
[Multi-Modal Fusion] TransFusion : Robust LiDAR-Camera Fusion for 3D Object Detection with Transformer (CVPR'22)
2022. 12. 21. 00:49ㆍDevelopers 공간 [SOTA]
728x90
반응형
- Paper : https://openaccess.thecvf.com/content/CVPR2022/papers/Bai_TransFusion_Robust_LiDAR-Camera_Fusion_for_3D_Object_Detection_With_Transformers_CVPR_2022_paper.pdf
- Authors
- Huawei + Hong Kong Univ, CVPR’22
- Main Idea
- Image와 Lidar간의 hard association을 soft association으로 대체
- Tasks : 3D Object Detection
- Results : Waymo, nuScences (Leaderboard)
<구성>
1. Problem : LiDAR-Camera fusion의 문제점
2. Approach : Soft-Association mechanism
a. Convolutional backbones : feature extraction을 위한 backbones
b-1. First Decoder & FFN : A detection head based on a transformer decoder
b-2. + image-guided query initialization strategy : object를 다루는 방법
b-3. Second Decoder : A detection head based on a transformer decoder
3. Results
a. Setting
b. Results
글효과 분류1 : 논문 내 참조 및 인용
글효과 분류2 : 폴더/파일
글효과 분류3 : 용어설명
글효과 분류4 : 글 내 참조
1. Problem : LiDAR-Camera fusion의 문제점
- 기존 Lidar-Camera Fusion 의 분류
- Result-level : detector의 결과를 모아 3D proposals를 제공
- ex) FPointNet[29], RoarNet[39]
- proposal-level : region-proposal level 에서 RoI Pool 등을 활용해 fusion 하는 기법
- ex) MV3D[5], AVOD[12]
- point-level fusion : early-fusion기법으로 feature 정보에서 바로 fusion 을 진행하는 기법
- 최근 대부분의 접근이며 가장 promising 한 결과를 내고 있습니다.
- 주로 LiDAR와 image pixels 간의 hard association을 찾는다.
- 따라서 calibration matrices에 의존적입니다.
- LiDAR를 augment하는 대상은 다음과같이 분류 할 수 있습니다.
ex1) [with segmentation scores] PointPainting[46], FusionPainting[51]
ex2) [with CNN features] EPNet[10], LaserNet[22], MVXNet[40], PointAugmenting[47], [62]
ex3) [with BEV plane] MMF[16], ContFuse[17], PI-RCNN[50], 3D-CVF[59]
- Result-level : detector의 결과를 모아 3D proposals를 제공
- 기존 point-level fusion의 문제점
- 1. element-wise addition과 concatenation를 주로 활용해 fuse 합니다.
- 이는 낮은 퀄리티의 이미지(cf. bad illumination)로 인해 performance 가 감소되기도 합니다
- Under-explored되었습니다.
- 2. sparse한 LiDAR points와 dense한 image pixels 간의 high association을 주로 활용합니다.
- 이는 high-quality calibration에 의존적이게 됩니다.
- sparse한 point cloud가 많은 image features들을 낭비하게 됩니다.
- 1. element-wise addition과 concatenation를 주로 활용해 fuse 합니다.
2. Approach : Soft-Association mechanism
- 이 논문은 기존의 fusion process에 대해 포커스를 Re-position하고자 합니다.
- hard-association을 soft-association로 대체합니다.
- image quality와 sensor misalignment로 인한 악효과에 대해 robustness를 제공하고자 합니다.
- LiDAR-camera 3D detection에 대해 최초로 transformer를 활용했다고 합니다.
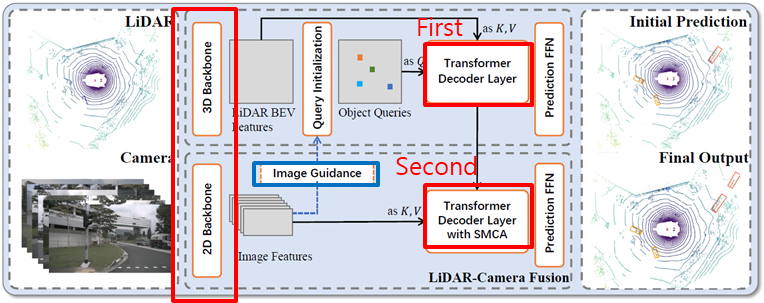
<Architecture(전체 구조)>
a. Convolutional backbones
b. A detection head (transformer decoder 2개로 구성)
b-1. First decoder : predicts initial bboxes
b-2. + image-guided query initialization strategy
b-3. Second decoder : predicts
a. Convolutional backbones : feature extraction을 위한 backbones

- 2D Backbone : (NuScenes) DLA34[60] of pretrained CenterNet
- DLA34[60] 구조: 기존 Resnet의 residual connection을 “still shallow, simple”하게 하기 위해 iteratively and hierarchically하게 feature를 merge하는 구조입니다.
- Training 단계에서는 frozen 상태로 진행합니다.
- Input Image 사이즈 : 448 x 800 (896 x 1600 resolution에 비길만하다고 합니다)
- Image Feature Fetching
- 기존 point-level fusion의 문제점은 Lidar point가 sparse 하기 때문에 같은 수의 image feature만 fetch가 가능했다는 점이었습니다.
- 이런 문제를 줄이기 위해 Camera Feature F_C 를 (N_V, H, W, d) 형태로 하며, cross attension mechanism내에서 sparse-to-dense & adaptive 방법으로 feature를 fusion 하도록 합니다.
- 3D Backbone : VoxelNet [52,67]
- 1) pretrain (3D backbone + the 1st decoder + FFN)
- 1st decoder와 FFN에 대해서는 뒤에서 다시 설명합니다.
- 위 VoxelNet 그림과 같이 Lidar Point Cloud를 input으로 받아 sparse한 4D Tensor를 얻어냅니다.
- Task : 3D Object Detection
- 2) train (all)
- voxel size
- nuScenes : (0.075m, 0.075m, 0.2m) following CenterPoint[57]
- Waymo : (0.1m, 0.1m, 0.15m)
- voxel size
- 1) pretrain (3D backbone + the 1st decoder + FFN)
b-1. First Decoder & FFN : A detection head based on a transformer decoder
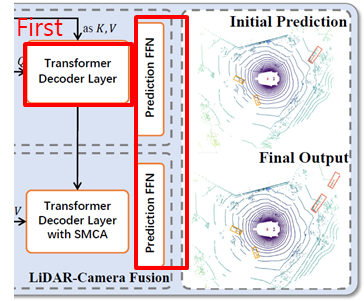
- Decoder Head (FFN:Feed Forward Network)
- 구분된 2-layer 1x1 convolution을 활용
- input : N 개의 object queries
- output : N x {dx, dy, gz, l, w, h, yaw, velocity + K class heatmap}
- auxiliary decoding mechanism [23] : 각각의 decoder layer 뒤에 FFN를 붙이는 것
- 구분된 2-layer 1x1 convolution을 활용
- First decoder : 초기 bbox들을 predict하기 위한 decoder입니다.
- input : LiDAR point cloud
- BEV features (K,V)
- with sparse set of object queries (Q)
- input 의존적이고 category를 알 수 있는 방법으로 query를 초기화합니다.
- 즉, image-guided query initialization strategy를 사용합니다
- 이는 b-2에서 설명합니다.
- input : LiDAR point cloud
더보기
-----------------------------------------------------------
<추가 설명>
Cross Attention : object queries ↔ feature maps
→ feature map과 관련 있는 object candidates 들을 aggregate 합니다
Self Attention : object queries
→ object candidates 간의 pairwise 한 관계들을 찾아냅니다
Query Position Embdding : element-wisely summed with the query
→ network가 position를 jointly하게 찾아 낼 수 있도록 합니다.
-----------------------------------------------------------
<추가 설명>
Cross Attention : object queries ↔ feature maps
→ feature map과 관련 있는 object candidates 들을 aggregate 합니다
Self Attention : object queries
→ object candidates 간의 pairwise 한 관계들을 찾아냅니다
Query Position Embdding : element-wisely summed with the query
→ network가 position를 jointly하게 찾아 낼 수 있도록 합니다.
-----------------------------------------------------------
b-2. + image-guided query initialization strategy : object를 다루기 위한 방법


- 왜 하는걸까?
- Point Cloud 에서 detect 하기 어려운 object들을 다루기 위해서
- query initialization 단계에서 image guidance를 제공하기 위해서
- History : 이전에는 어떻게 했을까
- DETR[2], Deformable DETR[70] : Randomly generate(DETR) 혹은 learned parameters(Deformable DETR)를 사용했습니다
- 6개의 decoder layer들을 iterative하게 학습했습니다.
- 하지만 convergence가 느립니다.
- 하지만 작은 오브젝트에서는 low performance를 보입니다.
- Deformable[70] : 위 첫번째 그림에서와 같이 reference points(A)를 사용했습니다.
- 6개의 decoder layer들을 iterative하게 학습했습니다.
- Efficient DETR [56] : object queries를 초기화하는 개선된 방법을 제시
- 방법
- ← (A) RPN을 활용한 reference features를 활용
- ← (B) Encoder feature를 활용해 object queries를 만들었습니다.
- 이를 활용해 6 layer decoder 에 필적하하는 1 layer decoder를 학습했습니다
- 방법
- DETR[2], Deformable DETR[70] : Randomly generate(DETR) 혹은 learned parameters(Deformable DETR)를 사용했습니다
- Ours1. Image-guided Query Initialization
- high-resolution 이미지의 능력을 활용하기 위해 object queries를 다음과 같이 선택했습니다.
- 𝐹_𝐶 : height축 방향으로 Collapsing을 진행했습니다 [32]
- [32] : BEV와 image W의 관계가 더 쉽게 설립되는 것을 발견
- 𝐹_𝐿𝐶 : 위 첫번째 그림과 같이 라이다 피처인 𝐹_𝐿와 카메라 피처인 𝐹_𝐶 간의 cross attention map을 만듭니다.
- 𝐹_𝐶 : height축 방향으로 Collapsing을 진행했습니다 [32]
- high-resolution 이미지의 능력을 활용하기 위해 object queries를 다음과 같이 선택했습니다.
- Ours2. Input-dependent initialization : object queries를 초기화하고 선택하는 방법
- 𝐹_𝐿𝐶 → 𝑆_𝐿𝐶 : cross attenton map으로 부터 Lidar only heat인 𝑆_𝐿과 평균을 내 heatmap을 예측합니다.
- 𝐹_𝐿𝐶 : (X, Y, d) BEV 사이즈
- 𝑆_𝐿𝐶 : (X, Y, K) object 후보
- object queries를 top-N candidates를 활용해 초기화하고 선택합니다.
- 너무 가까운 object가 나오는 것을 피하기 위해 CenterNet과 비슷하게 local maximum elements를 선택합니다.
- category-aware : scale variance를 위해 element-wise하게 category-embeddings과 sum 합니다.
** scale variance : 다양한 scale의 크기가 나오도록 하기 위해
- 𝐹_𝐿𝐶 → 𝑆_𝐿𝐶 : cross attenton map으로 부터 Lidar only heat인 𝑆_𝐿과 평균을 내 heatmap을 예측합니다.
b-3. Second Decoder : A detection head based on a transformer decoder

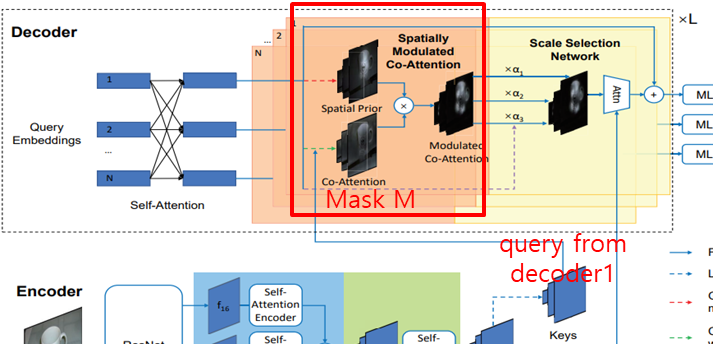

- Second decoder : rich texture + color cues for better detection results
- attention mechanism을 더욱 attentively하게 associate 하고 fuse 합니다
- Query(Q) : first stage에서 나온 object queries를 Query로 사용합니다.
- Key-Value(K,V) : image feature를 Key,Value로 사용합니다
- Pros
- spatial + contextual한 관계를 얻을 수 있습니다.
- adaptively하게 어느 곳에서 어떤 것을 fusion 할지 결정할 수 있습니다.
- SMCA(Spatially Modulated Cross Attention) : locality inductive bias를 위해
- 자주 사용되는 기존 Multi-Head attention
- 정보를 상호 교환하기 적합
- soft association을 만들기 적합
- Problem : LiDAR와 Image 간의 다른 domain이 문제로 인해 학습시간이 길어집니다.
- [9] weights cross attention (locality inductive bias)
- cross attention map을 weighting 하기 위해 2D circular Gaussian mask M을 활용합니다
(2D circular Gaussian mask M은 centerNet[65]와 비슷하게 만들어 집니다.) - query prediction을 image plane에 projection하는 과정에서 쓰이는 cross attention map을 weightinhg하는 것입니다.
- 네트워크가 관계된 위치를 더 잘 찾아갈 수 있도록 도와줍니다.
- cross attention map을 weighting 하기 위해 2D circular Gaussian mask M을 활용합니다
- [9] weights cross attention (locality inductive bias)
- 자주 사용되는 기존 Multi-Head attention
- attention mechanism을 더욱 attentively하게 associate 하고 fuse 합니다
3. Results
a. Setting
- Datasets
- nuScenes : 3D detection + tracking
- point cloud + 6 calibrated images (360° FOV)
- metric : mAP, NDS (NuScenes detection score)
- mAP : BEV center distance (3D IoU는 아닙니다) → 0.5m, 1m, 2m, 4m threshold에 따라 계산
- NDS : mAP + translation, scale, orientation, velocity, etc …
- Waymo : 3D detection
- point cloud(nuScenes보다 dense합니다) + images (250° FOV)
- metric : mAP, MAPH
- mAP : 3D IoU
- Level1 : 5 LiDAR points 보다 많은 boxes 찾기
- Level2 : 최소 1 LiDAR point인 boxes 찾기
- mAPH: heading accuracy와 함께 weighted된 것
- mAP : 3D IoU
- nuScenes : 3D detection + tracking
- Models
- Loss(≒3DETR[23]) : Focal Loss(binary cross-entropy) + L1 Loss(BEVcenter) + IoU Loss
- heatmap prediction을 위해 CenterPoint[57]에서 활용된 Penalty-reduced focal loss를 활용합니다.
- TransFusion-L : 위 initial bbox predictions만 학습한 결과입니다.
- Loss(≒3DETR[23]) : Focal Loss(binary cross-entropy) + L1 Loss(BEVcenter) + IoU Loss
b. Results
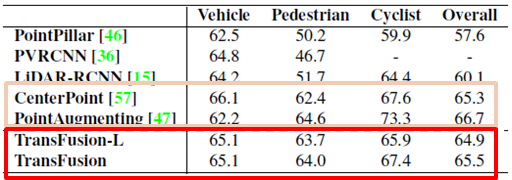

- Waymo(위 첫번째 그림)
- Transfusion-L에서 Transfusion으로 학습되었을 때 향상 효과가 굉장히 적었습니다.
- Reason 1. 이미지의 semantic 정보가 적은 효과를 가져오는 것으로 예측됩니다
- Reason 2. 1번째 decoder가 이미 정확한 location을 예측하고 있는 것으로 예측됩니다.
- Counter parts
- CenterPoint : multi-frame input을 활용했다. 본 논문에서도 future work로 보고 있습니다.
- Point Augment : 카메라 FOV밖에 있는 예측을 얻기 위해 CenterPoint에 의존도을 많이 했습니다.
- flexible하지 않습니다.
- Transfusion-L에서 Transfusion으로 학습되었을 때 향상 효과가 굉장히 적었습니다.
- nuScenes(위 두번째 그림)
- SOTA인 L, LC보다 성능이 좋았습니다.
- 저조한 이미지 상태에 robust함을 보였습니다.
- degenerated 이미지 quality와 sensor의 misalignment에 대해서도 robust했습니다.
<추가 정보>
1.Waymo
CenterPoint[57] : 현재 LeaderBoard에서 0.7193 MAPH를 보이고 있지만, 이 논문에서는 36 epochs만 활용했습니다.
2.nuScenes- 3D multi-object tracking(MOT)
CenterPoint algorithm을 활용해 tracking 을진행했으며 71.8 MOTA를 보였습니다.
CenterPoint(63.8 MOTA) 와 SOTA(69.3MOTA)보다 높게 나왔습니다.
728x90
반응형