
2025. 7. 30. 22:52ㆍ소개글/에세이
UNet을 활용한 DDPM 이후 GLIDE, Imagen, Dall-e, ADM, LDM 등 다양한 T2I(Text-To-Image)모델이 등장하면서 UNet 기반의 Diffusion 모델에 텍스트 컨디션을 주는 다양한 방법이 가능해졌습니다.
이와 같이 Text를 컨디션으로 주는 방법도 다양하겠지만, 이에 추가적으로 유저 인터페이스를 위해 Task-specific한 다양한 condition을 제공하기 위한 방법도 있습니다.
ex) User Scribbles, Line Drawkings, Key points, Segmentation Maps, Layout, Normal Map, Depths, Edge, Drag, Masked Image 등
하지만 이런 방법들은 "Multi-modal Fusion"보다는 Conditioning 혹은 Control이라는 용어를 사용하는데, 특이하게도 어떤 모델에서는 Multi-modal이라는 용어를 사용하기도 합니다.
이번 글에서는 Diffusion Model에서 기존에 Conditioning하는 기법들이 무엇인지 간단하게 살펴보고, 왜 어떤 모델은 "Multi-modal"이라고 부르는지와 Multi-modal을 다루기 위해 어떤 방법을 활용하는지에 대한 필자의 의견을 적어보려고 합니다.
단, 이번 글에서는 Personalization과 관련된 Condition기법은 다루지 않겠습니다. 이는 아래 글에서 의견을 적어보았습니다.
** https://tkayyoo.tistory.com/177
<구성>
0. Multi-modal Fusion
a. Multi-modal Fusion의 분류와 특징
b. Multi-modal Fusion 방법
1. Conditioned Generation in Diffusion : Basic
a. T2I 모델에서의 기본적인 Condition
b. ControlNet
c. T2I-Adapter
d. IP-Adapter
2. How to utilize modality?
a. (UNet) 1Prompt1Story
b. (UNet) DiffDis
c. (DiT) TACA
d. (DiT) Regional Prompting
e. (DiT) Deep Fusion Synthesis
글효과 분류1 : 논문 내 참조 및 인용
글효과 분류2 : 용어설명
0. Multi-modal Fusion
Diffusion Model에서 다양한 형태의 컨디션을 제공하는 방법에서도 두 개 이상의 Modality를 잘 Fusion하는 방법이 중요합니다.
즉, 기존 T2I 모델의 경우 Image를 생성하기 위한 기존의 feature들에 text의 정보를 섞기 위해 다양한 기법이 필요합니다. 하지만 이들은 "Multi-Modal" 혹은 "Multi-Modal Fusion"이라고 불리지는 않습니다.
오히려 "Condition"혹은 "Control"이라고 불립니다.
필자는 이에 대한 이유가 아래와 같다고 생각합니다.
Multi-modal Fusion은 "구조적으로 Modality가 대등한 결합일 때"이다.
즉, 여러개의 modality를 동등하게 결합하는 모델은 양방향 정보 Connection을 통해 Joint Representation을 만들어내고, 이럴 때 "Multi-modal Fusion"이라고 부릅니다.
반대로 하나의 Modality가 주가 되고 다른 Modality는 보조를 맡는 기존 T2I Diffusion 모델은 단방향 정보 Connection을 통해 Repsentation을 만들어내기 때문에 "Multi-modal Fusion"이라고 부르지 않습니다.
한편 LLM과 같은 보통 Transformer구조의 모델에서는 Multi-modal을 다룰 때, 모든 Modality를 각각의 토큰 Sequence로 변환해서 입력을 처리하는데, 이는 동등한 레벨에서 결합되며 Self-Attention을 통해 토큰 간 양방향 정보 교환이 가능해집니다.
게다가 학계에서도 Transformer구조가 Multi-modal Fusion으로의 확장 가능성이 높다는 인식이 강해, 보통 Multi-modal fusion은 Transformer 구조를 활용하는 모델이 지배적인 것 같습니다.
** 항상 그렇지는 않습니다.
이와 같은 이유로, Diffusion 모델도 이후에 등장한 DiT(Diffusion Transformer)구조에서나 MMDiT에서는 T2I Diffusion 모델임에도 Multi-modal에 대한 정보를 깊게 다루게 되는 것 같습니다.
이번 챕터에서는 일반적인 "Multi-modal Fusion"에 대해 전반적인 의견을 보이겠습니다.
a. Multi-modal Fusion의 분류와 특징
여러개의 Modality를 Fusion하는 방법은 다양하고 이를 부르는 명칭도 다양한데, 네트워크 내의 정의된 Fusion의 위치에 따라 아래오 ㅏ같이 다양한 이름으로 불립니다.
| Early Fusion | Implicit Fusion | Late Fusion | |
| 명칭 | Signal-Level Fusion Low-Level Fusion(LLF) Mid-Level Fusion(MLF) Feature-Level Fusion |
Mid-Level Fusion(MLF) Feature-Level Fusion |
Result-Level Fusion High-Level Fusion(HLF) Feature-Level Fusion |
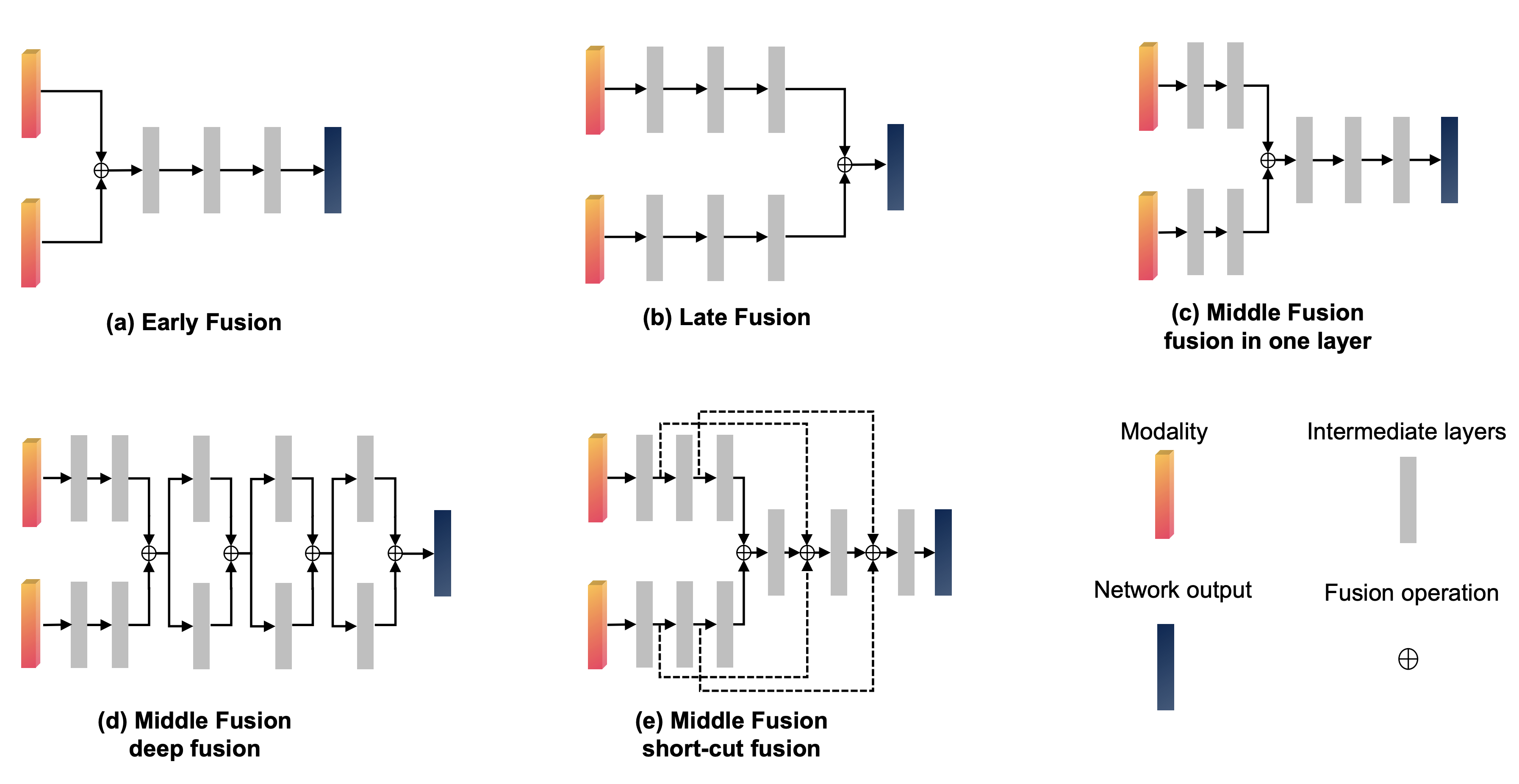
하지만, 이는 네트워크가 여러개의 stage로 이루어진 경우 해당 stage들이 다르게 정의되기 때문에, 특히나 Mid-Level 혹은 Feature-Level과 같은 용어는 다양한 네트워크에서 동일하게 정의되기는 어렵습니다.
그래서 이번 글에서는 간단하게 아래와 같은 두가지로 나눠 살펴보려고 합니다.
- Early Fusion : 여러개 modality들의 vector representation을 미리 합친 후에 하나의 모델의 Input으로 들어갑니다.
- Late Fusion : 각 modality 별로 독립적인 모델을 가지고 학습되며, 각각의 output들이 합쳐집니다.
각각에 대해 한번 살펴보겠습니다.
먼저 Early Fusion은 modality간에 의존성이 있을 때나 대부분의 modality가 비슷한 성능을 낼 때 사용합니다.
예를 들어 Image를 주고 Text를 통해 질문하는 VQA(Visual Question Answering) task의 경우, Image와 Text가 결합되지 않으면 합리적인 결과가 나올 수 없으므로 이런 의존성을 위해 Early Fusion을 활용하는 것이 유리합니다.
또한 Early Fusion은 미리 modality들을 fusion해 하나의 모델을 통해 추론하므로, pre-trained weight를 활용하는 것에 유리합니다.
그리고 Early Fusion이 메모리나 Computation 관점에서는 더 유리한 경우가 많습니다. Late Fusion과 달리 각각의 Modality를 위한 모델이 따로따로 필요하지 않기 때문에 모델의 크기가 작아질 수 있고, 실제 처리 시간도 작은 경우가 많습니다.
마지막으로 Early Fusion을 활용하는 경우 Heuristic하게 정보를 fusion할 수 있는 가능성도 있습니다.
예를 들어 2D Image와 3D Point Cloud를 fusion할 때는, vector representation으로 표현되기 전에 Extrinsic 파라미터 등을 활용해 projection한 정보들을 함께 활용할 수도 있습니다.
다음으로 Late Fusion은 하나의 modality가 지배적인 경우에 주로 사용합니다.
즉, 여러개의 modality중 하나가 다른 것들보다 월등한 "성능"을 내는 경우에 활용합니다.
또한, Late Fusion은 각각의 modality가 높은 성능을 내고, 이들의 성능을 해치지 않고 싶을 때 활용하기도 합니다. 각각의 modality마다 필요한 정보 추출의 Depth가 다를수도 있고, 처리하는 과정에서 누락되는 정보 없이 Representation을 만들어 Fusion할 수도 있기 때문입니다.
이와 같이 단계에 따른 Fusion 기법의 장단점을 살펴보았는데, 여러개의 Modality를 Fusion하는데 있어서 고려해야 할 이슈들 중 몇가지를 나열해보았습니다.
- 1. 데이터의 누락 : 모든 modality에 대한 데이터가 존재해야하기 때문에 Multi-modal Fusion을 학습하기 위해 가장 어려운 것은 데이터입니다. 따라서 특정 modality에 대해 누락된 데이터가 있다면 이를 해결하기 위한 방법이 필요합니다.
- 2. Inter-modality : 서로 다른 modality는 각각 독립적으로도 의미를 가질 수 있지만, 결합되면 더 많은 정보를 얻을 수 있습니다. 따라서 해당 modality간의 연관성을 고려할 수 있는 방법이 필요합니다.
- 3. Cross-modality : 어떤 경우에는 각 modality는 불가분한 상호작용(Inseparable Interaction)이 존재하고, 개별적으로는 정보가 불완전합니다. 따라서 결합되어야만 의미 있는 정보가 생성되는 경우 이들이 서로 적절히 보완되도록 할 방법이 필요합니다.
b. Multi-modal Fusion 방법
이번에는 여러개의 Modality들을 Fusion하는 방법들을 정리해보고자 합니다.
필자의 경험상 여러개의 Modality를 Fusion하는 일반적인 방법들은 결국 대부분 아래의 여섯가지 방법 안에 속한다고 생각합니다.
- 직접적
- feature 간의 Concatenation
- feature 간의 Addition
- feature 간의 Average & Mean
- feature 간의 Attention (Self-Attention, Cross-Attention)
- feature 간의 Feature-wise Modulation
ex) Adaptive Normalization (AdaGN / AdaIN / AdaLN)
** AdaIN은 아래 더보기를 참조하시고, AdaLN은 이후에 설명하겠습니다.
$$x=\gamma({\boldsymbol{Z}_B})*\boldsymbol{Z}_A+\beta({\boldsymbol{Z}_B})$$
- 간접적
- feature의 latent간의 Contrastive Alignment Loss
-----------------------------------------------------------
<AdaIN (adaptive instance normalization)>
주어진 스타일을 다른 곳에 adapt시키기 위해 사용하는 normalization 기법입니다.
** Arbitrary style transfer in real-time with adaptive instance normalization (arxiv'17)
아래 식과 같이 content input $x$의 평균과 분산을 style input $y$와 일치하도록 조정하며. affine parameter들이 없습니다.
$$AdaIN(x)=\sigma (y) (\frac{x-\mu(x)}{\sigma (x)})+ \mu (y)$$
-----------------------------------------------------------
조금 더 구체적으로, Transformer 구조를 활용하는 경우는 여러개의 Modality를 Fusion하기 위해 아래와 같은 방법들을 주로 활용합니다.
- a. Early Summation : 여러개의 modality들을 weighted sum하는 것
$$\boldsymbol{Z}\leftarrow T\,f({\color{blue}\alpha\boldsymbol{Z}_{(A)}\oplus\beta\boldsymbol{Z}_{(B)}})=MHSA(\boldsymbol{Q}_{({\color{blue}AB})},\boldsymbol{K}_{({\color{blue}AB})},\boldsymbol{V}_{({\color{blue}AB})})$$ - b. Early Concatenation : 여러개의 modality들을 concatenation하는 것
$$\boldsymbol{Z}\leftarrow T\,f({\color{blue}\mathbf{C}(\boldsymbol{Z}_{(A)},\boldsymbol{Z}_{(B)})})$$ - c. Hierarchical Attention (Multi-Stream To One-Stream) : 독립적인 stream으로 encoded된 input을 conatenation하는 것
$$\boldsymbol{Z}\leftarrow T\,f_3({\color{blue}\mathbf{C}(T\,f_1(\boldsymbol{Z}_{(A)}),T\,f_2(\boldsymbol{Z}_{(B)}))})$$ - d. Hierarchical Attention (One-Stream To Multi-Stream) : 여러개의 modality들을 concat한 뒤 shared single-stream transformer로 처리하고, 각각 독립적인 stream으로 처리하는 것
$$\left\{
\begin{aligned}
\mathbf{C}(\boldsymbol{Z}_{(A)}, \boldsymbol{Z}_{(B)}) &\leftarrow T\,f_1({\color{blue}\mathbf{C}(\boldsymbol{Z}_{(A)}, \boldsymbol{Z}_{(B)})}), \\
\boldsymbol{Z}_{(A)} &\leftarrow {\color{blue}T\,f_2(\boldsymbol{Z}_{(A)})}, \\
\boldsymbol{Z}_{(B)} &\leftarrow {\color{blue}T\,f_3(\boldsymbol{Z}_{(B)})}.
\end{aligned}
\right.$$ - e. Cross-Attention : two-stream transformer를 통해 K,V,Q를 사용해 분리함으로써 cross-stream transformer형태로 활용하는 것
$$\left\{
\begin{aligned}
\boldsymbol{Z}_{(A)} &\leftarrow MHSA(\boldsymbol{Q}_{\color{blue}B}, \boldsymbol{K}_A, \boldsymbol{V}_A), \\
\boldsymbol{Z}_{(B)} &\leftarrow MHSA(\boldsymbol{Q}_A, \boldsymbol{K}_{\color{blue}B}, \boldsymbol{V}_{\color{blue}B}).
\end{aligned}
\right.$$ - f. Cross-Attention to Concatenation : 위와 같이 처리하고 나서 concatenated해 또 다른 Transformer로 처리하는 것
$$\left\{
\begin{aligned}
\boldsymbol{Z}_{(A)} &\leftarrow MHSA(\boldsymbol{Q}_{\color{blue}B}, \boldsymbol{K}_A, \boldsymbol{V}_A), \\
\boldsymbol{Z}_{(B)} &\leftarrow MHSA(\boldsymbol{Q}_A, \boldsymbol{K}_{\color{blue}B}, \mathbf{V}_{\color{blue}B}), \\
\boldsymbol{Z} &\leftarrow T\,f({\color{blue}\mathbf{C}(\boldsymbol{Z}_{(A)}, \boldsymbol{Z}_{(B)})}).
\end{aligned}
\right.$$

이제 일반적인 Multi-modal Fusion에 대해 살펴보았는데, 이후부터는 Diffusion Model에서의 기존 Conditioning 방법과 Multi-modal을 다루는 방법을 살펴보려고 합니다.
1. Conditioned Generation in Diffusion : Basic
이번엔 T2I Diffusion 모델에서 사용하는 기본적인 Conditioning 기법들을 소개하려고 합니다.
UNet기반의 Diffusion 모델에서 사용했던 Conditioning 기법 위주이지만, 위에 설명한 바와 같이 DiT 모델에 대한 설명에는 Multi-modal Fusion관련된 내용이 섞여 있습니다.
즉, Multi-modal Fusion이 활용되었는지를 떠나 Diffusion 모델에서 쓰이는 Conditioning 방법들을 가볍게 살펴보겠습니다.
a. T2I 모델에서의 기본적인 Condition
먼저, UNet 구조와 DiT구조의 T2I Diffusion 모델에서의 Condition에 대해 살펴보겠습니다.
기본적으로 T2I Diffusion에서 필요한 컨디션은 timestep과 Text입니다.
Stable Diffusion 모델 이전에도 GLIDE, Imagen, Dall-e2 등 다양한 T2I 모델들은 timestep embedding을 처리하기 위해 모두 (sinusoidal → MLP)를 통한 뒤 Diffusion 모델의 residual 경로에 더해지는 feature addition 방법을 활용했습니다.
** 단, Dall-e2는 timestep embedding에 CLIP image embedding projection을 더해줍니다.
또한 GLIDE와 Imagen은 Text Condition을 위해 Cross Attention의 Key & Value를 통해 주입하고, Dall-e2는 Prior로 만든 CLIP image embedding을 context token으로 변환해 Cross Attention의 Key & Value를 통해 주입합니다.
** GLIDE와 Dall-e2에 대해서 궁금하시면 아래 더보기를 참조하세요
--------------------------------------------------------------------------
<Stable Diffusion 이전 모델>
1. GLIDE
** GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models(arxiv’21)
ADM 저자가 만든 T2I Diffusion모델로, 학습시 Text-Conditioned와 Unconditional 두가지를 모두 학습해 CFG를 적용가능하도록 한 모델입니다.
기존 classifier guidance 대신 CFG와 CLIP guidance 각각을 적용해 달라진 결과를 만들었으며, 각각의 기법들은 아래와 같습니다.
- Classifier guidance : $\hat{\mu}_\theta(x_t|y)=\mu_\theta(x_t|y)+s\cdot\sum_\theta(x_t|y)\bigtriangledown _{x_t}logp_\phi(y|x_t)$
- CFG(Classifier-Free guidance) : $\hat{\epsilon}_\theta(x_t|c)=\epsilon_\theta(x_t|\varnothing )+s\cdot(\epsilon_\theta(x_t|c)-\epsilon_\theta(x_t|\varnothing ))$
- CLIP guidance : $\hat{\mu}_\theta(x_t|c)=\mu_\theta(x_t|c)+s\cdot\sum_\theta(x_t|c)\bigtriangledown _{x_t}(f(x_t)\cdot g(c))$
이중 CLIP guidance의 경우 Classifier guidance의 기존 식의 classifier를 CLIP로 대체한 방법이며, 64x64 ViT-L CLIP모델을 활용했습니다.
또한 CFG를 위해서는 text-conditional DM($p(x_{t-1}|x_t,c)$)을 만들어야하는데, 이때 기존 Ablated-UNet에 text conditioning을 아래와 같이 독특하게 했습니다.
- 먼저 텍스트를 tokenize합니다.
- Transformer 모델을 통해 token embedding을 만들어냅니다.
** 이 embedding은 ADM의 class embedding으로 활용되기도 합니다. - Ablated-Unet의 각각의 attention layer의 input 차원으로 project합니다.
- Ablated-Unet의 각각의 attention layer의 context에 concat해줍니다.
결과적으로는 CFG가 Human Evaluation에서 좋은 성능을 보였다고 합니다.
2. Dall-E2
** [Dall-e2] Hierarchical text-conditional image generation with clip latents(arxiv’22)
** [Dall-e3] Improving Image Generation with Better Caption(OpenAI'23)
CLIP을 활용한 2-stage 모델이며 unCLIP이라고 부릅니다. 단계는 아래와 같습니다.
- Stage1. frozen CLIP을 활용해 text를 기반으로 image embedding을 얻어냅니다.
- Stage2. 학습된 Prior 모델 ($P(z_{image}|text)$)을 활용해 image embedding을 prior로 만들어줍니다.
- Stage3. 학습된 Decoder ($P(output|z_{image},text)$)이 해당 prior을 condition으로 이미지를 생성합니다.
- Stage4. upsampler를 활용해 high resolution 이미지를 얻어냅니다.
위 각각의 단계에서의 모델들을 살펴보겠습니다.
<Stage1. CLIP>
먼저 CLIP을 살펴보면, 256x256 이미지를 활용하는 ViT-H/16 이미지 encoder와 causal attention mask를 활용하는 transformer를 텍스트 encoder로 사용합니다.
본 논문에서는 직접 CLIP을 학습해 사용하지만, prior모델과 decoder모델을 학습시에는 freeze하며, SAM과 함께 학습하면 CLIP representation의 rank를 줄일 수 있을 뿐 아니라, 성능도 향상했다고 합니다.

<Stage2. Prior Model>
다음으로 Prior모델을 살펴보면, 캡션 텍스트로부터 만들어낸 CLIP Image embedding을 얻은 뒤, Text를 컨디션으로 아래와 같은 두가지 prior model을 동시에 사용해 prior를 얻어냅니다.
- AR(Autoregressive) prior : 아래와 순서와 같이 Discrete한 코드의 시퀀스로 Autoregressive하게 얻어 냅니다.
- 효율적인 학습을 위해 CLIP Image embedding에 PCA를 적용해 319 dimension을 만들고
- 319 dimension을 1024개의 discrete buckets에 quantize합니다.
- causal attention mask를 활용하는 transformer를 활용해 autoregressive하게 적용해 prior를 만들어냅니다.
- (condition) 위 AR prior 모델은 Text에 condition을 주도록 만들었는데, (Text caption, CLIP text embedding)을 위 sequence의 prefix로 붙여주었을 뿐 아니라, CLIP text embedding과 image embedding간의 내적 결과 토큰도 prepend해주었습니다.
- Diffusion prior : 직접적으로 DM을 사용해 얻어냅니다.
- (Encoded Text, CLIP text embedding, diffusion timestep, noised CLIP image embedding, DM noise) 시퀀스에 대해 causal attention mask를 활용하는 Transformer의 decoder를 통과해 주었습니다.
- 위 결과 중 DM noise 부분은 noised CLIP image embedding을 unnoised하기 위한 방법으로 쓰입니다.

<Stage3. Decoder Model>
다음으로 Decoder모델은 GLIDE의 모델을 아래와 같이 수정해 활용하며, Cross-Attention 주입 전의 feature들을 변경해줍니다.
- CLIP embedding을 기존의 timestep embedding에 projection& add
- CLIP embedding을 4개의 extra token으로 변환한 뒤, GLIDE의 text encoder의 결과에 concat해줍니다.

앞서 GLIDE에서 이미 text정보를 반영했음에도 불구하고 또 condition을 진행하는 이유는 CLIP에서 잡아내지 못한 다양한 binding feature를 보완하기 위함이었으나 그렇게 도움이 되지는 않았다고 합니다.
<Stage4. Upsampler>
마지막으로 upsampler는 Ablated UNet을 활용합니다.
(64x64 → 256x256), (256x256 → 1024x1024)두개의 upsampler를 학습하며, 이 때 caption에 대해 condition을 주는 것의 이득이 없어 unconditional 하게 진행합니다.
upsampling하기 전에 preprocessing으로 Gaussian Blur를 처리해준 뒤, BSR-degradation을 진행합니다.
**BSR-degradation(Blind image Super Resolution) : LDM에서 High Resolution(HR)을 Low Resolution(LR)으로 바꿔주는 degradation pipeline으로, 이미지에 다양한 방법들을 랜덤 순서로 처리해줍니다.
** Designing a practical degradation model for deep blind image super-resolution (arxiv'21)
--------------------------------------------------------------------------
그럼 Stable Diffusion 모델은 어떨지 살펴보겠습니다.
아래는 SDXL의 전체 구조입니다.
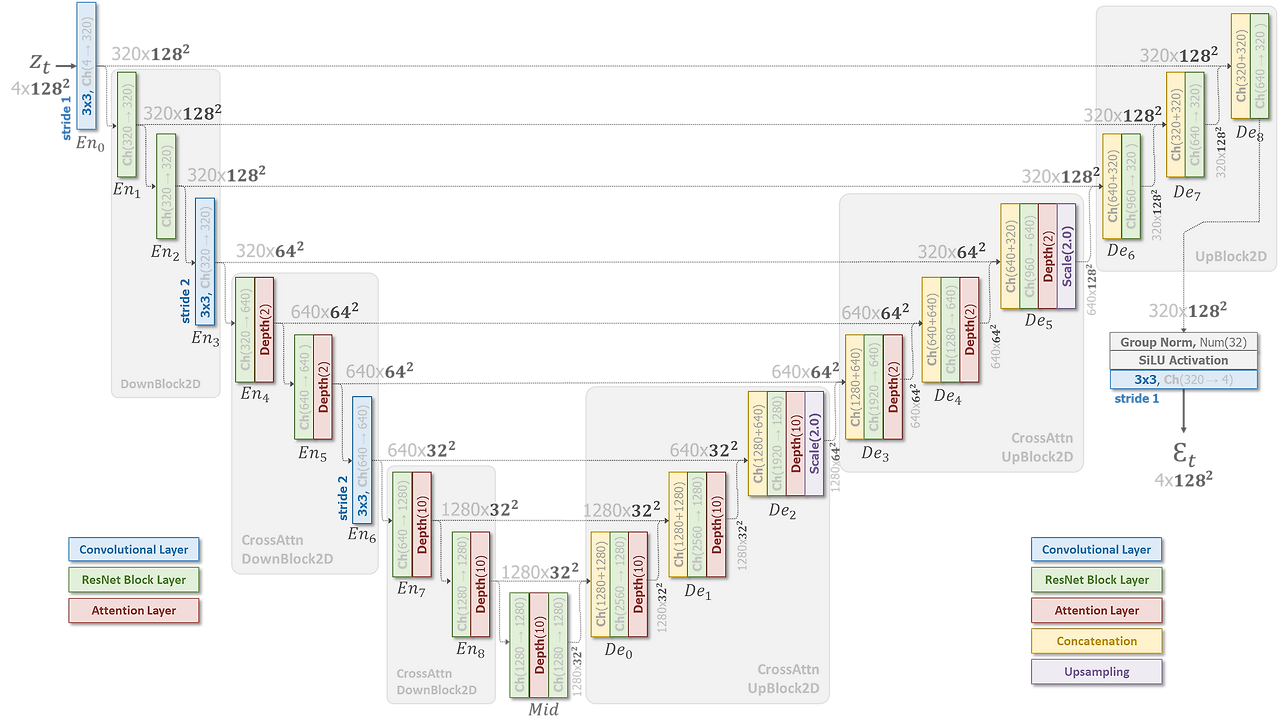
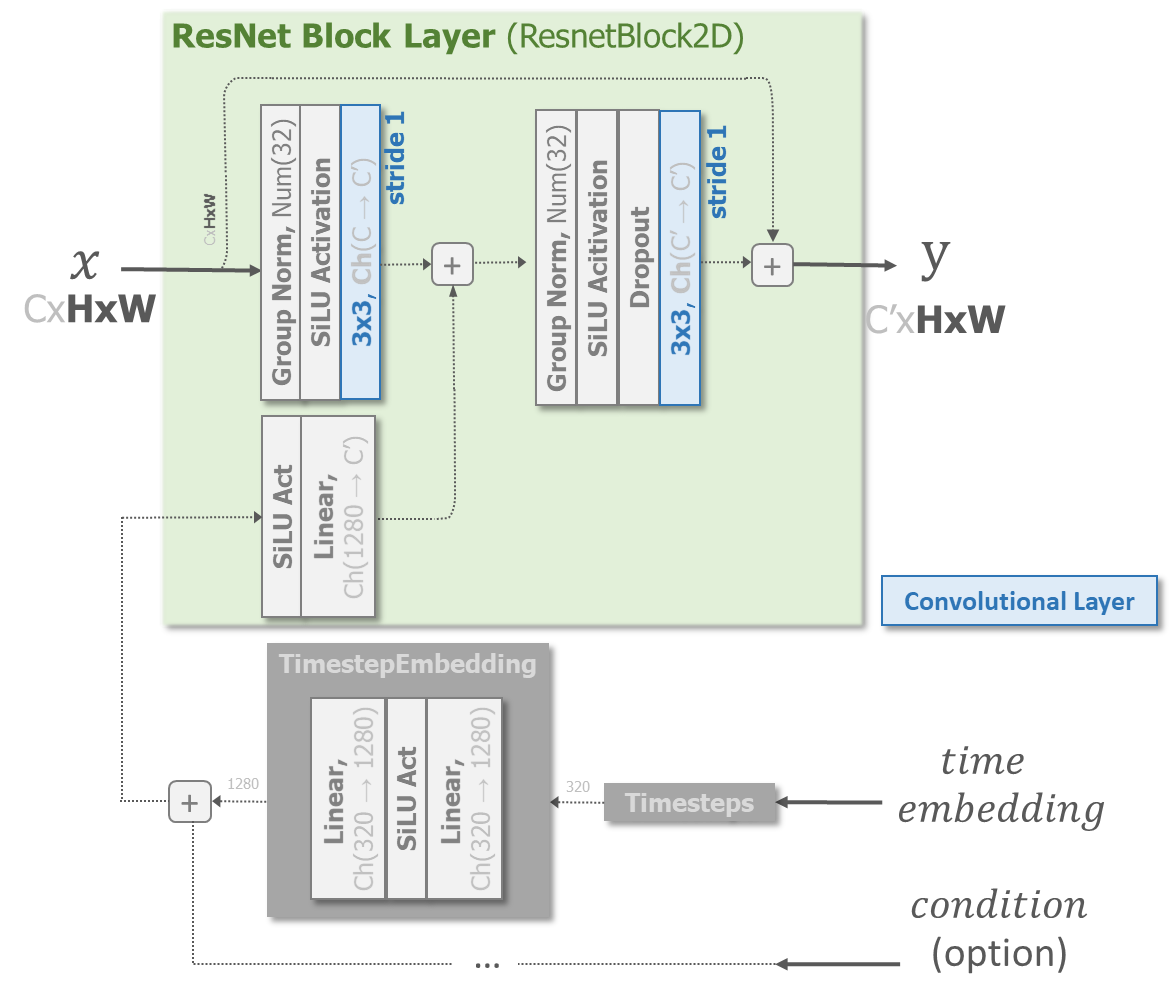
이 중에 ResNet Block에 대해 자세히 살펴보면 아래와 같습니다. 즉, time embedding은 이전과 같이 (sinusoidal → MLP)을 통한 뒤 feature addition을 통해 더해집니다.
다음으로, Attention Layer에 대해 자세히 살펴보면 아래와 같습니다. 즉, Text Condition은 이전과 같이 Cross Attention을 통해 퓨전됩니다.

정리하면 아래와 같습니다.
- Fusion Method(timestep embedding) : feature addition
- Fusion Method(text condition) : Key& Value of cross-attention
다음으로, UNet기반 Diffusion 모델들 이후 DiT(Diffusion Transformer)가 등장했는데, 이는 아래와 같은 다양한 컨디션을 실험해보았습니다.
** [DiT] Scalable Diffusion Models with Transformers (ICCV'23)
- AdaLN Block(Adaptive Layer Norm Block) : 이전에 제안된 Adaptive Normalization을 활용하면, scale 파라미터인 $\gamma$와 shift 파라미터인 $\beta$를 regress해서 활용해 condition을 줄 수 있습니다.
** [AdaLN] FiLM: Visual Reasoning with a General Conditioning Layer (AAAI'18)
** AdaIN(Adaptive Instance Normalization)과 다릅니다 - AdaLN-Zero Block : 기존 AdaLN Block에 더해, residual connection과 더해주기 전에 $\alpha$라는 scaling 파라미터를 통해 더해주는 방법입니다.
- 타 논문에 따르면, 각 block의 마지막 batch norm scale factor인 $\gamma$를 zero-initialization하면 학습이 잘되었다는 것을 발견했습니다.
** Accurate, large minibatch sgd: Training imagenet in 1 hour (arxiv’17) - 추가적인 scaling 파라미터 $\alpha$를 학습해 DiT block내의 residual connection 앞에 적용해주었습니다.
- 타 논문에 따르면, 각 block의 마지막 batch norm scale factor인 $\gamma$를 zero-initialization하면 학습이 잘되었다는 것을 발견했습니다.
- Cross-Attention Block : 기존 Transformer 혹은 LDM에서와 같이 Transformer block 내 multi-head cross attention layer에서 class를 사용하는 방법입니다. 이는 15%의 overhead를 발생한다고 합니다.
- In-Context Conditioning (Prepend): 단순히 time이나 condition을 위한 vector embedding을 input sequence에 concat해주는 방법입니다. ViT의 cls 토큰과 같으며, 마지막 Transformer block을 통과한 후에는 토큰을 없애줍니다.
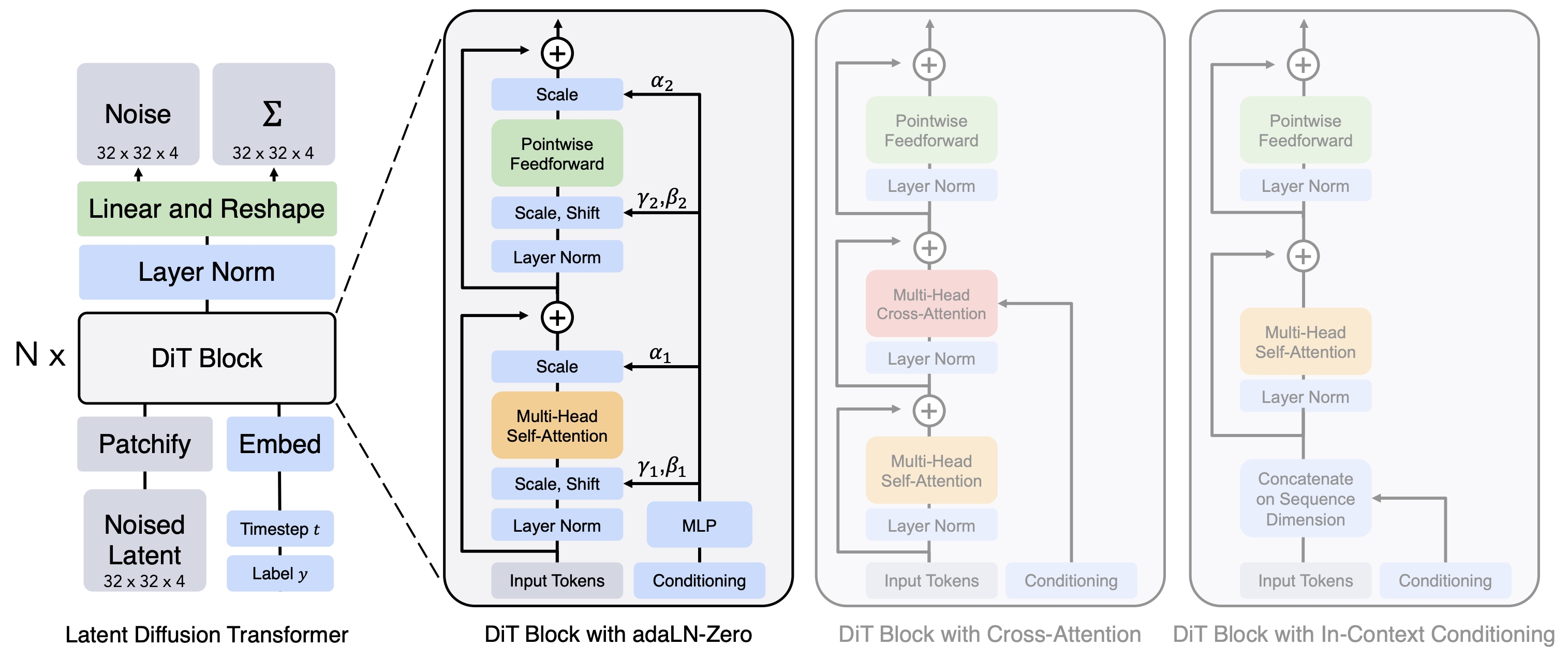
결과적으로 AdaLN-Zero가 가장 성능이 좋았으며, 이에 따라 timestep embedding은 역시나 이전과 같이 (sinusoidal → MLP)을 통한 뒤 AdaLN을 통해 들어가게 되었습니다.
단, DiT가 처음 등장했을 때는 text condition이 없는 순수 class-conditional 또는 unconditional 모델이며, class는 timestep과 함께 AdaLN conditioning으로 들어갑니다.
정리하면 아래와 같습니다.
- Fusion Method(timestep embedding) : Feature-wise modulation
- Fusion Method(class condition) : Feature-wise modulation
마지막으로 Stable Diffusion 3.0에서도 활용되었으며, DiT를 활용한 구조인 MMDiT는 아래와 같은 구조로 동작합니다.
** [MM-DiT] Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (ICML'24)

즉, 정리하면 아래와 같습니다.
- Fusion Method(timestep embedding) : Feature-wise modulation
- Fusion Method(text condition) : Feature-wise modulation, Input Concatenation, Self-Attention
timestep은 AdaLN을 활용해 주입되며, Text Condition은 한쪽으론 timestep과 addition되어 주입되고 또 한편으론 Attention에 latent와 concat되어 입력됩니다.
이는 뭔가 확실히 Multi-modal fusion 형태의 등장이라고 부를 수 있을 것 같습니다.
b. ControlNet
** Adding Conditional Control to Text-to-Image Diffusion Models (ICCV’23)
- Fusion Method : feature 간의 Addition
- Main Target Modality : Structural한 정보 (Edge, Line Drawings, User Scribbles, Normal Map 등)

ControlNet은 아래와 같이 기존의 pretrained UNet 구조를 그대로 두고 동일한 구조의 UNet 복사본을 두되 그 내부 피처들을 base UNet에 더해주는 방식이며, 데이터셋이 적은 경우(< 50k)에도 학습이 robust하고 빠르게 학습할 수 있습니다.
- 기존에 학습된 DM을 trainable copy와 locked copy로 구분합니다.
이 중 trainable copy는 control을 위해 학습되며, locked copy는 freeze됩니다. - 위 두가지는 zero convolution으로 연결되는데, zero convolution은 단순히 convolution의 weight가 0으로 초기화되는 convolutional layer입니다.
** Gaussian 초기화 방법이 덜 riskey하지만, improved-DDPM에서 DM에서 학습을 최적화하기 위해 zero module이라는 방법으로 weight를 0으로 초기화한 것에 모티브를 받았다고 합니다.
위 설명된 구조를 조금 더 자세히 살펴보겠습니다.
아래 그림&식과 같이 Network Block들을 locked copy와 trainable copy로 분리한 뒤, 앞 뒤의 zero convolution을 통해 더해집니다.
- 적용 전 : $y=F(x;\theta )$
- $\theta $ : locked copy의 weight
- 적용 후 : $y_c=F(x;\theta) + Z(F(x+Z(c;\theta _{z1});\theta _c);\theta _{z2})$
- $\theta _{z1}$ : trainable copy 앞에 적용되는 zero convolution의 weight
- $\theta _{c}$ : trainable copy
- $\theta _{z2}$ : trainable copy 뒤에 적용되는 zero convolution의 weight

이 때 zero convolution은 1x1 convolutional layer로 구성되는데, 단순히 식으로 나타내면 아래와 같습니다. 이미지 $I$의 spatial한 (포지션 p, 채널 c)에 대해 Output 채널 $i$만큼 진행합니다.
$$Z(I;{W,B})_{p,i} = B_i + \sum_{j=1}^{c}I_{p,i}W_{i,j}$$
위를 Stable Diffusion에 적용해 보겠습니다.
먼저 U-Net의 구조는 아시다시피 아래와 같이 25개의 block으로 구성됩니다.
- Encoder : 12 blocks
** 3개의 block마다 각각 (64x64, 32x32,16x16, 8x8)의 resolution을 가집니다. - Middle block : 1 block
- Skip-connected decoder : 12 blocks
- Text : CLIP encoder
SD에서 사용하는 VAE encoder $\varepsilon $는 ControlNet으로 들어갈 condition image도 latent space로 변경해줍니다. (512x512 -> 64x64)
** VAE Encoder : 각각 채널이 16,32,64,128인 4개의 {4x4 convolutional layer(2 stride)+ ReLU}
이 때 ControlNet은 Encoder 12block과 middle block 1block만을 copy해 trainable copy를 구성하며, 각각의 block은 skip으로 후에 zero convolution을 통해 locked copy에 더해집니다.

ControlNet이 적용되었을 때, 기존 DM의 weight는 freeze되기 때문에 gradient를 계산하지 않아도 되므로, 학습할 때 메모리를 23%만 더 사용하며, 학습 iteration 시간 또한 34%만 늘어 효율적이라고 합니다.
또한 이들을 학습시에는 학습 데이터 prompt $c_t$의 50%를 empty strings으로 주었는데, 이는 input condition에 의한 semantic 변화를 관찰하기 위함이라고 합니다.
그리고 저성능 device로 학습시에는 middle block만 zero convolution을 통해 연결해 빠른 convergence를 만들었고, 반대로 Large-scale 학습시에는 모두 연결해 학습하되 학습 후에 SD의 weight까지 unlock해 같이 학습하기도 했다고 합니다.
추가적으로 아래와 같은 CFG가 있을 때, ControlNet은 $\epsilon _{uc}$와 $\epsilon _{c}$에 모두 반영하거나 $\epsilon _{c}$에만 반영할 수 있습니다.
$$\begin{matrix}
\epsilon _{prd} &=& \epsilon _{uc} + \beta _{cfg}(\epsilon _c - \epsilon _{uc})\\
&&\epsilon _{uc}:unconditional\ output\\
&&\epsilon _{c}:conditional\ output
\end{matrix}$$
prompt가 없는 상황에서, 위 전자의 경우 아래 그림 (b)와 같이 CFG guidance의 효과가 사라졌으나, 위 후자의 경우 CFG Guidance가 오히려 아래 그림 (c)와 같이 굉장히 커졌다고 합니다.

하지만 결과적으로 본 논문은 $\epsilon _{c}$에만 condition을 주되, ControlNet의 zero convolution을 통한 값들이 SD에 더해지기 전에 weight $w_i$를 곱해진 후 더해지도록 했고, 오히려 더 좋은 위 (d)와 같은 결과를 얻었다고 합니다.
이 때 $w_i$는 아래 식과 같은데, 이 때 $h_i$는 i번째 block의 resolution(8,16,…64)을 의미합니다.
$$w_i=64/h_i$$
이번엔 SD를 여러개의 ControlNet과 연결하는 경우(Multi-ControlNet), SD모델에 직접적으로 weighting이나 linear interpolation없이 모두 더해주어도 잘 동작했다고 합니다.
이렇게 구현된 ControlNet을 활용해 아래와 같은 다양한 condition에 적용 가능합니다.
- Edge : Canny edges, Hough lines, HED, M-LSD
** HED : Holistically-nested edge detection (ICCV'15)
** M-LSD : Towards light-weight and real-time line segment detection (AAAI'22)
- Line Drawings : Anime2sketch
** Anime2sketch: A sketch extractor for anime arts with deep networks (github'21) - User Scribbles : HED boundary detection
- Line Drawings : Anime2sketch
- Human Key Points (pose) : Openpifpaf, Openpose
** OpenPifPaf: Composite Fields for Semantic Keypoint Detection and Spatio-Temporal Association (ITSS'21)
** Openpose: Realtime multi-person 2d pose estimation using part affinity fields (TPAMI'19) - Segmentation maps : COCO dataset, ADE20k dataset
- Masked Image
- Object shape / Normal map : DIODE dataset, MiDaS를 활용
** Normal Map Texture Image : 물체의 Normal(수직 벡터)정보를 텍스쳐 이미지 형태의 저장공간에 저장해 둔 파일
** Texture Map : 그림(https://velog.io/@rageboom/WebGL-%ED%85%8D%EC%8A%A4%EC%B2%98) 설명 - depths : MiDaS를 활용
** MiDaS : Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer (TPAMI’20)

위는 UNet 구조에 적용된 예시인데, DiT에도 적용이 가능합니다.
** PixArt-δ: Fast and Controllable Image Generation With Latent Consistency Models (arxiv'24)

c. T2I-Adapter
** T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models(AAAI’24)
- Fusion Method : feature 간의 Addition
- Main Target Modality : Structural한 정보 (Depth, Keypoint, Segmenation Map 등)

T2I Adapter는 CNN을 통과한 condition feature를 UNet의 각 블록에 modulation 방식으로 추가하는 방식입니다. 대부분 Residual Block 단에서 scale, shift 형태로 적용됩니다.
즉, light-weight 모델이자 어댑터를 활용하는 방법인데, pre-trained T2I모델의 internal knowledge를 외부 control에 align하는 역할을 합니다.
T2I Adapter는 아래와 같은 특징을 가집니다.
- Plug-and-play : 기존 network에 영향을 끼치지 않고, plug-and-play가 가능합니다.
- Simple & small : ~300MB의 ~77M개 파라미터 뿐인 lightweight adapter이기 때문에 적은 training cost를 가지고 학습이 가능하며, inference과정에서 adapter는 한번만 수행해도 되므로 효율적입니다.
- Flexible : 다양한 condition에 대해 학습이 가능합니다.
- Composable : 하나 이상의 adapter들이 함께 composed 되어 multi-condition control이 가능합니다.
- Generalizable : 한번 학습되면, 다른 custom model에서도 사용가능합니다.
구조를 조금 자세히 살펴보겠습니다.
먼저 T2I Adapter $\mathcal{F}_{AD}$의 구조는 아래와 같습니다.
input condition은 512x512이며, 4개의 Feature extraction block과 3개의 Downsample block으로 이루어져 있습니다.

위에서 Pixel unshuffle은 64x64차원으로 한번 downsample하는 역할을 하며, 하나의 Feature extraction block은 {1개의 Conv layer와 2개의 Residual Block(RB)}로 이루어져있습니다.
** pixel unshuffle : Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network (CVPR’16)
결과적으로 위와 같은 Adapter를 통과하면 $F_c=\begin{Bmatrix}F^1_c, F^2_c, F^3_c, F^4_c\end{Bmatrix}$형태의 여러개의 스케일을 가지는 Condition Feature가 나오는데, 이들은 UNet의 encoder의 중간 feature scale {64,32,16,8}과 같으므로, 이후에 아래 식&그림과 같이 더해집니다.
$$\begin{matrix}
F_c&=&\mathcal{F}_{AD}(C)&\\
\hat{F}_{enc}&=&F^i_{enc}+F^i_c&when\ i\in \begin{Bmatrix}1,2,3,4\end{Bmatrix}\\
\end{matrix}$$

이제 위와 같은 T2I Adapter는 아래와 같은 컨디션으로 활용됩니다.
- Structure Controlling : Sketch, Depth map, Semantic Segmentation map, keypose
- Spatial color palette : hue와 spatial distribution을 제공하기 위해서 bicubic downsampling을 64x로 해 semantic & structural한 정보를 모두 지운 다음, 다시 64x로 nearest upsampling을 진행해 아래 그림과 같이 데이터를 만들어낼 수 있습니다.
- Multi-adapter controlling : 여러개의 condition을 주기 위해 따로 학습이 필요하지는 않습니다. 단지 아래 수식과 같이 여러개의 T2I adapter에 weight를 주어 더해줍니다.
** K는 K개의 guidance(condition) 종류를 의미합니다.
$$\begin{matrix}
F_c&=&\sum_{k=1}^{K}\omega _k\mathcal{F}^k_{AD}(C_k)\\
&&w_k : adjustable\ weight
\end{matrix}$$

이번엔 학습 과정은 간단하게 보겠습니다.
학습은 SD를 freeze하고 T2I-adapter만 학습을 진행합니다. 학습은 이미지 {$X_0$, condition map $C$, text propt $y$} 3개의 triplet으로 진행되며, loss는 SD를 학습할 때와 같습니다.
추가적으로, time embedding을 T2I adapter에도 더해주는 것이 gudiance 역량을 올려주긴했다고 합니다.
하지만, Inference 과정에서 여러번 계산해야되는 단점이 생길 뿐 아니라, 사용하지 않아도 time step을 early sampling stage ($t\approx T$)에서 더 많이 학습되도록 아래 식과 같이 non-uniform sampling(cubic sampling)을 통해 학습했더니 성능이 보완되었다고 합니다.
** Early Stage($t\approx T$)에서 condition이 더욱 잘 반영됩니다.
$$t=(1-(\frac{t}{T})^3)\times T,\ when\ t\in U(0,T)$$
d. IP-Adapter
** IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models (arxiv'23)
- Fusion Method : feature 간의 Cross-Attention
- Main Target Modality : Image (Reference style, Reference content)
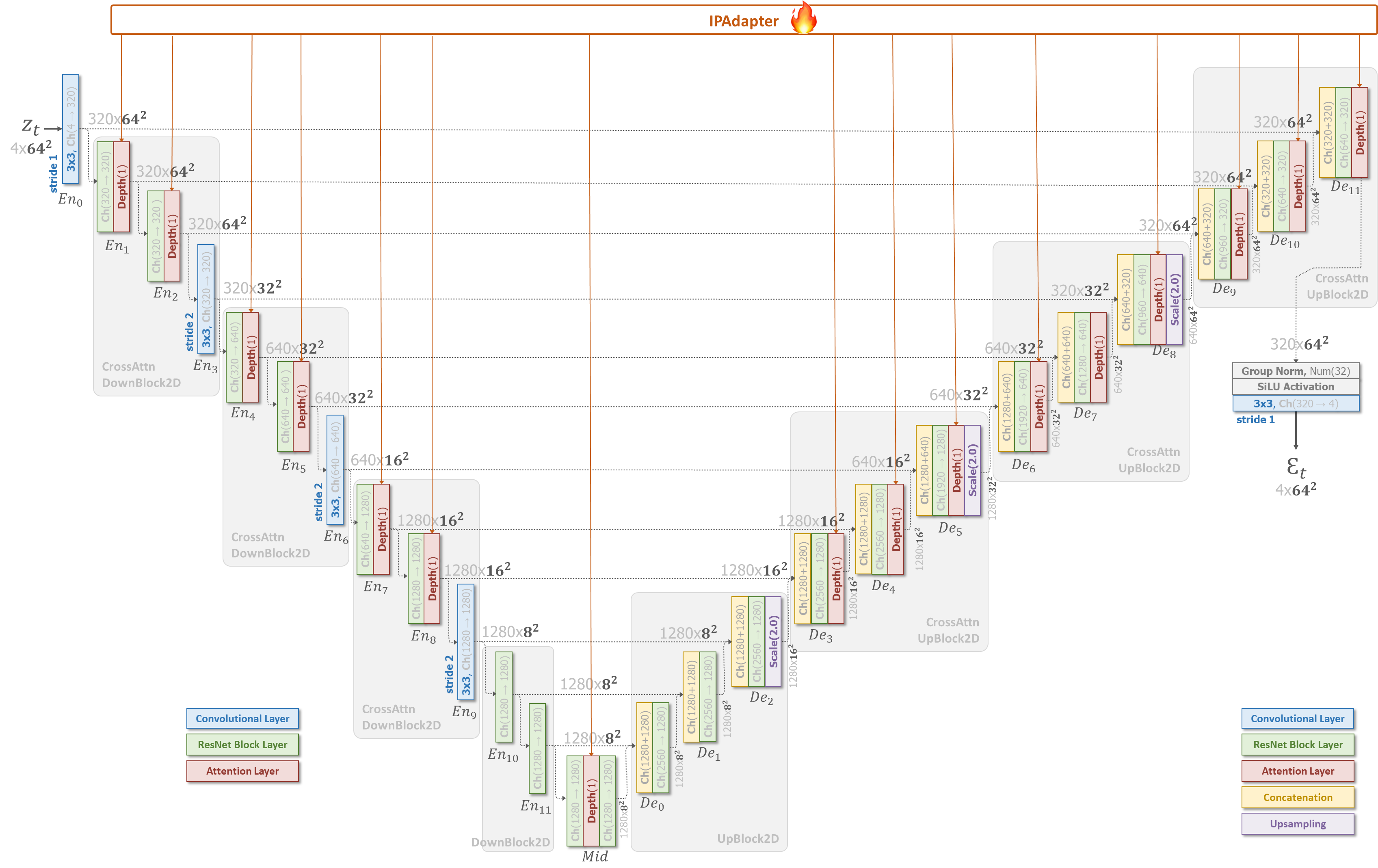

IP-Adapter는 CLIP 이미지 임베딩을 UNet의 cross-attention의 Key&Value로 기존의 텍스트 condition과 함께 넣어주는 방법입니다.
기존에 Uni-ControlNet 어댑터는 structural feature를 text feature와 concat한 뒤 U-Net에 merge해 이미지 정보를 제공했는데, 역시나 fine-tuned 모델보다는 생성된 이미지가 성능이 좋지 않았다고 합니다.
본 논문에서는 이에 대한 원인이 cross-attention layer가 text feature에 적합하게 학습되어 있는데, merge된 이미지와 텍스트의 feature를 함께 넣어 cross-attention을 통과하니 이미지-specific한 정보를 놓치게 되는 것이라고 합니다.
따라서 본 논문에서는 기존의 T2I모델을 변경하지 않으면서, lightweight Adapter를 통해 이미지 프롬프트를 제공할 수 있는 방법을 제안합니다.
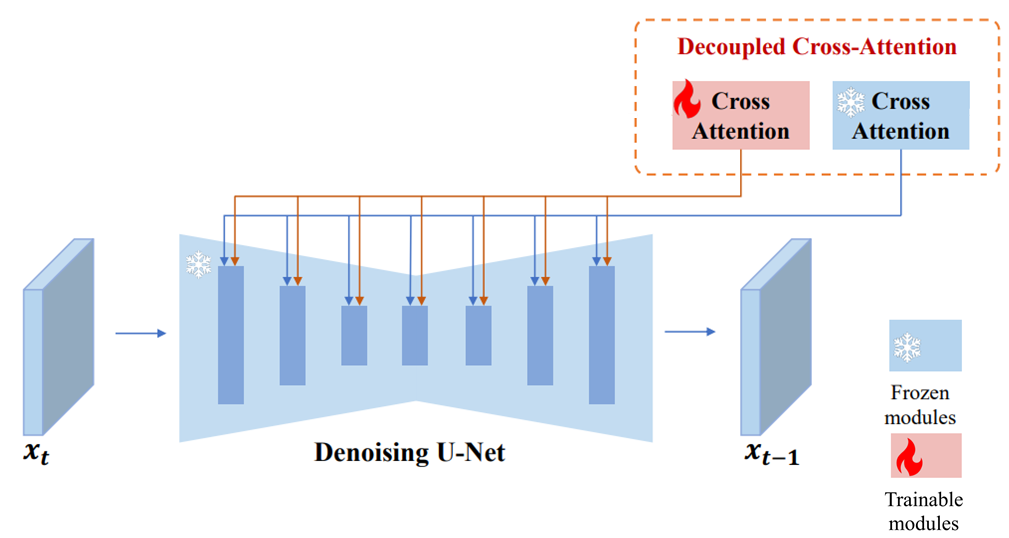
즉, decoupled 된 cross-attention을 활용해 text feature와 image feature를 분리하고, 추가적으로 image feature를 위한 cross attention을 추가한 IP-Adapter를 소개합니다.
구조를 살펴보겠습니다.
먼저 Image Encoder로는 CLIP을 활용하며, 아래 그림과 같이 이미지 임베딩을 학습 가능한 작은 projection 네트워크를 통해 텍스트 임베딩과 같은 길이의 feature sequence로 바꿔 각각의 Cross Attention으로 넣어줍니다.

이후 각각의 Cross Attention은 decoupled 되어 아래 식과 같이 동작합니다.
$$Z^{new}=Softmax(\frac{QK_{text}^\top }{\sqrt{d}})V_{text}+Softmax(\frac{QK_{image}^\top }{\sqrt{d}})V_{image}$$
또한 이들을 학습할 때는 기존 UNet모델과 CLIP encoder는 아래 그림과 같이 freeze되어 학습되고, 오로지 새로운 이미지를 받아 처리할 Image Encoder와 $K_{image},V_{image}$를 만들기 위한 Cross Attention의 weight matrices $W^K_{image},W^V_{image}$만 학습하게 됩니다.
2. How to utilize modality?
여기까지 Diffusion Model에서 기존에는 Conditioning을 위해 어떤 방식을 활용했는지 기본적인 것들을 살펴보았습니다.
이번엔 필자가 최근에 본 SOTA 논문 중에 Multi-Modality를 다루기 위해, 모델의 어떤 특징들을 활용하는 경우가 있는지에 대한 예시를 보이려고 합니다.
Multi-Modal Fusion 자체를 다루는 모델 구조일 수도 있겠지만, 기존 UNet기반의 Diffusion과 같은 Conditioning 구조에서도 Modality를 어떻게 다루었는지를 포함해 구성해보았습니다.
a. (UNet) 1Prompt1Story
** One-Prompt-One-Story : Free-Lunch Consistent Text-To-Image Generation using a Single Prompt (ICLR'25)
- Fusion Method : feature 간의 Cross-Attention
- Main Target Modality : Text
- Focus : Text Embedding에서 특정 토큰을 강조하는 방법과 Cross Attention에서 특징을 강조하는 방법
먼저 N개의 아래와 같은 프롬프트 $\mathcal{C}$가 존재합니다.
** $M:[{\color{blue}c_{[SOT]}},\dots,|P|\times {\color{blue}c_{[prompt]}}\,\dots,(M-|P|-1)\times {c_{\color{blue}[padding]}},\dots,{\color{blue}c_{[EOT]}}]$ : token의 총 개수
** $D$ : 각 token의 dimension
** $\tau_{\xi}(\cdot)$ : CLIP text encoder
$$\begin{aligned}
P_i&\,\,,i\in [1,N]\\
\mathcal{C} &= \tau_{\xi}(P) \in \mathbb{R}^{M \times D}\\
\end{aligned}$$
이중에 $P_0$는 핵심 subject를 설명하는 identity prompt이고, 나머지 $P_i(i=1,\dots,N)$는 각 프레임의 시나리오를 의미하는데, 기존 T2I 모델은 아래와 같이 identity prompt를 공유하면서 생성합니다.
(Multi-prompt Generation)
$$\mathcal{C}_i= \tau_{\xi}([P_0;P_i])=[{\color{blue}c_{[SOT]}},{\color{blue}c_{P_0}},{\color{blue}c_{P_i}},{\color{blue}c_{[EOT]}}],\,(i=1,\dots,N)$$
하지만 이런 분리된 프롬프트로는 storytelling을 위해 identity를 유지하는 등 context consistency를 반영하며 생성되기 어렵습니다.
기존에 LM 자체에 내제되었던 context consistency는 Transformer구조의 Text Encoder가 사용하는 “self-attention”덕분에 가능할 수도 있기 때문에, 이를 활용하기 위해 본 논문에서는 아래와 같이 모든 프롬프트를 한번에 concat해 생성하는 방법을 제안합니다.
(PCon, Prompt Consolidation=Single Prompt Generation)
$$\mathcal{C}= \tau_{\xi}([P_0;P_1;\dots;P_N])=[{\color{blue}c_{[SOT]}},{\color{blue}c_{P_0}},{\color{blue}c_{P_1}},\dots,{\color{blue}c_{P_N}},{\color{blue}c_{[EOT]}}]$$
아래 그림은 위 Multi-Prompt Generation(빨간색)과 Single-Prompt Generation(파란색) 케이스에 대해 각각 frame prompt의 임베딩인 ${\color{blue}c_{P_i}}$를 t-SNE로 2D 형태로 나타낸 결과입니다.

실제 결과적으로 Single-Prompt 방법을 활용했을 때에 더 적은 L2 distance를 보였고, 결과적으로 frame prompt간에 조금 더 의미론적인 정보를 identity consistency를 유지하며 동작할 수 있었다고 결론짓습니다.
이번엔 위 활용한 Text Embedding으로 이미지를 생성한 후 image space를 살펴보는데, 먼저 방법론적으로 Multi-prompt Generation의 경우는 위와 같이 하면됩니다.
하지만 Single-prompt Generation의 경우 i번째 frame을 생성할 때 ${\color{blue}c_{P_i}}$를 magnification factor로 reweight하고 나머지를 reduction factor로 rescale합니다.
(NPR : Naive Prompt Reweighting)
그 결과 아래 그림을 보면, NPR에서는 더욱 같은 subject identity를 가지고 생성하게 되었습니다. 하지만 background에 대한 정보가 frame간에 서로 섞인 결과가 나온다고 합니다.

따라서 이에 추가적으로 아래와 같은 작업을 진행합니다.
a. SVR(Singular-Value Reweighting)

위에서 언급된 바와 같이 아래와 같은 Prompt Consolidation이 있을 때,
$$\mathcal{C}= \tau_{\xi}([P_0;P_1;\dots;P_N])=[{\color{blue}c_{[SOT]}},{\color{blue}c_{P_0}},{\color{blue}c_{P_1}},\dots,{\color{blue}c_{P_N}},{\color{blue}c_{[EOT]}}]$$
현재 현재 생성에서 잘 표현되어야 하는 $\mathcal{X}^{exp}$와 억압되어야하는 $\mathcal{X}^{sup}$는 아래와 같이 분류 됩니다.
이때 [EOT] 토큰은 타 논문에서 언급된 바와 같이 semantic한 중요 정보를 담고 있기 때문에 $\mathcal{X}^{exp}$에 포함됩니다.
- $\mathcal{X}^{exp}=[{\color{blue}c_{P_j}},{\color{blue}c_{[EOT]}}]$
- $\mathcal{X}^{sup}=[{\color{blue}c_{P_1}},\dots,{\color{blue}c_{P_{j-1}}},{\color{blue}c_{P_{j+1}}},\dots,{\color{blue}c_{P_{N}}},{\color{blue}c_{[EOT]}}]$
** Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models (ICLR’23)
** Relation rectification in diffusion model (CVPR’24)
** Token merging for training-free semantic binding in text-to-image synthesis (NIPS’24)
** [Padding 영역 포함] Padding Tone-Revealing the role of the padding tokens in T2I Models (arxiv’25)
** [Padding 영역 포함] Magnet: We Never Know How Text-to-Image Diffusion Models Work, Until We Learn How Vision-Language Models Function (NIPS’24)
** [Padding 영역 포함] Training-free structured diffusion guidance for compositional text-to-image synthesis (arxiv’22)
** [Padding 영역 포함] Get what you want, not what you don’t: Image content suppression for text-toimage diffusion models (arxiv’24)
먼저 $\mathcal{X}^{exp}$를 아래와 같이 SVD decomposition하면 아래와 같이 signular 값들로 구성된 Diagonal Matrix $\Sigma$가 만들어집니다.
** SVD에 대해 궁금하시면 아래 더보기를 참조하세요
$$\begin{aligned}
\mathcal{X}^{exp}&=U\boldsymbol{\Sigma}V^\top\\
\boldsymbol{\Sigma}&=diag(\sigma_0,\sigma_1,\cdots,\sigma_{n_j})\quad when\,\,\sigma_0\geq\cdots\geq\sigma_{n_j}
\end{aligned}$$
--------------------------------------------------------------
<Singular Value(특이값)과 Eigen Value(고유값)의 차이>
먼저 고유값(Eigen Value)와 고유벡터(Eigen Vector)는 정방행렬 $A$에 대해 아래 식을 만족하는 ${\color{red}\lambda}$를 eigen value, {\color{blue}\boldsymbol{x}}를 eigen vector라고 합니다.
$$(A-{\color{red}\lambda}I){\color{blue}\boldsymbol{x}}=0$$
즉, 선형변환 $A$에 대해, 고유벡터는 “방향은 보존되고 스케일만 변화되는 방향벡터”를 의미하고, 고유값은 “고유벡터의 변화되는 스케일 정도”를 나타냅니다.
모든 정방행렬은 아니지만, 고유값과 고유벡터는 정방행렬을 대각화하여 표현 할 수 있기도 합니다.
예를 들어 정방행렬 $A$에 대해 아래와 같은 고유값과 고유벡터들이 있을 때,
$$\begin{aligned}
A\mathbf{v}_1 = \lambda_1 \mathbf{v}_1\\
A\mathbf{v}_2 = \lambda_2 \mathbf{v}_2\\
\vdots\\
A\mathbf{v}_n = \lambda_n \mathbf{v}_n\\
\end{aligned}$$
아래와 같이 표현할 수 있고
$$\begin{aligned}
A \begin{bmatrix} \mathbf{v}_1 & \mathbf{v}_2 & \cdots & \mathbf{v}_n \end{bmatrix}
=& \begin{bmatrix} \lambda_1 \mathbf{v}_1 & \lambda_2 \mathbf{v}_2 & \cdots & \lambda_n \mathbf{v}_n \end{bmatrix}\\
=& \begin{bmatrix} \mathbf{v}_1 & \mathbf{v}_2 & \cdots & \mathbf{v}_n \end{bmatrix}
\begin{bmatrix}
\lambda_1\quad & 0 & \cdots & 0 \\
0\quad & \lambda_2 & \cdots & 0 \\
\vdots\quad & \vdots & \ddots & \vdots \\
0\quad & 0 & \cdots & \lambda_n
\end{bmatrix}
\end{aligned}$$
즉, 다시 표현하면 아래와 같이 Diagonal Matrix $\Lambda$로 표현할 수 있고, 이때 Diagonal Matrix의 대각원소는 고유값들을 가지게 됩니다. 이를 Eigen Values Decomposition이라고 합니다.
$$A = P \Lambda P^{-1}$$
아래는 예시입니다.
$$\begin{bmatrix}
1 & 1 & 0 \\
0 & 2 & 1 \\
0 & 0 & 3
\end{bmatrix}
=
\begin{bmatrix}
1 & 1 & 1 \\
0 & 1 & 2 \\
0 & 0 & 2
\end{bmatrix}
\begin{bmatrix}
1 & 0 & 0 \\
0 & 2 & 0 \\
0 & 0 & 3
\end{bmatrix}
\begin{bmatrix}
1 & 1 & 1 \\
0 & 1 & 2 \\
0 & 0 & 2
\end{bmatrix}^{-1}
$$
근데, 이를 조금더 확장시켜 MxN행렬 $B$에 대해 위와 같은 과정을 거쳐 아래와 같은 형태로 만들어내는 과정을 SVD(Singular Value Decomposition)이라고 합니다.
** 어떻게 얻는지는 수학적으로 조금 더 살펴보시길 바랍니다.
$$\begin{aligned}
&A = U \Sigma V^{T}&\\
U: \ m \times m &\ \text{orthogonal matrix} &\quad \left( AA^{T} = U (\Sigma \Sigma^{T}) U^{T} \right)\\
V: \ n \times n \ &\text{orthogonal matrix} &\quad \left( A^{T} A = V (\Sigma^{T} \Sigma) V^{T} \right)\\
\Sigma: \ m \times n \ &\text{rectangular diagonal matrix}&
\end{aligned}$$
이 때, $\Sigma$는 Diagonal Matrix로, 대각원소는 고유값들을 가지게 되고, Singular Value라고 부릅니다.
하지만 SVD에서 $U$와 $V$를 구해내는 과정으로 인해 Singular Value들은 항상 0이상의 값을 가지는 특징이 생깁니다.
--------------------------------------------------------------
그다음 이 Diagonal Matrix의 singular 값들은 아래와 같이 augmented됩니다.
(SVR+)
$$\begin{aligned}
\hat{\mathcal{X}}^{exp}&=U{\color{red}\hat{\boldsymbol{\Sigma}}}V^\top\\
{\color{red}\hat{\boldsymbol{\Sigma}}}&=diag({\color{red}\hat{\sigma_0}},{\color{red}\hat{\sigma_1}},\cdots,{\color{red}\hat{\sigma_{n_j}}})\\
{\color{red}\hat{\sigma}}&=\beta e^{\alpha\sigma}\ast\sigma\quad \alpha,\beta\geq 0\\
\rightarrow{\color{red}\hat{\mathcal{C}}}&=[{\color{blue}c_{[SOT]}},{\color{blue}c_{P_0}},{\color{blue}c_{P_1}},\dots,{\color{blue}c_{P_{j-1}}},{\color{red}\hat{c}_{P_j}},{\color{blue}c_{P_{j+1}}},\dots,{\color{blue}c_{P_N}},{\color{red}\hat{c}_{[EOT]}}]
\end{aligned}$$
다음으로 $\mathcal{X}^{sup}$의 경우 위에 보인 것처럼 $[{\color{blue}c_{P_1}},\dots,{\color{blue}c_{P_{j-1}}},{\color{blue}c_{P_{j+1}}},\dots,{\color{blue}c_{P_{N}}},{\color{blue}c_{[EOT]}}]$ (joint suppress)로도 할 수 있지만 잘 적용되지 않아 $[{\color{blue}c_{P_1}},{\color{blue}{\color{red}\hat{c}_{[EOT]}}}],\dots,[{\color{blue}c_{P_{j-1}}},{\color{red}\hat{c}_{[EOT]}}],[{\color{blue}c_{P_{j+1}}},{\color{red}\hat{c}_{[EOT]}}],\dots,[{\color{blue}c_{P_{N}}}{\color{red}\hat{c}_{[EOT]}}]$형태(iterative suppress)로, 위와 같이 SVD decomposition을 한 뒤 Diagonal Matrix의 singular 값들을 아래식으로 suppress합니다.
(SVR-)
$$\begin{aligned}
\hat{\mathcal{X}}^{sup}&=U{\color{OliveGreen}\tilde{\boldsymbol{\Sigma}}}V^\top\\
{\color{OliveGreen}\tilde{\boldsymbol{\Sigma}}}&=diag({\color{OliveGreen}\tilde{\sigma_0}},{\color{OliveGreen}\tilde{\sigma_1}},\cdots,{\color{OliveGreen}\tilde{\sigma_{n_j}}})\\
{\color{OliveGreen}\tilde{\sigma}}&=\beta' e^{-\alpha'{\color{red}\hat{\sigma}}}\ast{\color{red}\hat{\sigma}}\quad \alpha',\beta'\geq 0\\
\rightarrow{\color{OliveGreen}\tilde{\mathcal{C}}}&=[{\color{blue}c_{[SOT]}},{\color{blue}c_{P_0}},{\color{OliveGreen}\tilde{c}_{P_1}},\dots,{\color{OliveGreen}\tilde{c}_{P_{j-1}}},{\color{red}\hat{c}_{P_j}},{\color{OliveGreen}\tilde{c}_{P_{j+1}}},\dots,{\color{OliveGreen}\tilde{c}_{P_N}},{\color{OliveGreen}\tilde{c}_{[EOT]}}]
\end{aligned}$$
b. IPCA(Identity-Preserving Cross-Attention)
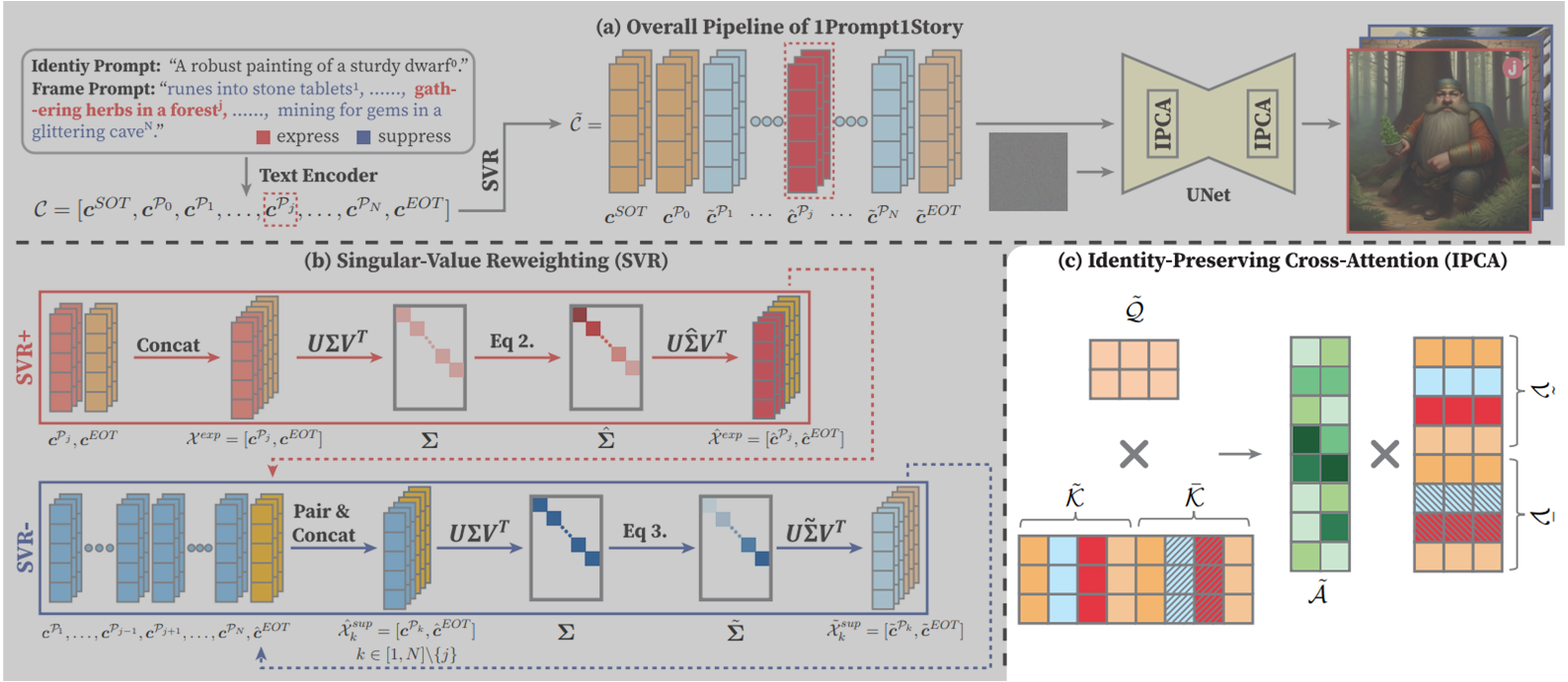
이제 SVR을 통해 background가 frame간에 섞여서 나오는 현상은 줄일 수 있지만, 오히려 context consistency 잘 유지되지 않고 identity가 사라지는 방향으로 변했다고 합니다.
이 때, 타 논문에서는 Cross-Attention Map이 토큰의 특징정보를 얻어내는데 반해, Self-Attention은 이미지의 디테일과 같은 Layout정보를 얻어내는 것을 밝혀냈고, 이를 모티브로 생성된 이미지간에 identity를 보존하기 위한 Identity-Preserving Cross-Attention을 제안합니다.
** Towards understanding cross and self-attention in stable diffusion for text-guided image editing (CVPR’24)
먼저, 위 SVR과정으로 얻어낸 Text Embedding ${\color{OliveGreen}\tilde{\mathcal{C}}}$에 대해 diffusion timestep t에서 대응하는 ${\color{OliveGreen}\tilde{Q}},{\color{OliveGreen}\tilde{K}},{\color{OliveGreen}\tilde{V}}$가 얻어졌다고 생각하겠습니다.
이 때, ${\color{OliveGreen}\tilde{K}},{\color{OliveGreen}\tilde{V}}$에 대해, identity consistency를 제공하고 관계 없는 prompt의 영향을 줄이기 위해서 아래와 같이 identity prompt를 제외하고 0으로 바꿔줍니다.
$$\begin{aligned}
{\color{OliveGreen}\tilde{K}}=&[{\color{blue}k_{[SOT]}},{\color{blue}k_{P_0}},{\color{OliveGreen}\tilde{k}_{P_1}},\dots,{\color{OliveGreen}\tilde{k}_{P_{j-1}}},{\color{red}\hat{k}_{P_j}},{\color{OliveGreen}\tilde{k}_{P_{j+1}}},\dots,{\color{OliveGreen}\tilde{k}_{P_N}},{\color{OliveGreen}\tilde{k}_{[EOT]}}]\\
\rightarrow\bar{K}=&[{\color{blue}k_{[SOT]}},{\color{blue}k_{P_0}},0,\dots,0,{\color{OliveGreen}\tilde{k}_{[EOT]}}]\\
{\color{OliveGreen}\tilde{V}}=&[{\color{blue}v_{[SOT]}},{\color{blue}v_{P_0}},{\color{OliveGreen}\tilde{v}_{P_1}},\dots,{\color{OliveGreen}\tilde{v}_{P_{j-1}}},{\color{red}\hat{v}_{P_j}},{\color{OliveGreen}\tilde{v}_{P_{j+1}}},\dots,{\color{OliveGreen}\tilde{v}_{P_N}},{\color{OliveGreen}\tilde{v}_{[EOT]}}]\\
\rightarrow\bar{V}=&[{\color{blue}v_{[SOT]}},{\color{blue}v_{P_0}},0,\dots,0,{\color{OliveGreen}\tilde{v}_{[EOT]}}]\\
\end{aligned}$$
그다음, 기존 Key, Value와 concat해준 뒤, 아래와 같은 Cross Attention을 진행합니다.
$$\begin{aligned}
{\color{Plum}\tilde{K}}&=Concat({\color{OliveGreen}\tilde{K}}^\top,{\bar{K}}^\top)^\top\\
{\color{Plum}\tilde{V}}&=Concat({\color{OliveGreen}\tilde{V}}^\top,{\bar{V}}^\top)^\top\\
{\tilde{A}}&=Softmax({\color{OliveGreen}\tilde{Q}}{\color{Plum}\tilde{K}}^\top/\sqrt{d})\\
Output&=A\times{\color{Plum}\tilde{V}}
\end{aligned}$$
결과적으로 이제는 identity consistency 또한 제공할 수 있었다고 합니다.
b. (UNet) DiffDis
** DiffDis: Empowering Generative Diffusion Model with Cross-Modal Discrimination Capability (ICCV’23)
- Fusion Method : feature 간의 concatenation, self-attention, feature의 latent간의 Contrastive Alignment Loss
- Main Target Modality : Text
- Focus : Loss를 통해 Modality간의 Connection을 만들어주는 방법
기존에 Cross-modal pretrained Model인 CLIP, ALIGN, FILIP등은 다양한 downstream task에 사용되는데, 본 논문에서는 Diffusion모델을 통해 생성과 Discriminative task를 동시에 할 수 있는 DiffDis를 제안합니다.

먼저 아래와 같은 image($x$)-text($y$) 데이터셋이 존재한다고 합시다.
$$D=\{x_i,y_i\}^N_{i=1}$$
이에 본 논문은 아래와 같은 구조의 Dual-stream 구조의 모델을 제안합니다.
- Image Encoder : $V$
- Text Encoder : $T$
- Text-Conditional Image Generation을 위한 UNet모델 : $\Phi_u$
- 추가적인 transformer block : $\Phi_\theta$

또한 전체 Loss는 아래와 같습니다.
$$\mathcal{L}_{Total}=\mathcal{L}_{IG}+\mathcal{L}_{ITA}$$
그럼 하나씩 살펴보겠습니다.
a. Loss 설계
일반적인 Diffusion 모델과 동일하게 DiffDis는 이미지 샘플을 denoising하면서 생성해내며, LDM과 동일하게 latent image $z$를 사용합니다.
** $c$는 text condition입니다.
$$\begin{aligned}
for\,image(encode):&&z=&V(x)\in&&\mathbb{R}^{H\times W\times d_x}\\
for\,image(decode):&&\hat{x}=&D(\hat{z}_0)\\
for\,text(encode):&&c=&T(y)\in&&\mathbb{R}^{L\times d_y}
\end{aligned}$$
따라서 DDPM의 수식과 비교해 Text-condition Image Generation을 위한 Loss는 단순히 아래와 같고, 생성시는 DDIM과 CFG를 활용했다고 합니다.
$$\begin{aligned}
\mathcal{L}_{DDPM} =& \mathbb{E}_{x_0 \sim q(x_0), \epsilon \sim \mathcal{N}(0, I), t \sim [1, T]} \left[
\left\| \epsilon - \epsilon_\theta(x_t, t) \right\|^2
\right]\\
\mathcal{L}_{IG} =& \mathbb{E}_{{V}(x), \epsilon_z \sim \mathcal{N}(0, I), t_z} \left[
\left\| \epsilon_z - {\color{blue}\Phi_u(z_t, t_z, c)} \right\|^2
\right]
\end{aligned}$$
이제 본 논문에서 중요한 것은 visual feature와 textual feature가 같은 의미론적 space에 위치하도록 둘간의 Alignment를 만들어주는 것입니다.
기존에 CLIP에서는 ITC(Image-Text Contrastive) Loss를 활용하는데, 이는 visual feature $v_i$와 textual feature $e_j$간의 Cosine Similarity를 아래와 같이 계산하는 방법입니다.
** $s^y_{i,j}$는 text-to-image similarity, $s^x_{i,j}$는 image-to-text similarity입니다.
** Contrastive Loss 관련해 궁금하시면 아래 더보기를 참조하세요
$$s^y_{i,j}=s^x_{i,j}=v_i^\top e_j$$
---------------------------------------------------------------------
<Contrastive Loss>
** Improved Deep Metric Learning with Multi-class N-pair Loss Objective (NIPS'16)
$x_i$와 $x_j$간의 Contrastive loss는 아래와 같이 생겼습니다. 이때, encoder $f$를 활용한 임베딩 간의 거리를 활용합니다.
$$\mathcal{L}_{\mathrm{cont}}^{m}(x_i, x_j; f) =
\mathbf{1}\{y_i = y_j\}\|f_i - f_j\|_2^2
+ \mathbf{1}\{y_i \neq y_j\} \max\left(0, m - \|f_i - f_j\|_2\right)^2$$

조금 더 자세히 보면, 같은 class 일 때($y_i=y_j$)는 그 거리만큼을 loss로 가지고 다른 class 일 때($y_i\neq y_j$)는 가까울수록 loss가 커집니다.
단, 두 임베딩 값의 거리가 margin $m$보다 큰 경우는 clip해줍니다.
이를 조금 더 일반화해, Anchor인 $x$가 같은 class인 Positive $x^+$와 가까워지고 다른 class인 Negative $x^-$와는 멀어지도록 만들어주는 triplet loss는 아래와 같습니다.
** 역시나 위와 같이 encoder $f$를 통해 임베딩을 만들어주며, 각각의 결과를 $f^+$와 $f^-$로 나타냅니다.
$$\mathcal{L}_{\mathrm{tri}}^{m}(x, x^{+}, x^{-}; f) =
\max\left(0, \|f - f^{+}\|_2^2 - \|f - f^{-}\|_2^2 + m\right)
$$
이번엔 조금 더 일반화해, Anchor인 $x$가 같은 class인 Positive $x^+$ 1가지와 가까워지고 다른 class인 Negative $x^-$ 여러개와는 멀어지도록 만들어주는 (N+1)Tuplet Loss는 아래와 같습니다.
$$\begin{aligned}
\mathcal{L}(\{x, x^{+}, \{x_i\}_{i=1}^{N-1}\}; f) =&
\log\left( 1 + \sum_{i=1}^{N-1} \exp\left( f^{\top} f_i - f^{\top} f^{+} \right) \right)
\\
=& - \log \frac{\exp\left(f^{\top} f^{+}\right)}
{\exp\left(f^{\top} f^{+}\right) + \sum_{i=1}^{N-1} \exp\left(f^{\top} f_i\right)}
\end{aligned}$$
---------------------------------------------------------------------
이제 위와 같은 Similarity는 CLIP에서 아래와 같은 loss 형태로 학습됩니다.
$$\mathcal{L}_{\mathrm{ITC}}^{\mathrm{img} \rightarrow \mathrm{text}}
= - \frac{1}{N} \sum_{i=1}^N
\log \frac{\exp\left(s_{i,i} / \tau\right)}
{\sum_{j=1}^N \exp\left(s_{i,j} / \tau\right)}
$$
이제 위 ITC Loss를 reformulate해 diffusion process로 가져오기 위해 Diffusion-based image-text Alignment Loss를 만들어주어야 합니다.
기존에 DDPM의 forward process는 아래와 같았습니다.
$$x_t=\sqrt{\bar{\alpha}}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon$$
이를 참고해 이미지를 생성하는 DM이 text embedding $e\in\mathbb{R}^{1\times d_y}$에 일치하는 분포를 가지도록 만들어주기 위해, text를 생성하는 Diffusion process를 아래와 같이 만들어줍니다.
** $\gamma\in (0,1]$는 text embedding $e_0$의 스케일을 결정하기 위한 스케일 factor입니다.
$$\begin{aligned}
e_t = \gamma \sqrt{\bar{\alpha}_t} e_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon_e\\
\quad \alpha_t = 1 - \beta_t, \quad \bar{\alpha}_t = \prod_{j=0}^{t} \alpha_j
\end{aligned}$$
이미지 생성 task와 다르게 텍스트를 생성하기 위한 diffusion 모델 $\Phi_\theta$는 최종적으로 기존 텍스트 쿼리를 예측하기 위해 noise prediction 목적을 가집니다.
** $\Phi_\theta$는 $\hat{e}_0$와 $\epsilon_e$ 모두 가능합니다.
$$\hat{e}_0=\Phi_\theta(e_t,t_e,z)$$
따라서 alignment를 위해 아래와 같이 생성된 텍스트와 실제 텍스트 간의 거리를 최소화하는 cosine similarity는 아래와 같습니다.
$$\mathbf{s} = \hat{e}_0^\top e$$
결과적으로 image-text alignment objective는 아래와 같습니다. 즉, image-to-text similarity와 text-to-image similarity를 계산해 Contrastive Loss를 얻어냅니다.
** $B$는 배치사이즈
$$\mathcal{L}_{ITA} = -\frac{1}{2B} \sum_{i=1}^{B} \left[
\log \frac{\exp(s^x_{i,i})}{\sum_j \exp(s^x_{i,j})}
+
\log \frac{\exp(s^y_{i,i})}{\sum_j \exp(s^y_{j,i})}
\right]$$
b. Model 구조
이번엔 모델을 살펴보겠습니다.
앞서 설명된 것 처럼 DiffDis는 아래와 같이 네가지 모듈로 구성되어있습니다.
- Image Encoder $V$ : image $x$를 latent $z$로 변환
- Text Encoder $T$ : text prompt $y$를 token-wise 표현인 text condition $c\in\mathbb{R}^{L\times d_y}$와 normalized global 표현인 text query $e\in\mathbb{R}^{1\times d_y}$로 변환
- Image Generation UNet모델 $\Phi_u$ : latent image $z$, text condition $c$, 그리고 noisy text query $e_t$를 받아 noise $\epsilon_z$를 예측
- Transformer block $\Phi_\theta$ : Middle Block의 feature를 받아 clean한 text query를 예측한 estimate $\hat{e}$를 얻음
** $\Phi_\theta$는 $\hat{e}_0$와 $\epsilon_e$ 모두 가능합니다.
먼저 Image Generation UNet모델 $\Phi_u$는 기존의 UNet에서 두개의 task를 더 잘 합칠 수 있도록, 기존 attention block을 아래 그림과 같이 Dual-stream Deep-fusion Attention block으로 변경합니다.
- Hidden Text Query $h_{e_{[l-1]}}$ : 앞선 Block에서 넘어온 Text Query로, 0으로 초기화됩니다.
- Hidden Latent Image $h_{z_{[l-1]}}$ : 앞선 Block에서 넘어온 Latent Image로, denoising process에 사용됩니다.

즉, UNet의 한 Layer내의 포함된 Attention Block은 아래와 같은 순서로 진행됩니다.
- Step1. noisy text query $e_t$와 hidden text query 이전 블록의 $h_{e_{[l-1]}}$가 skip connection에서 합쳐져 FC를 거칩니다.
** hidden latent image space와 차원을 동일하게 맞추기 위해
** time embedding $t_e$도 더해줍니다. - Step2. 이 hidden text query가 hidden latent image $h_{z_{[l-1]}}$와 concat됩니다.
- Step3. Attention Block : K개의 Transformer Block이 합쳐진 형태이며, 하나의 Transformer Block내에서는 아래의 순서로 동작
- Step3-1. Self-Attention으로 들어감
- Step3-2. 이후 Split되어 text stream와 image stream으로 나뉨
- Step3-3. 각 Stream
- Text Stream: Cross-Attention을 skip하고 FFN을 거쳐 다음 블록의 $h_{e_{[l]}}$가 됨
- Image Stream : Text Condition c와 함께 Cross-Attention을 통과하고, FFN을 거쳐 다음 블록의 $h_{z_{[l]}}$가 됨
- Step4. 이후 Text Stream의 결과는 FC를 통해 차원을 맞춰주며, Image Stream의 결과는 그대로 사용됩니다.
결과적으로 UNet은 이후에 나올 Transformer block에 Text와 정보를 잘 fusion해서 제공할 수 있으며, 자체적으로는 이미지 생성이 가능합니다.
다음으로 Transformer block $\Phi_\theta$는 M개의 transformer block과 Linear predictor로 이루어져 있고, UNet의 middle block 다음에 붙습니다.
이는 UNet의 middle block에서 나온 concatenated된 feature 을 받아 처리하고, 이에서 나온 text query token은 linear predictor를 통해 기존 text query $e$를 예측해냅니다.
** middle block에서 나온 concatenated된 feature : hidden text query $h_{e_{[l]}}$와 flatten 이미지 feature map $h_{z_{[l]}}$이 concat된 feature를 활용
이런 Dual-stream 모델구조와 Loss를 통해 discriminative한 학습이 가능하도록 했으며, 생성시 기존과 다른 text conditional Image generation이 가능해졌습니다.
c. (DiT) TACA
** TACA: Rethinking Cross-Modal Interaction in Multimodal Diffusion Transformers (arxiv’25)
- Fusion Method : Input Concatenation, Self-Attention
- Main Target Modality : Text
- Focus : Self-Attention을 활용시 Interaction을 제한하는 방법
MM-DiT(Multimodal Diffusion Transformer)는 T2I모델에서 아직 정확한 alignment를 구현하지 못하고 있다고 합니다.
먼저 input은 아래와 같이 두가지가 있다고 하겠습니다.
** $H$ : attention heads 수
** N : sequence length 이자 token의 길이
** $D$ : 각 token의 embedding 차원
- Visual Tokens : ${\color{blue}\boldsymbol{x}} \in \mathbb{R}^{H \times N_x \times D}$
- Text Tokens : $\boldsymbol{c} \in \mathbb{R}^{H \times N_c \times D}$
이때, concatenate된 두가지 token들은 하나의 input sequence로 합쳐져 아래와 같이 (Multi-head) Self-Attention에 활용됩니다.
$$\begin{aligned}
\boldsymbol{Q} = \begin{pmatrix}
W_c^Q \boldsymbol{c} \\
{\color{blue}W_x^Q \boldsymbol{x}}
\end{pmatrix}, \quad
\boldsymbol{K} = \begin{pmatrix}
W_c^K \boldsymbol{c} \\
{\color{blue}W_x^K \boldsymbol{x}}
\end{pmatrix}, \quad
\boldsymbol{V} = \begin{pmatrix}
W_c^V \boldsymbol{c} \\
{\color{blue}W_x^V \boldsymbol{x}}
\end{pmatrix}\\
\mathrm{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \mathrm{softmax}\left( \frac{\mathbf{Q} \mathbf{K}^T}{\sqrt{D}} \right) \mathbf{V}
\end{aligned}$$
이때 Self-Attention 수식을 잘 풀어보면, Attention Map을 만드는 과정에서 아래와 같이 네가지의 interaction type이 발생하는 것을 볼 수 있습니다.
** Text-Text, Text-Visual, Visual-Text, Visual-Visual Attentions
$$\begin{aligned}
\boldsymbol{Q} \boldsymbol{K}^T &=
\begin{pmatrix}
W_c^Q \boldsymbol{c} (W_c^K \boldsymbol{c})^T &\quad W_c^Q \boldsymbol{c} ({\color{blue}W_x^K \boldsymbol{x}})^T \\
{\color{blue}W_x^Q \boldsymbol{x}} (W_c^K \boldsymbol{c})^T
&{\color{blue}\quad W_x^Q \boldsymbol{x}} ({\color{blue}W_x^K \boldsymbol{x}})^T
\end{pmatrix}\\
&=
\begin{pmatrix}
\boldsymbol{Q}_{{txt}} {\boldsymbol{K}_{{txt}}}^T
&\quad \boldsymbol{Q}_{{txt}} {\color{blue}\boldsymbol{K}_{{vis}}}^T \\
{\color{blue}\boldsymbol{Q}_{{vis}}}{\boldsymbol{K}_{{txt}}}^T
&\quad {\color{blue}\boldsymbol{Q}_{{vis}}} {\color{blue}\boldsymbol{K}_{{vis}}}^T
\end{pmatrix}
\end{aligned}$$
여기서 문제는 Visual 토큰의 길이가 $N_x \gg N_c$처럼 Text 토큰의 길이보다 비대칭적으로 큰 것입니다.
예를 들어 FLUX.1 Dev에서는 $N_{vis}=4096,\quad N_{txt}=512$이기 때문에, Attention Weight 분포에는 systematic bias가 생길 가능성이 있습니다.
조금 더 자세히 보자면 위 Attention Map이 Value와 곱해지기 전에 ${\color{blue}\boldsymbol{Q}_{{vis}}}{\boldsymbol{K}_{{txt}}}^T $가 ${\color{blue}\boldsymbol{Q}_{{vis}}} {\color{blue}\boldsymbol{K}_{{vis}}}^T$와 함께 Softmax함수를 통과하는 경우의 식으로 나타내면 i번째 visual token의 j번째 text token에 대한 guidance는 아래와 같을 것입니다.
$$\begin{aligned}
P_{{vis-txt}}^{(i,j)} &=
\frac{e^{s_{ij}^{{vt}} / \tau}}{
\sum_{k=1}^{N_{{txt}}} e^{s_{ik}^{{vt}} / \tau} + \sum_{k=1}^{\color{blue}N_{{vis}}} e^{{\color{blue}s_{ik}^{{vv}}} / \tau}
}\\
s_{ik}^{{vt}} &= {\mathbf{Q}_{{vis}}^{(i)} \left( \mathbf{K}_{{txt}}^{(k)} \right)^T}/{\sqrt{D}}\\
{\color{blue}s_{ik}^{{vv}}} &= {\mathbf{Q}_{{vis}}^{(i)} \left( \mathbf{K}_{{vis}}^{(k)} \right)^T}/{\sqrt{D}}\\
\end{aligned}$$
근데, $N_x \gg N_c$이면, 분모(denominator)는 대부분 visual-visual interaction에 지배되므로, 일반적인 text token의 guidance보다 굉장히 작아지게 됩니다.
$$\begin{aligned}
P_{{vis-txt}}^{(i,j)} \approx&
\frac{e^{s_{ij}^{{vt}} / \tau}}{\sum_{k=1}^{\color{blue}N_{{vis}}} e^{\color{blue}s_{ik}^{{vv}} / \tau}} \quad ({Full\,Attention}) \\
\ll&
\frac{e^{s_{ij}^{{vt}} / \tau}}{\sum_{k=1}^{N_{{txt}}} e^{s_{ik}^{{vt}} / \tau}} \quad ({Typical\,Cross\,Attention})
\end{aligned}$$
이러한 Suppression은 결국 visual-text alignment를 약화시켜버리고, 아래 그림과 같이 Text안의 중요한 semantic한 부분은 간과 되어 visual 표현은 textual 정보와 무관하게 생성됩니다.

또 다른 문제도 있습니다. 기존 MM-DiT는 현재 timestep을 AdaLN을 통해 Scale & Shift하고 있기 때문에, timestep-agnostic한(무관한) 방식으로 Query & Key를 계산합니다.
하지만 아래 Flux.1 Dev의 결과를 보면 Denoising Step에서 초기에는 이미지의 Global Layout을 Text에 영향을 많이 받아 결정하며, 마지막에서는 Detail Refinement 형상을 보입니다.
** Flux.1 Dev는 Cross Attention 기반으로 Text Condition을 제공합니다.

따라서 본 논문은 Early Stage에서는 Text 정보를 받기 위한 Cross-Attention이 Visual Self-Attention 보다 더 크게 동작해야 한다고 주장합니다.
이런 Flux.1 Dev의 특징은 MM-DiT에서도 마찬가지이므로, 현재 timestep과 무관한 static QK weighting 방법은 textual guidance를 제한하게 된다고 말합니다.
즉, 예를 들어 Early Stage에서 cross-modal guidance가 지배적이게 되어야하는데, $s^{vt}_{ik}$는 $s^{vv}_{ik}$에 비해 큰 값을 가지지 못하고 $W^Q,W^K$는 모든 timestep에서 동일하게 동작하므로 visual-text interaction을 파악하지 못한다고 합니다.
이제 이와 같은 문제들을 타개하기 위해 본 논문에서는 MM-DiT의 Attention 메커니즘을 개선할 TACA(Temperature-Adjusted Cross-modal Attention)방법을 제안합니다.
a. Modality-Specific Temperature Scaling
위와 같이 cross-attention의 suppression을 줄이기 위해 visual-text interaction에 아래와 같이 Temperature Coefficient인 ${\color{red}\gamma>1}$를 적용합니다.
$$\begin{aligned}
P_{{vis-txt}}^{(i,j)} &=
\frac{e^{{\color{red}\gamma}{s_{ij}^{{vt}} / \tau}}}{
\sum_{k=1}^{N_{{txt}}} e^{{\color{red}\gamma}s_{ik}^{{vt}} / \tau} + \sum_{k=1}^{\color{blue}N_{{vis}}} e^{{\color{blue}s_{ik}^{{vv}}} / \tau}
}\\
s_{ik}^{{vt}} &= {\mathbf{Q}_{{vis}}^{(i)} \left( \mathbf{K}_{{txt}}^{(k)} \right)^T}/{\sqrt{D}}\\
{\color{blue}s_{ik}^{{vv}}} &= {\mathbf{Q}_{{vis}}^{(i)} \left( \mathbf{K}_{{vis}}^{(k)} \right)^T}/{\sqrt{D}}\\
\end{aligned}$$
이로 인해 ${\color{red}\gamma}$가 커질 수록 softmax내에서 cross-modal interaction은 커지게 되고, text-guided attention의 signal booster처럼 동작한다고 합니다.
b. Timestep-dependent Adjustment of Cross-modal Interactions
이번엔 QK weighting의 timestep에 대한 insensitivity를 보완하기 위해, 위 소개한 ${\color{red}\gamma}$를 time-dependent하게 아래와 같이 적용한다고 합니다.
$$\gamma(t) =
\begin{cases}
\gamma_0 & \text{if } t \geq t_{{thresh}} \\
1 & \text{if } t < t_{{thresh}}
\end{cases}
$$
이를 통해 early step(large t)에서는 높은 text guidance를 통해 composition을 형성하고, later step(small t)에서는 visual detail을 통해 self-attention을 강조한다고 합니다.
d. (DiT) Regional Prompting
** Training-free Regional Prompting for Diffusion Transformers (arxiv’24)
- Fusion Method : Input Concatenation, Self-Attention
- Main Target Modality : Spatial Conditioning
- Focus : Self-Attention의 Mask를 활용하는 방법
정확한 layout을 제공하는 Compositional Generation을 T2I에 적용하는 논문입니다.

기존 Flux.1과 같이 MMDiT구조를 활용하는 경우, 아래 그림과 같이 Text Condition하나만을 사용하며, 이는 Global정보를 담고 Modulation 형태로 Conditioning되거나 디테일한 정보를 담고 Attention에 길이 $L_{image}$의 Image Latent과 Concat되어 들어갑니다.

이를 연장해 본 논문은 아래와 같이 Input을 구성합니다. 즉, $c_{base}$와 $\{(c_i)\}^N_{i=1}$는 각각의 Attention에 $L_{image}$ 길이의 Image Latent와 Concat되어 들어갑니다.
- a. $\{(c_i,m_i)\}^N_{i=1}$ : Region 별로 제공되는 local description이자 N개의 tuple입니다.
- $c_i$ : 해당 region에 대한 description
- $m_i$ : 해당 region에 대한 binary mask
- b. $c_{base}$ : 컨텐츠의 semantic한 부분을 위한 global description입니다.
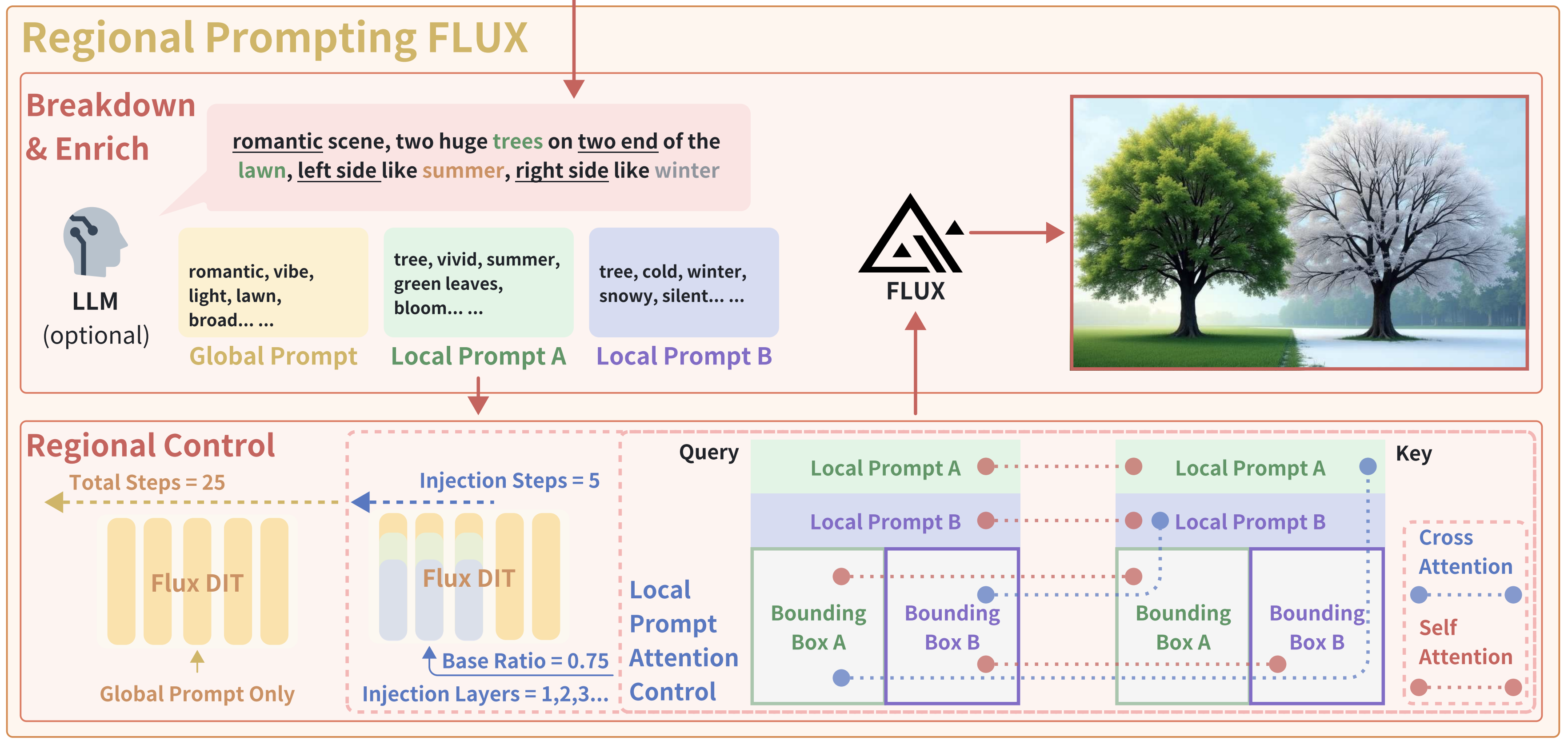
위와 같은 구성은 LLM의 reasoning capacity를 활용해 자동으로 만들어낼수도 있다고 합니다.
먼저, 위 a. $\{(c_i,m_i)\}^N_{i=1}$에 대해 살펴보겠습니다.
위 중 $\{(m_i)\}^N_{i=1}$를 활용해 unified mask를 만듦으로써 해당 layout은 각각의 해당하는 $c_{base}$와 $\{(c_i)\}^N_{i=1}$를 참조해서 생성이 가능해집니다.
** $L_{image}$ : 위와 언급된 바와 같이 $H\times W$의 이미지가 downsampled된 feature map token의 길이입니다.
** $L_{i}$ : i번째 region의 prompt token 길이입니다.
$$\begin{aligned}
M =&
\begin{bmatrix}
\color{blue}{M_{i2i}}\quad& \color{OliveGreen}{M_{i2t}} \\
\color{red}{M_{t2i}}\quad& \color{Orange}{M_{t2t}}
\end{bmatrix}
\in \mathbb{R}^{L \times L}\\
L =& L_{{image}} + \sum_{i=1}^N L_i
\end{aligned}$$
이렇게 만들어진 Mask는 아래와 같이 Attention 연산이 진행됩니다.
** $\odot$ : element-wise multiplication
** $d_k$ : key vector의 차원
$$\begin{aligned}
Attention(Q,K,V,M)=&Softmax\left(\frac{QK^\top}{\sqrt{d_k}}\odot M\right)V\\
=&\underbrace{{CrossAttn(img} \rightarrow {txt)}}_{\color{OliveGreen}\text{image to text}} +
\underbrace{{CrossAttn(txt} \rightarrow {img)}}_{\color{red}\text{text to image}} +
\underbrace{{SelfAttn(img)}}_{\color{blue}\text{image self-attn}} +
\underbrace{{SelfAttn(txt)}}_{\color{Orange}\text{text self-attn}}\\
\end{aligned}$$
결과적으로, 실제 Attention 연산에서도 Mask내에서도 네가지 Pattern이 보입니다.
그럼 이제 각각의 Pattern에 대해 어떻게 아래 그림과 같이 Unified Mask를 만들었는지를 살펴보겠습니다.

a. Cross Attention from image to text
기존 Omost에서 적용한 것과 같이, 이미지 토큰에 대해 masking을 만들어줍니다. 즉, “이미지 토큰중 해당하는 region”이 “해당하는 Text 토큰”만 참조해서 생성하도록 만들어줍니다.
** $\otimes$ : outer product
** $|L_i|$: i번째 region의 prompt token 길이
$${\color{OliveGreen}M_{i2t}} =
\left[
R_1 \otimes \mathbf{1}_{1 \times |L_1|},\;
R_2 \otimes \mathbf{1}_{1 \times |L_2|},\;
\dots,\;
R_T \otimes \mathbf{1}_{1 \times |L_T|}
\right]
\quad \text{with} \quad R_i \in \{0,1\}^{L_{{image}}}$$
b. Cross Attention from text to image
역시나 Text입장에서도 “해당하는 Query Text 토큰”이 “이미지 토큰중 해당하는 region”만 참조해서 생성하도록 만들어줘야하는데, 앞서 만든 Mask의 Transpose를 사용하면 됩니다.
$${\color{red}M_{t2i}} = {\color{OliveGreen}M_{i2t}}^\top$$
c. Self Attention between texts
이번엔 각각의 “Text 토큰”은 “다른 Text 토큰”은 참조하지 않고 독립적으로 동작하도록 하며, 해당 Text 토큰에 대한 Prompt Leakage는 방지하기 위해 Diagonal Matrix를 만들어줍니다.
$${\color{Orange}M_{t2t}} =
\text{diag}(
\mathbf{1}_{|L_1|},\;
\mathbf{1}_{|L_2|},\;
\dots,\;
\mathbf{1}_{|L_T|}
)$$
d. Self Attention within the image
Text와 마찬가지로 해당 Region들도 독립적으로 동작하도록 만들어줍니다.
** $\otimes$ : outer product
$${\color{blue}M_{i2i}} =
\sum_{i=1}^T R_i \otimes R_i^\top$$
이제 위와 같이 만들어진 Unified Mask를 활용해 Region-aware Attention을 하면, 원치 않는 interaction없이 전체 이미지에 대한 feature의 integration이 가능합니다.
** $\psi(\cdot)$ : 각 transformer block의 post processing과정입니다.
$$z^{{region}}_{t-1} = \psi\left({Attention}\left( Q^{{region}}_{t-1},\; K^{{region}}_{t-1},\; V^{{region}}_{t-1},\; M^{{region}} \right) \right)$$
위와 같이 만들어진 latent를 regional latent라고 부릅니다.
이번엔 global 정보를 담고 있는 $c_{base}$를 살펴보면, 아래와 같이 일반적인 Attention을 통해 진행되고 base latent라고 부릅니다.
**$M^{base}$를 어떻게 만들었는지는 나와있지 않지만, 특별한 masking이 적용되지 않았을 것으로 예상합니다.
$$z^{{base}}_{t-1} = \psi\left( {Attention}\left( Q^{{base}}_{t-1},\; K^{{base}}_{t-1},\; V^{{base}}_{t-1},\; M^{{base}} \right) \right)$$
이제 Attention Block을 통과한 regional latent와 base latent는 합쳐져야하는데, ControlNet와 같이 아래와 같은 식을 통해 더해집니다.
$$z_{t-1} =
\beta \cdot z^{{base}}_{t-1} +
(1 - \beta) \cdot z^{{region}}_{t-1}
\quad \text{with} \quad \beta \in [0, 1]$$
위 사용된 base ratio(balancing coefficient) $\beta$는 미적인 fidelity(base latent)와 region control(regional latent)간의 trade-off를 최적화합니다.
마지막으로 위 기법들을 아래의 factor들을 조절하며 테스트해보았다고 합니다.
- denoising step $T$ : egional control을 진행할 diffusion timestep
- target DiT blocks $B$ : regional control을 진행할 DiT block layer들
결과만 이야기하자면 diffusion process에서는 early step에서 대부분의 layout이 결정되므로 초반에만 진행했으며, 이는 computation cost도 최소화할 수 있다고 합니다.
또한 모든 DiT block에 적용하는 것이 default였으나, 너무 많은 block layers에 적용하면 layout이 boundary를 만들어 내게 된다고 합니다.

e. (DiT) Deep Fusion Synthesis
** Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis (CVPR’25)
- Fusion Method : Input Concatenation, Self-Attention
- Main Target Modality : Text
- Focus : Self-Attention을 Dual-Stream으로 활용시 고려해야할 Timestep Conditioning & Position Encoding
최근 LLM과 DiT를 LLM layer-wise shared self-attention을 통해 Deep Fusion을 함으로써 cross-modal간의 다양한 interaction을 지원하는 모델이 등장합니다.
** Playground v3: Improving text-toimage alignment with deep-fusion large language models (arxiv’24)
** Lmfusion:Adapting pretrained language models for multimodal generation (arxiv’24)
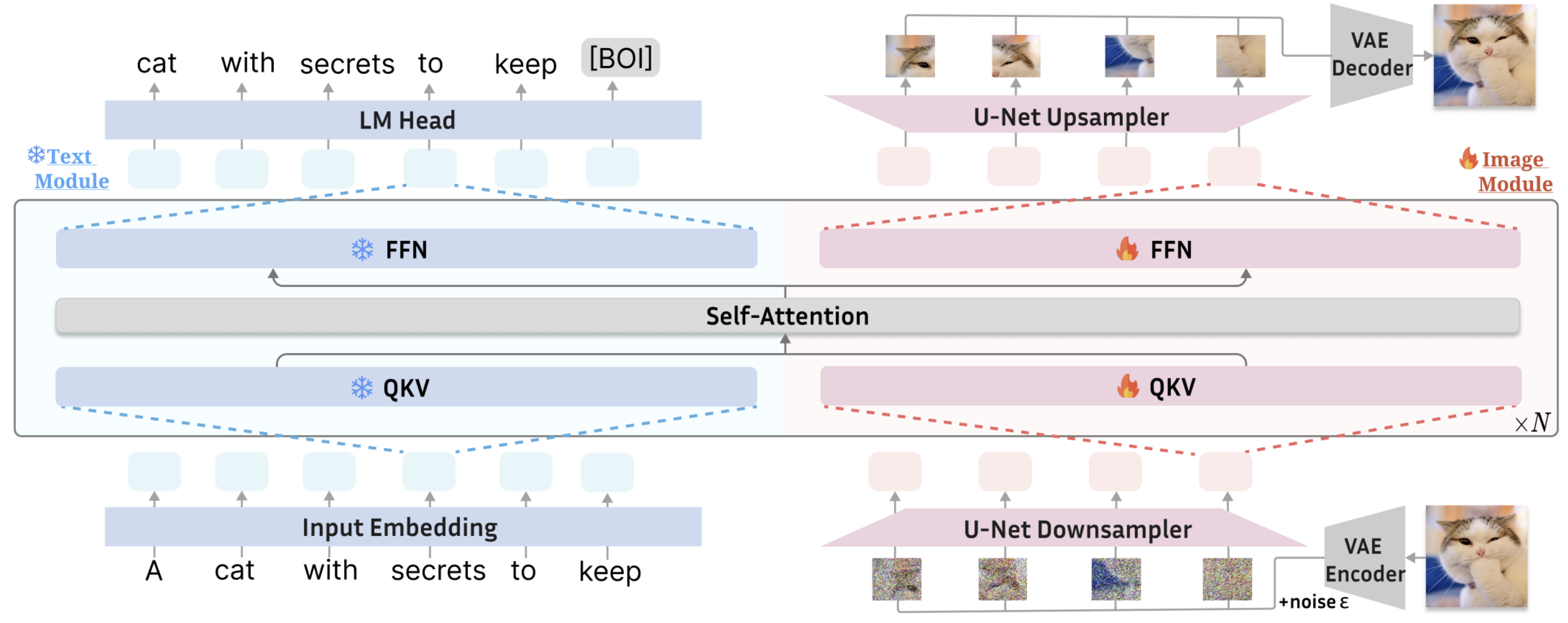
이런 Deep Fusion은 기존의 하나의 text encoder layer표현을 활용하던 T2I task보다 LLM의 Auto-regressive한 decoding성능을 활용해 자연스럽고 유대감있는 퓨전이 가능하게 합니다.
따라서 이런 Deep fusion구조의 모델에 대해 분석하고, Shallow Fusion과 비교해봅니다.
먼저 Deep Fusion구조에 대해 살펴보겠습니다.
이 구조에서 DiT는 frozen된 decoder-only LLM과 합쳐지며, LLM과는 In/Out layer 그리고 timestep conditioning만 다릅니다.
또한, 전체적으로 Two-stream transformer구조이자 Layer-wise Shared self-attention을 활용하며, 이로 인해 multi-layered interaction이 존재합니다.
특히 이를 조사해보기 위해 본 논문에서 활용하는 Deep Fusion의 구조는, 아래 그림과 같은 causal mask를 통해 “이미지 토큰은 텍스트 토큰을 참조”하면서 “텍스트 토큰은 이미지를 참조하지 못하게” 했습니다.

마지막으로, 최종적으로 얻은 텍스트 토큰은 사용하지 않고 이미지 토큰만으로 velocity를 측정(Rectified Flow)했습니다.
구조를 자세하게 살펴보자면 LLM은 Gemma 2B를 활용했으며, DiT는 아래와 같은 셋팅을 사용합니다.
- PE(Positional Encoding) : Absolute PE
- Timestep Conditioning : AdaLN-Zero
- Weight Initialization : ViT style
- Patch-size : 2
- Training Objective : Flow Matching
- VAE : 16-channel VAE from SD3
- Sampling : Euler Discretization & 25 sampling steps
- Conditioning : CFG with scale 6
- 평가 :
- Image-Text Alignment : GenEval, DPG-Bench
** Geneval: An object-focused framework for evaluating textto-image alignment (arxiv’23)
** Ella: Equip diffusion models with llm for enhanced semantic alignment (arxiv’24) - Fidelity : FID (w/ MJHQ-30K)
- Image-Text Alignment : GenEval, DPG-Bench
이제 Shallow Fusion과 비교해보려고 하는데, baseline이 될 Shallow Fusion에 대해 먼저 살펴보겠습니다.
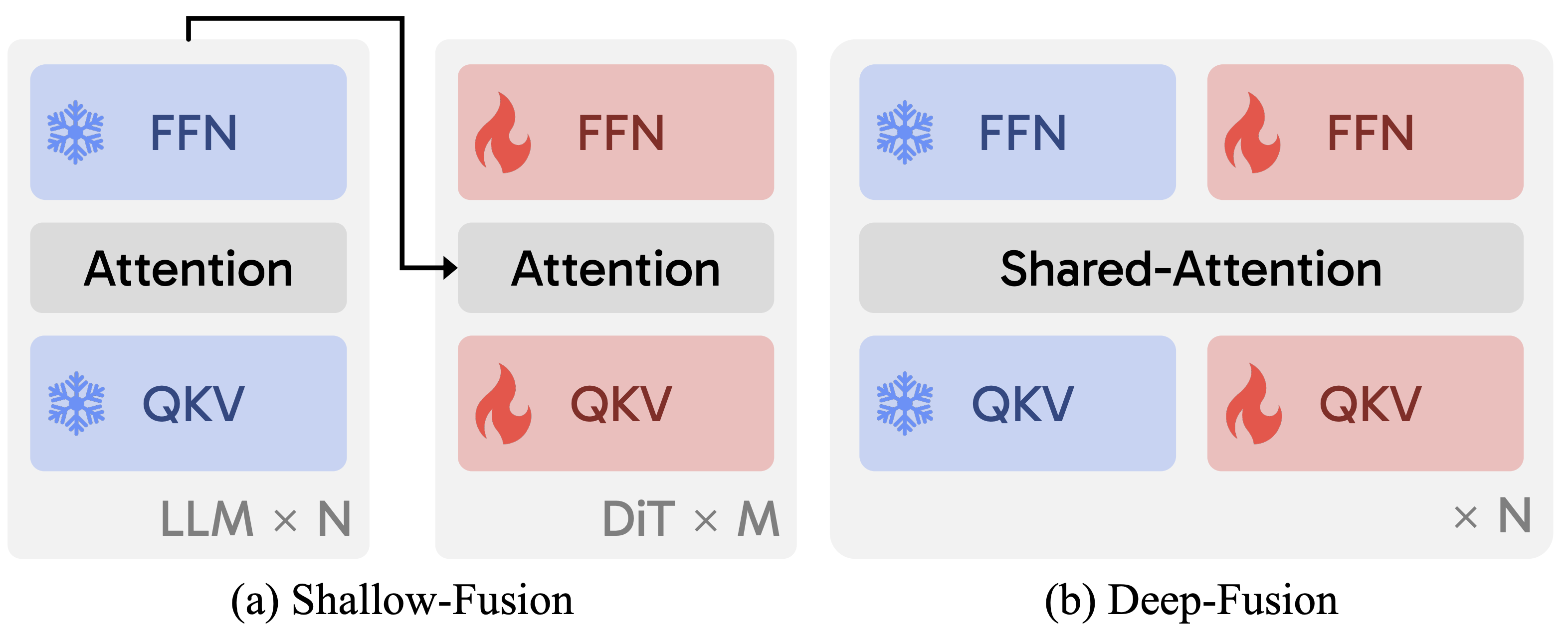
본 논문에서는 Shallow fusion의 경우 attention에서의 late fusion형태라고 부르며, 이는 deep fusion과 다르게 고정된 connection을 통해 가능하다고 합니다.
Shallow fusion은 아래와 같이 두가지를 나눠 설명합니다. (그림도 참조하세요)
- a. Self-Attention DiT : Text표현이 key&value로 image hidden states와 concat되어 self-attention에 들어갑니다. 내부적으로 self-attention과 cross-attention으로 나뉘고 이를 합쳐냅니다.
** Lumina-t2x: Transforming text into any modality, resolution, and duration via flow-based large diffusion transformers (arxiv’24)
** Lumina-next: Making lumina-t2x stronger and faster with next-dit (arxiv’24) - b. Cross-Attention DiT : Text표현이 key&value이지만, cross attention형태로 image hidden states와 연산되며 보통 self-attention이후에 적용됩니다.
** Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation (ECCV’24)
** Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis (ICLR’24)
** Sana: Efficient high-resolution image synthesis with linear diffusion transformers (arxiv’24)

Deep fusion과는 다르게, 위 두 Fusion모두 key&value projection전에 Linear 혹은 RMS Normalization을 거치며, 특히 b. Cross-Attention에서는 image hidden states를 위한 추가적인 query projection을 활용하기도 한다고 합니다.
** 혹자들은 deep fusion이 위 a. Self-Attention DiT의 변종이라고 보기도 합니다. 하지만, a. Self-Attention DiT에서는 key & value가 text encoder의 결과를 학습가능한 projection 을 통해 만들어지지만, deep fusion에서는 해당하는 LLM layer으로 만들어진다고 합니다.
** 이후에 MMDiT와 같은 two-stream transformer 구조가 나오고, noised image latents와 linguistic 표현을 jointly하게 처리하기도 합니다. 하지만 MMDiT는 본 논문의 비교에서 제외되었습니다.
이제 Shallow Fusion을 활용해 Deep Fusion의 다양한 특징들을 살펴보겠습니다.
a. 정량적 결과
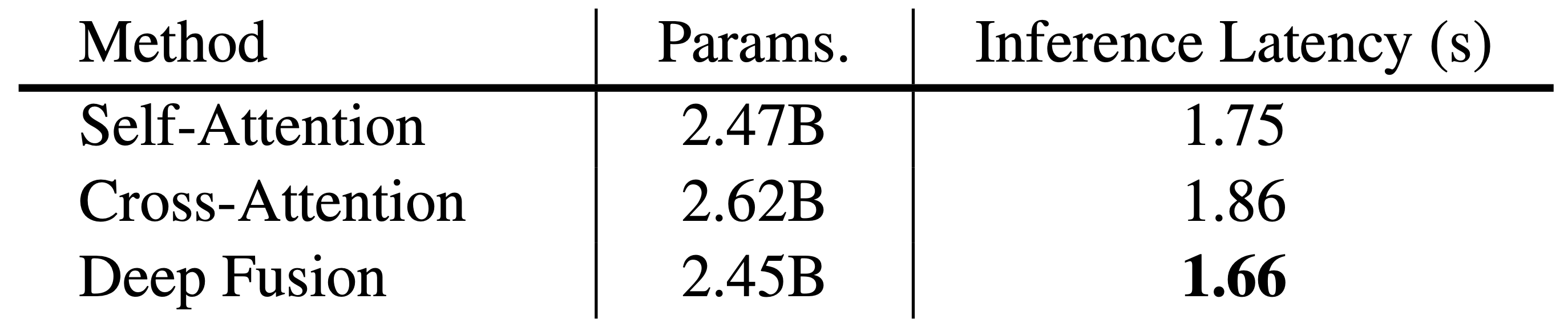
아래 표를 보면, Deep fusion 기법이 Shallow fusion에 비해 image-text alignment는 좋지만, fidelty는 shallow fusion이 더욱 좋았다고 합니다.

또한 아래 표를 보면, Deep fusion방법을 활용했을 때의 inference가 더욱 효율적인 것을 볼 수 있습니다.
b. Timestep Conditioning
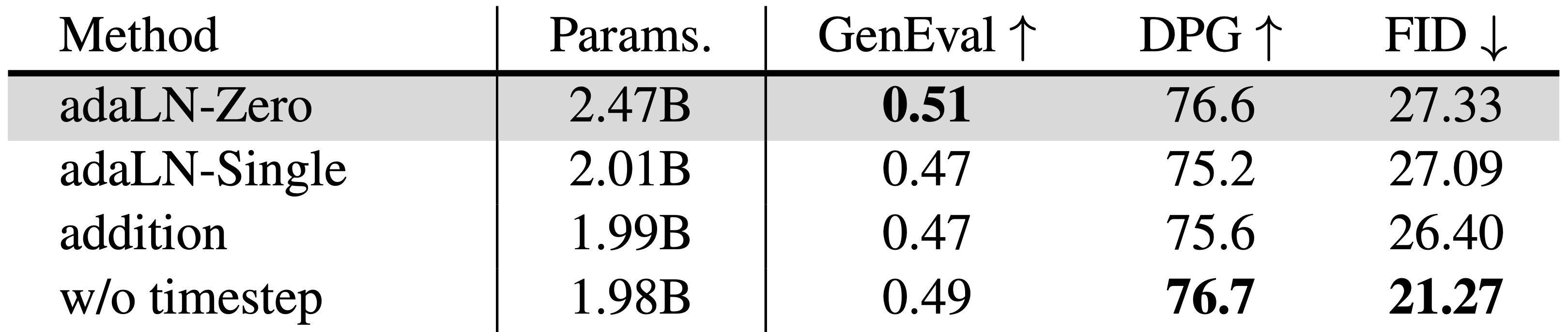
DiT는 일반적으로 AdaLN-Zero를 사용하는데, AdaLN module은 파라미터의 굉장히 큰 부분을 사용합니다.
** ex) 본 논문에서는 class label이 없으므로, AdaLN은 timestep conditioning에만 사용되는데 2.5B 중 0.5B를 사용했습니다.
따라서 본 논문에서는 조금더 효율적인 방법이 있을지 살펴보았는데, CLIP L/14를 활용해 embedding을 구성해보니, 아래 표와 같이 FID는 증가했지만, Image-Text Alignment는 오히려 감소한다는 단점이있습니다.

또한 파라미터 자체를 압축시켜보기 이해 아래와 같은 다양한 Timestep conditioning들을 비교해보았습니다.
- adaLN-Zero : DiT와 같이 0으로 초기화된 modulation 파라미터를 각 layer에 적용
- adaLN-Single : PixArt-$\alpha$ 와 같이 global modulation 파라미터에 각 layer마다 learnable embedding을 더해서 적용
- Addition : Transfusion과 같이 모든 image token에 더해주는 것
- w/o Timestep : 하기 논문과 같이 timestep conditioning을 제거
** Is noise conditioning necessary for denoising generative models? (arxiv’25)
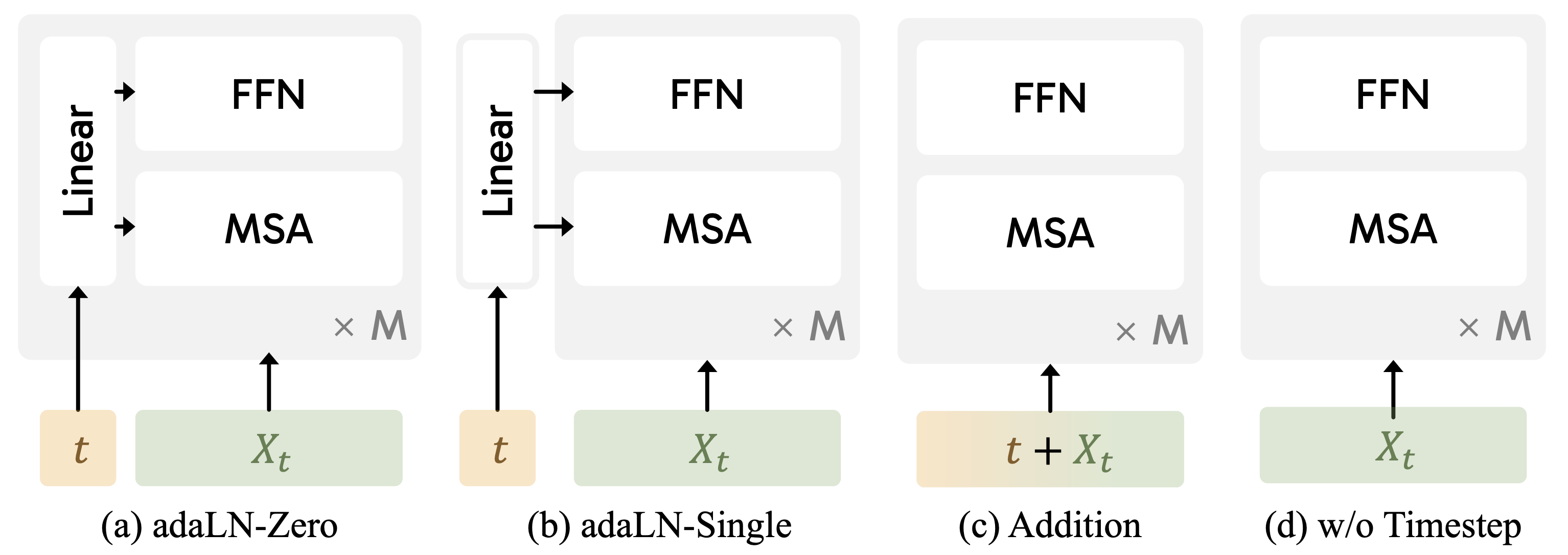
결과적으로 아래 표와 같이 timestep conditioning을 없앴을 때 파라미터도 가장 줄면서 가장 좋은 성능을 보였다고 합니다.
c. Positional Encoding
일반적으로 T2I Diffusion 모델에서는 APE을 활용하는 반면, LLM에서는 일반적으로 RoPE을 PE로 활용합니다.
- APE(Absolute Positional Encoding : 단방향 혹은 양방향으로 고정 위치에 임베딩을 추가하는 방식으로, 단순하고 직관적이지만 위치가 고정되어 일반화되지는 못합니다.
- RoPE(Rotary Positional Encoding) : 위치 정보를 쌍으로 회전시키는 방식으로, 트랜스포머에 적합합니다.
** [RoPE] Roformer: Enhanced transformer with rotary position embedding (Nurocomputing’24) - UnoPE(Universal Rotary Position Embedding) : 여러개의 visual subject가 있을 때, 특징을 헷갈리는 문제를 줄이기 위한 방법입니다.
** [UnoPE] Less-to-More Generalization: Unlocking More Controllability by In-Context Generation (arxiv’25)
이에 따라 본 논문에서는 RoPE가 APE보다 더 장점이 있을지 조사해봅니다.
- 1D RoPE + APE : 텍스트 시퀀스에 1D RoPE를 적용, 이미지 시퀀스에 APE 적용
- 1D RoPE : 텍스트와 이미지 시퀀스 모두에 1D RoPE 적용
- 1D + 2D RoPE : 텍스트 시퀀스에 1D RoPE를 적용, 이미지 시퀀스에 2D RoPE 적용


위 결과를 보면, RoPE가 더욱 효과적이며, modality 별로 다른 positional 특징을 따로 적용하는 것이 더 좋다고 합니다.
또한 기존에 MLLM등에서는 RoPE를 mixed-modal 시퀀스에 적용해 주파수를 나눠서 쓰도록 하는 트릭을 사용하기도 해서, M-RoPE를 구현해보았다고 합니다.
즉, Qwen2-VL에서처럼 chunk형태의 1D RoPE의 freq에 2D positional ID를 함께 사용함으로써, 텍스트에서는 1D RoPE처럼 이미지에서는 2D RoPE처럼 동작하도록 했다고합니다.

하지만 결과적으로 직접 더하는 것보다는 좋지 않았다고 합니다.
d. Architecture Alignment
이번엔 DiT를 hidden size와 layer개수 등 다양하게 바꿔보며 서로다른 modality가 어떻게 상호작용하는지 살펴보았다고 합니다.
이때 hidden size와 layer개수는 아래 그림과 같이 바꿨으며, 이와 같이 변경된 모델은 LLM의 middle layer로만 fused됩니다.
** middle layer가 LLM에서 가장 semantic한 정보를 많이 담은 것으로 알려져 있습니다.

먼저, DiT의 hidden size를 변화시킨 결과를 보였는데, 아래표를 보면 hidden size가 줄수록 성능이 줄어드는 경향이 있었습니다.

또한, DiT의 layer개수를 변화시킨 결과의 아래 표를 표면, layer개수가 줄수록 급격하게 성능이 줄어드는데, 이는 DiT와 함께 사용하기 위한 LLM 모델이 일반적인 LLM모델보다 이미 더 작은 layer를 갖고 있기 때문이라고 합니다.
** 일반적으로 DiT가 SOTA LLM보다 더 작은 모델을 가집니다.

e. Attention Mechanism
MLLM에서의 cross-attention 연구에서와 같이 cross-attention이 self-attention보다 좋은 성능을 보이는 것을 참고해 본 논문에서는 Deep fusion의 새로운 변형을 제안합니다.
즉, 기존의 Shared self-attention을 Cross-attention mechanism으로 변형한 것인데, 기존 Shallow fusion에서는 projected된 텍스트의 key & value state를 활용하는 것과는 다르게 LLM layer를 사용합니다.
결과는 아래 표와 같이 작은 이득이 있을 수 있었지만, 실제로 무시못하는 FLOPs와 파라미터수가 증가했으며 1.66초였던 모델이 1.86초로 latency도 증가했다고 합니다.

Multi-modal : Effective Techniques for Multimodal Data Fusion: A Comparative Analysis
Multi-modal2 : Multimodal Learning with Transformers: A Survey
Multi-modal3 :Deep Multi-modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges
ControlNet : down_block_additional_residuals, mid_block_additional_residual 활용
T2IAdapter : Net의 "down_block_additional_residuals"(==down_intrablock_additional_residuals) argument활용
IPAdapter : UNet의 added_cond_kwargs
https://github.com/huggingface/diffusers/blob/de9528ebc7725012cf097e43f565aeff24940eda/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py#L978C9-L978C26
Contrastive Loss : https://xoft.tistory.com/67
Eigen Vector : https://darkpgmr.tistory.com/105
SVD : https://darkpgmr.tistory.com/106
'소개글 > 에세이' 카테고리의 다른 글
| [Generative] Conditioned Diffusion에서 발생하는 biases에 대한 생각 (0) | 2025.04.05 |
|---|---|
| [PyTorch] num_workers 최적화에 대한 생각 (0) | 2025.03.19 |
| [Generative] Diffusion-based Inversion과 Personalization에 대한 생각 (2) | 2024.04.19 |
| [Spec] 재능, 강점, 그리고 보완 (1) | 2023.10.20 |