
ex) Adagrad, Adadelta, RMSprop, Adam
----------------------------------------------------------------------7. Framework : DistBelief
- [38] Large Scale Distributed Deep Networks (NIPS’12, Google)
- Tensorflow의 전신이며, 몇 천개의 machine을 활용하는 cluster들을 활용해 연산할 수 있다고 합니다.
b. Results
이제 결과를 살펴보겠습니다.
Result1 : Qualitative
먼저 정량적 결과를 살펴보겠습니다. 결과는 아래 표와 같습니다.
특이한 것은 beam search를 진행할 때, 앞서 말한 것과 같이 search space를 제한하기 위한 dictionary를 활용해도 impact가 없었다고 합니다. 또한 CLDNN에서 활용한 것과 같이 32-beam을, n-gram LM과 "LM weight λ=0.008"과 함께 rescoring하니 성능이 향상 되었다고 합니다.
** [20] Convolutional, LSTM, Fully Connected DNN (ICASSP’15)
또한, 앞서 설명한 것과 같이 Prediction을 Teacher Forcing에 섞는 방법을 활용해, 10%의 previous 문자를 실제 sampling해서 진행했으며 이 또한 성능향상에 기여했다고 합니다.
추가적으로 CLDNN과 같이 convolutional filter를 활용하면 향상될 가능성이 있다는 언급도 했습니다.

Result2 : Attention Visualization
다음으로 실제로 활용되었던 Character 결과와 Audio Filterbanks 간의 content-based attention를 살펴보았습니다. 위에서 설명한 바와 같이 content-based attention은 cosine similarity과 비슷하다고 보면 될 것 같습니다.
아래 그림은 “how much would a woodchunk chuck”라는 utterance의 오디오와 각 hypothesis 간의 연관성을 나타냅니다.
실제로 monotonic(단조로운) 분포를 가지는 것을 볼 수 있습니다. 이는 location-based priors 없이도 학습이 잘 될 수 있음을 의미한다고 합니다.
또한 “woodchunk”이라는 단어와 ”chuck”이라는 단어가 발음상 동질성이 있어 약간의 confusion이 있음을 확인할 수 있으며, 문장의 시작과 끝을 적절하게 잘 찾아냈다고 합니다.

Result3 : Effect of beam width
다음으로 beam width β에 따른 성능 변화를 살펴보았습니다. clean Google voice search를 활용해 실험을 진행했으며 결과는 아래와 같습니다. 아래 결과는 beam width와 performance간의 correlation을 확인할 수 있으며, β가 16일 때까지는 일정하게 WER이 감소하는 것을 확인했다고 합니다.
Result4 : Effect of Utterance length
다음으로 문장의 길이에 따른 성능 변화를 살펴보았습니다. clean Google voice search를 활용해 실험을 진행했으며 결과는 아래와 같습니다. 문장이 길어질수록 성능이 좋지 않았으며, WER에러 중 deletion이 대부분이었다고 합니다.
이는 앞서 언급한 바와 같이 log probability를 문장이 끝날 때까지 더해주기 때문에 score값이 너무 작아져 중간중간 이가 빠진 것과 같은 hypothesis 결과들이 나오기 때문입니다.
본 논문에서는 location-based priors를 제공하면 긴 문장을 예측하는데 개선할 수 있지 않을까 제안하고 있습니다.
** location-based priors : location-based attention이나 location-based regularization을 활용할 때 얻을 수 있는 문장 내 위치 정보
또한 문장이 짧아질수록(≤ 2words)도 성능이 좋지 않았다고 하며, WER에러 중 substitutions, insertions가 대부분이었다고 합니다. 아마 단어 간의 문맥이 없기 때문에 무슨 문장인지 알아채기 힘들었을 것 같습니다.

Result5 : Word Frequency
다음으로 학습시 사용하는 단어들의 빈도수가 test set에 대한 결과에서 recall이 어떻게되는 지를 알아보았습니다. 해당 실험에서의 reacll은 단어가 utterance(문장)내에서 위치에 상관없이 등장했음을 의미합니다.
결과적으로 아래 그림과 같이 드물게 학습된 단어들은 낮은 recall을 가지며, 높은 variance를 가진다고 하고 있습니다. 예를 들어 85k번 학습된 "and"는 80% recall을 가지며, 더 높은 recall(90%)를 가지는 "in"으로 잘못 transcribed되는 경우도 있다고 합니다. 이는 LM의 개선이 필요함을 의미하기도 합니다.
또한 “walkervile”라는 단어는 학습에서 1번 사용되었는데 recall이 100%로 나온 것을 보아, 빈도 뿐아니라 발음의 독특성도 영향이 있는 것 같다고 합니다.

** Precision, Recall에 대해 궁금하시면 아래 더보기를 참조하세요
----------------------------------------------------------------------
<Precision-Recall>
특정 결과에 대해 나타내기 위한 Metric으로 많이 사용되는 Precision과 Recall에 대해 이해하기 위해 아래의 Confusion Matrix(오차 행렬)을 먼저 이해해보겠습니다.
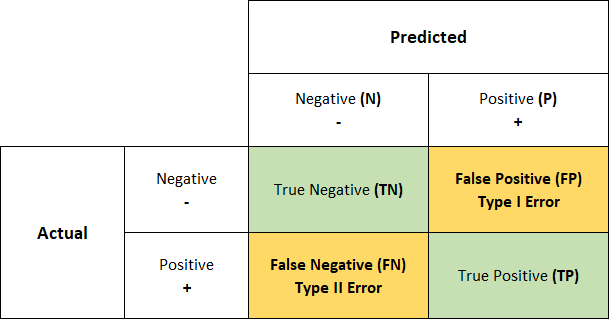
1. Predicted : 예측 값
- Positive : 정답일 것이라 예상
- Negative : 오답일 것이라 예상
2. Actual : 실제 값
- Positive : 실제 정답
- Negative : 실제 오답
3. 결과
- TP(True Positive) : 정답이라 예상해서, 맞음.
- FP(False Positive, False Alarm) : 정답이라 예상했지만, 틀림.
- FN (False Negative, Missed Detection) : 오답이라 예상했지만, 틀림.
- TN(True Negative) : 오답이라 예상했지만, 맞음.
이를 활용해 다양한 Metric을 얻어낼 수 있는데 아래와 같습니다.
1. Accuracy : 전체중에 True인것, 즉 (정답==정답), (오답==오답) 의 확률
$$\frac{TP+TN}{TP+FP+FN+TN}$$
2. Precision(정밀도) :정답이라고 한 것 중에 실제 정답인 것의 확률
$$\frac{TP}{TP+FP}$$
3. Recall(재현율), TPR(True Positive Rate) : 실제 정답인 것중에 정답이라고 해서 맞춘 비율.
$$\frac{TP}{TP+FN}$$
** FPR(False Positive Rate) : 실제 오답인 것 중에 정답이라고 해서 틀린 비율.
$$\frac{FP}{FP+TN}$$
4. F1score : Precision과 Recall의 기하평균
$$2\times \frac{Precision\times Recall}{Precision+Recall}$$
이때 TPR과 FPR을 통해 모델을 분석하기 위한 RoC(Receiver Operating Characteristic) Curve라는 것이 있습니다.
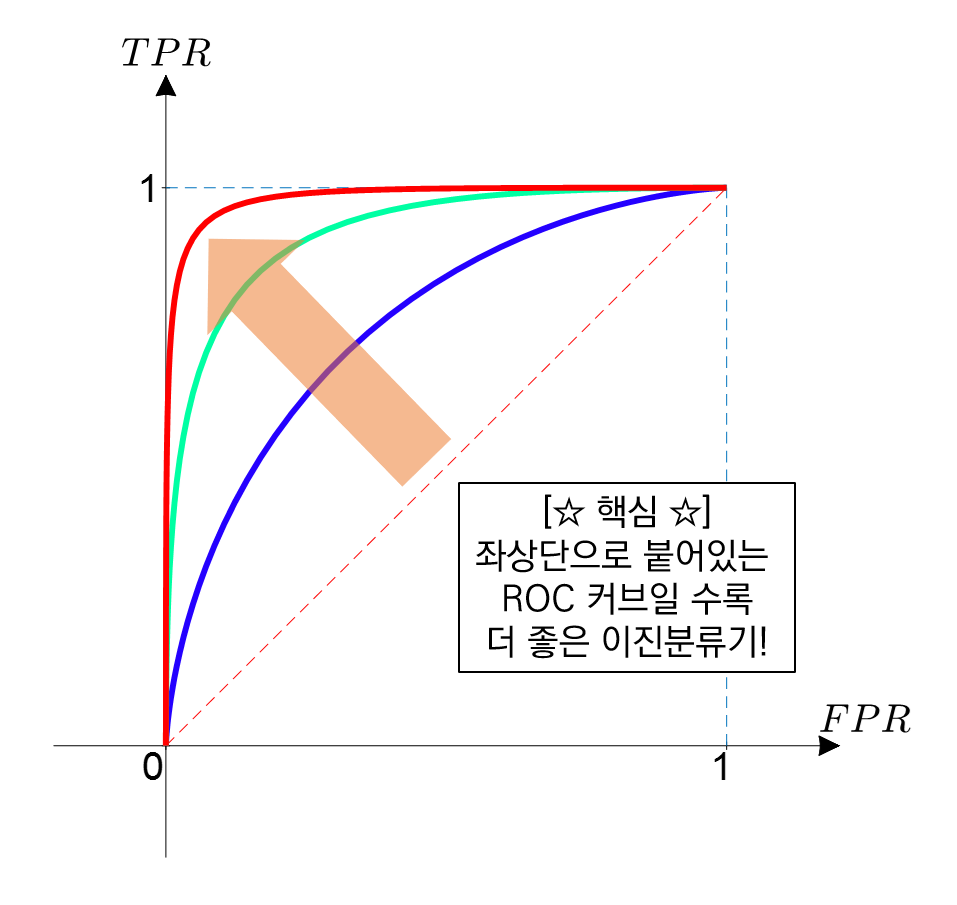
----------------------------------------------------------------------
Result6 : Decoding Examples
마지막으로 Decoding한 결과 예시를 살펴보고자 합니다. 해당 실험은 앞서 언급한 dictionary와 LM없이 진행되었습니다.
[Case1] “aaa”의 다양한 spelling을 학습한다.
아래 결과와 같이 본 논문의 모델은 chain rule decomposition을 활용한 conditional independence가 없기 때문에, "aaa"가 "triple a"와 같은 단어의 결과로 도출할 수 있다고 합니다.
즉, CTC의 경우 conditional independence가 있어, 앞뒤 단어에 대한 고려를 하지 않기 때문에 최종적으로 이런 결과를 얻을 수 없다고 합니다.
$$conditional\ independence=p(y_{i+1}|x)\overset{\times }{\rightarrow} p(y_i|x)$$
또한 전통적인 DNN-HMM에서는 여러가지 spelling을 위해서는 lexicon(pronunciation dictionary)가 필요할 것이기 때문에, 이런 이점까지는 없을 것입니다.
[Case2] 발음이 아예 다른 “xxx”
아래 결과와 같이 aaa와 발음이 아예 다른 xxx가 나오기도 했는데, 이는 LM이 AM에 힘을 너무 실어주었기 때문일 것이라고 예측합니다. 즉, speller는 aaa에서 나온 정보를 통해 "triple"을 예상했을 것이고, triple을 xxx와 연관시켰을 것이라고 합니다.

[Case3] 3번 연속 “seven”
다음은 아래 그림과 같이 연속적으로 같은 단어가 반복되는 경우 성공적으로 결과를 도출했다고 합니다. 본 논문에서는 content-based attention을 활용했기 때문에 위치에 약하므로 연속된 단어에 대한 각각의 attention 정보를 상실했을 것이라 예상했는데, 정상적으로 결과가 나온 것을 보고 연속된 단어를 위해서 location-based priors가 굳이 필요없어 보인다고 합니다.

https://post.naver.com/viewer/postView.nhn?volumeNo=16133750&memberNo=6863292&vType=VERTICAL
https://brightwon.tistory.com/11
https://heekangpark.github.io/nlp/attention
https://nongnongai.tistory.com//95
https://m.blog.naver.com/laonple/221017461464