
2025. 3. 19. 22:37ㆍ소개글/에세이
시작하기에 앞서 PyTorch를 활용할 때, 데이터로더를 선언하는 과정을 살펴보겠습니다.
먼저 데이터셋을 선언합니다.
train_set = MyDataset()
이번엔 collate_fn() 함수를 정의해줍니다.
def collation_fn(samples):
batched = list(zip(*samples))
result = []
for b in batched:
if isinstance (b[0], (int, float)):
b=np.array(b)
elif isinstance (b[0], torch.Tensor):
b=torch.stack(b)
elif isinstance (b[0], np.ndarray):
b=np.array(b)
else :
b=b
result.append(b)
return result
다음으로 sampler를 선언해줍니다.
if is_distributed():
sampler = torch.utils.data.DistributedSampler(datasets['train'], shuffle=CONFIG.shuffle)
elif shuffle:
sampler = torch.utils.data.RandomSampler(datasets['train'])
else :
sampler = torch.utils.data.SequentialSampler(datasets['train'])
마지막으로 위에 선언된 내용들을 합쳐서 데이터로더를 만들어줍니다.
batch_size = 4
num_workers = 2
dataloader = torch.utils.data.DataLoader(
train_set,
batch_size,
shuffle=True,
sampler=sampler,
num_workers=num_workers,
persistent_workers=True,
pin_memory=True,
drop_last=True,
collate_fn=collation_fn)
위에서 torch.utils.data.DataLoader의 num_workers 옵션은 "dataset의 데이터들을 gpu로 전송할 때 필요한 과정"에 필요한 subprocess 수를 의미합니다.
이번 글에서는 이 subprocess 설정과 관련된 내용과 생각을 정리하고자 합니다.
<구성>
1. num_workers 란?
a. num_workers 동작
b. num_workers 증가 효과
2. num_workers 최적화
a. 최적화의 목표
b. 일반적인 최적화
c. 수치적인 최적화
글효과 분류1 : 코드
글효과 분류2 : 폴더/파일
글효과 분류3 : 용어설명
1. num_workers 란?
먼저 num_workers가 무엇인지, 그리고 어떤 상황에서 문제가 발생하는지를 먼저 살펴보고 가려고 합니다.
a. num_workers 동작
먼저, num_workers가 동작할 때는 아래와 같이 두가지 상황으로 나누어 볼 수 있습니다. 이번 글에서는 subprocess(서브 프로세스)를 활용하는 두번째 상황에 조금더 집중을 하겠습니다.
- num_workers=0 : main process에서 데이터를 직접 로드합니다.
- num_workers>0: worker subprocess에서 동작합니다.
이 때 각각의 독립적인 subprocess는 "worker"라고 불리며, 각 데이터를 Dataset.__getitem__()을 호출하여 로드한 후, multiprocessing.Queue를 통해 메인 프로세스로 전달합니다.
조금 더 자세히 그 과정을 살펴보겠습니다.
먼저 main process(메인 프로세스)에서 선언과 동작하는 순서를 살펴보겠습니다.
** https://github.com/pytorch/pytorch/blob/main/torch/utils/data/dataloader.py
- Step1. DataLoader > self.__init__(self) : DataLoader에서 dataset, batch_size, num_workers, collate_fn, pin_memory, prefetch_factor 등 설정들을 저장해둡니다.
- Step2. DataLoader > self.__iter__(self) : "it=iter(dataloader)"가 불리면 num_workers의 개수에 따라 _SingleProcessDataLoaderIter 혹은 _MultiProcessingDataLoaderIter가 할당됩니다.
- Step3. _MultiProcessingDataLoaderIter > self.__init__(self) : 할당되면서 아래와 같은 순서로 _workers, _index_queues와 _data_queue를 만들어냅니다.
- worker에서 받을 Index Queue들인 _index_queues 생성하고, 이를 하나씩 갖고 있는 worker instance인 _workers를 실행합니다.
** 위 index queue는 multiprocessing_context.Queue()
** _workers 프로세스인 _worker_loop에서 동작하는 내용은 아래 순서 확인 - 하나의 result queue인 _worker_result_queue를 할당하고, 위 _workers에 공유합니다
- 이후에 _data_queue를 만듭니다.
** 만약 pin memory 모드인 경우, pin memory인 _data_queue(일반 Queue)를 새로 할당후 위 _worker_result_queue와 연결
** 만약 pin memory 모드 아니면, _data_queue로 _worker_result_queue를 사용
- worker에서 받을 Index Queue들인 _index_queues 생성하고, 이를 하나씩 갖고 있는 worker instance인 _workers를 실행합니다.
- Step4. _MultiProcessingDataLoaderIter > self.__next__(self) : "next(it)"가 불리면 self._next_data()함수를 실행합니다.
- 이 때 persistent_worker 모드인 경우, 해당 worker가 한번의 dataset을 소비한 후에 shut down하는 과정이 포함되어 있습니다.
- Step5. self._try_put_index()를 통해 Index Queue 들을 통해 데이터를 요청하는 인덱스를 넣어줍니다.
** 이 때 최대 prefetch_factor * num_workers 만큼의 데이터만 요청할 수 있습니다. - ....
- Step10. self._get_data() > self._try_get_data()를 통해 _data_queue로부터 데이터 받아 return 합니다.
위에서 Step2에서 만들어지고, Step3에서 index queue를 통해 데이터를 요청하면 _worker_loop 프로세스는 아래와 같이 동작합니다. 이를 subprocess(서브 프로세스)라고 부릅니다.
** https://github.com/pytorch/pytorch/blob/main/torch/utils/data/_utils/worker.py
- Step6. _worker_loop 프로세스 : Index Queue에서 인덱스를 받아냅니다.
- Step7. _worker_loop 프로세스 : 위 인덱스를 활용해서 "fetcher.fetch(index)"해서 데이터를 얻습니다.
** https://github.com/pytorch/pytorch/blob/main/torch/utils/data/_utils/fetch.py
- Dataset이 IterableDataset인 경우 next(iter(Dataset))를 통해, 아닌 경우 Dataset.__getitem__()를 통해 데이터를 얻습니다.
- Step8. 이후에 self.collate_fn(data)해서 return합니다.
- Step9. _worker_loop 프로세스 : _data_queue에 데이터를 넣어줍니다.

위 subprocess는 torch.multiprocessing.Process()를 통해 만드는데, 이는 python의 multiprocessing 모듈의 wrapper입니다.
** https://pytorch.org/docs/stable/data.html
근데 이 multiprocessing에서 subprocess를 만들때는 OS에 따라 다른 방법으로 생성됩니다.
- Unix에서는 fork() 함수를 통해 프로세스가 생성됩니다.
- 부모 프로세스의 상태와 메모리를 '복제'하여 자식 프로세스를 생성합니다.
- 이 때, 메모리는 부모 프로세스와 자식 프로세스가 메모리를 공유합니다. (thread개념과 비슷)
- ▶ 빠르고 자원효율성이 높지만, 공유로 인한 안정성이나 메모리 누수가 발생합니다.
- 따라서 Dataset에 접근할 때 클론된 address space로 직접 접근이 가능합니다.
- Windows, MacOS에서는 spawn() 함수를 통해 프로세스가 생성됩니다.
- 자식 프로세스가 부모 프로세스의 현재 상태와 메모리를 '복제'하지 않습니다.
- 현재 실행 중인 코드의 상태(전역 변수나 모듈 수준에서 설정된 설정들)가 새 프로세스에 전달되지 않고, 독립적인 메모리 공간을 가집니다.
- ▶ Compatible하고 안정성이 낮지만, 느리고 자원효율성이 낮습니다.
- 따라서 다른 Python 인터프리터가 실행되어, Dataset으로부터 collate_fn()까지 통한 결과를 pickle serialization해서 받습니다.
근데 보통 제가 작업하는 Linux는 Unix계열이므로 Fork로 동작하고, 위 Fork 함수의 특징을 CoW(Copy-on-Write)라고 부릅니다.
** CoW에 대해 궁금하시면 아래 더보기를 참조하세요
-----------------------------------------------------------
<Fork의 특징 : CoW>
위와 같은 Fork 함수의 특징을 CoW(Copy-on-Write)라고 부릅니다.
CoW는 간단히 얘기하면 부모 프로세스의 상태와 메모리를 '복제'하여 자식 프로세스를 생성하고 나서
- 일단 메모리를 공유한 후에
- 복사본의 값이 안바뀌면 계속 같이 쓰고
- 복사본의 값이 바뀌면 메모리를 새로 할당해서 따로 쓰는 것입니다.

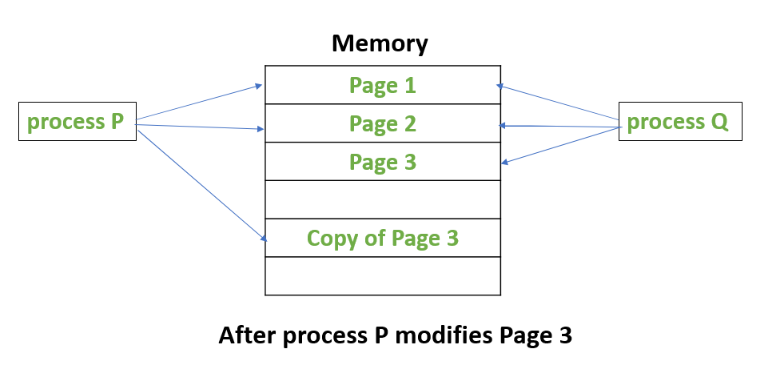
-----------------------------------------------------------
근데 위 CoW를 사용하는 fork()를 써도 num_workers가 늘어날때 메모리가 증가합니다.
물론 새로 생기는 Python 인터프리터인 worker 자체의 runtime thread, stack, heap memory 등은 worker별로 독립적으로 조금씩 늘어나기도 하지만, 더 심각한 것은 Dataset과 관련된 문제로 늘어납니다.
즉, 이는 Python의 메모리 관리 특성때문인데, Python의 리스트나 딕셔너리는 각 요소마다 별도의 refcount(참조 카운트)를 가지고 있고, 이를 읽기만 해도 이 refcount가 바뀌면서 Copy-on-Access가 발생하면서 메모리 페이지가 복사(CoW)됩니다.
이 말인 즉슨, fork()를 써서 만들어진 worker들이 내부의 Dataset을 공유하도록 만들더라도, 각 worker마다 Python 인터프리터가 하나씩 생기고 refcount가 바뀌어서 결국 Dataset을 다 복사해서 사용한다는 것입니다.
특히 심각한 것은 Python 리스트나 딕셔너리는 "각 요소마다" 별도의 refcount를 가지고 있어서 "시간이 갈수록 메모리가 증가"하기도 합니다.
이는 Dataset을 PyTorch Tensor, Numpy, pandas, pyarrow 등으로 바꾸면 이들은 "하나의 refcount"만 가지기 때문에 "계속 해서 증가하는 것"은 막을 수 있습니다.
하지만 num_workers가 늘어남에 따라 메모리를 복사하게되는 것에 대한 대처는 아직 해결되지 않았습니다.
이는 위 언급된 자료형 중에 PyTorch Tensor, Numpy 같은 경우는 각 worker들이 read하더라도 복사(CoW)가 발생하지 않습니다.
이유로는 Numpy의 경우는 Python refcount는 증가하지만 내부적으로 C backend에서 메모리 블록 하나로 관리되기 때문에 CoW가 발생하지 않고, PyTorch Tensor의 경우는 torch.multiprocessing.Process()로 fork되는 경우 내부적으로 custom picker가 존재하는데 PyTorch Tensor를 마주치면 shared memory로 옮겨서 진행하기 때문입니다.
-----------------------------------------------------------
<Numpy에서의 refcount>
Python에서는 refcount가 증가하는 것처럼 보입니다.
import numpy as np
import sys
base = np.array([1,2,3,4,5])
sys.getrefcount(base) # 2
newArr = base
sys.getrefcount(base) # 3
del newArr
sys.getrefcount(base) # 2
하지만 C에서는 증가하지 않습니다.
import ctypes
import os
import numpy as np
import psutil
def sharing_with_numpy():
ppid = os.getpid()
print(f'\nSystem used memory: {int(psutil.virtual_memory().used / (1024 * 1024))} MB')
big_data = np.array([[item, item] for item in list(range(10000000))])
print(f'\nSystem used memory: {int(psutil.virtual_memory().used / (1024 * 1024))} MB')
print(ctypes.c_long.from_address(id(big_data)).value)
ref1 = big_data[0]
ref2 = big_data[0]
print(ctypes.c_long.from_address(id(big_data)).value)
print(f'\nSystem used memory: {int(psutil.virtual_memory().used / (1024 * 1024))} MB')
for i in range(5):
if ppid == os.getpid():
os.fork()
for x in big_data:
pass
print(f'\nSystem used memory: {int(psutil.virtual_memory().used / (1024 * 1024))} MB')
if __name__ == "__main__":
sharing_with_numpy()System used memory: 163 MB # before array allocation
System used memory: 318 MB # after array allocation
1 # reference count of the array
3 # reference count of the array
System used memory: 318 MB # before fork()
System used memory: 324 MB # after fork() and loop to reference array
System used memory: 328 MB # after fork() and loop to reference array
System used memory: 329 MB # after fork() and loop to reference array
System used memory: 331 MB # after fork() and loop to reference array
System used memory: 340 MB # after fork() and loop to reference array
System used memory: 342 MB # after fork() and loop to reference array
-----------------------------------------------------------
이제 subprocess간에는 위와 같이 해결이 될 수도 있지만, 이번엔 "여러개의 GPU를 사용하는 경우" 보통 DDP(Distributed Data Parallel) 등을 활용한다면 "사용하는 GPU의 수만큼 메인 프로세스가 복제"되기 때문에 결국 Dataset은 GPU의 개수만큼 늘어날 수 밖에 없습니다.
** DDP는 보통 NCCL backend를 사용하기 때문에 spawn()을 주로 활용하므로, 독립적인 메모리 공간을 가집니다.
** https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
마지막으로, 다루지 않은 기타 이야기들이 있습니다.
- shuffle=True : 메모리가 증가합니다.
- 당연한 이야기지만 shared memory를 사용하면 메모리가 줄어듭니다.
- torch.cuda.empty_cache() : 모든 iteration이 끝날때마다 GPU메모리를 해제해주면 오르내리락 할지언정 메모리를 관리할 수 있습니다.
- num_workers=0 : 당연히 메인 프로세스만 사용하니까 메모리를 적게사용하겠지만, 혹시나 느릴 수 있습니다.
num_workers에 따라 내부적으로 동작하는 방식들을 먼저 살펴봤는데, 이번엔 num_workers가 증가함에 따라 생기는 효과들을 살펴보려고 합니다.
b. num_workers 증가 효과
위 동작방식을 기반으로 num_workers가 증가함에 따라 생기는 현상들을 살펴보려고 합니다.
먼저, num_workers가 증가함에 따라 고려할 정도는 아닌 미미한 변화는 아래와 같습니다.
- (메모리) 실행 메모리 : Python 인터프리터인 worker 자체의 runtime thread, stack, heap memory 등은 worker별로 독립적으로 조금씩 늘어납니다.
- (작업속도) IPC Bottleneck : 결과를 multiprocessing.Queue를 통해 메인 프로세스로 전달하기 때문에, 여러개의 worker가 하나의 queue에 접근하면 Bottleneck이 발생합니다.
- (작업속도) Disk I/O Bottleneck : 너무 많은 worker가 SSD의 read속도를 초과하는 요청시 disk에서 I/O Bottleneck이 발생합니다.
다음으로, num_workers가 증가함에 따라 메모리 상 큰 변화를 주는 것은 아래와 같습니다.
- (메모리) worker 임시 메모리 : workers가 증가할수록 임시적으로 preload되는 데이터 때문에 일시적으로 메모리가 증가합니다.
- (메모리) IPC Bottleneck : prefetch_factor * num_workers 만큼 데이터를 요청 가능하니까 _data_queue에 최대 이만큼의 데이터가 쌓일 수 있습니다.
마지막으로, num_workers가 증가함에 따라 작업속도 상 큰 변화를 주는 것은 아래와 같습니다.
작업속도 면에서는 좋을수도 있고 안좋을 수도 있습니다.
- (작업속도) 데이터로드 속도 향상 : 병렬 처리를 통해 데이터 로드 속도가 빨라지며 학습 속도가 향상됩니다. (긍정적 효과)
- (작업속도) CPU 오버헤드 증가 : 여러개의 worker가 동작하므로 Context Switch를 위한 비용이 증가하고, scheduling overhead 때문에 오히려 병목이 발생할 수도 있습니다.
** Linux 커널 스케줄러는 기본적으로 CFS(Completely Fair Scheduler) 기반이라, thread/process 수가 core 수를 초과하면 overhead가 급격히 증가할 수 있습니다. - (작업속도) Disk I/O Bottleneck : 너무 많은 worker가 SSD에 접근해야하는 상황에서 RAM(메인메모리)가 부족하면 Page Swapping 때문에 페이지를 계속 갱신함으로 인해 오버헤드가 발생할 수도 있습니다.
2. num_workers 최적화
그래서 num_workers를 어떻게 최적화하면 좋을까요?
어떻게 최적화할지 두가지 방법으로 살펴보려고합니다. 개인적인 의견이 포함되어있습니다.
- b. 귀납적으로 최적의 num_workers를 찾는 일반적인 방법
- c. 코드를 통해 수치를 보면서 최적의 num_workers를 찾는 방법
a. 최적화의 목표
시작하기 전에 우리가 어떤 것을 고려해야할지에 대해 목적을 구체화해보겠습니다.
위에서 설명한 두가지 과정을 아래와 같이 두가지로 구분해서 보겠습니다.
- A. Data Loading : "worker들이 많은 데이터를 준비해서 보내는 과정"으로, 스토리지에서 데이터를 가져와 처리해 메인프로세스로 보내는 과정입니다.
- B. Data Processing : "전체 GPU에서 연산을 처리하는 과정"으로, 메인프로세스에서 GPU로 보내 처리하는 과정입니다. (num_workers에 영향이 없음)

이제 위 두 기준으로 "작업속도"와 "메모리" 측면에서 살펴보겠습니다.
<작업속도>
먼저 "작업속도"에 있어서 우리가 원하는건 GPU에서 처리할 수 있는 처리 속도(B. Data Processing)에 적합하게 worker들이 최대한 데이터를 많이 만들어 보내줘야(A. Data Loading)하는 것입니다.
▷ worker의 개수가 너무 많으면, 오히려 GPU에서 처리하지 못하는데도 불구하고 많은 worker를 관리해야 합니다.
▷ worker의 개수가 너무 적으면, GPU에서는 다 처리했는데도 불구하고 worker가 부족해서 처리할 데이터가 없습니다.
즉, GPU의 처리속도에 적합하게 worker의 개수를 할당해주어야합니다.
근데 속도를 고려하려면 아래와 같은 두가지를 잘 고려해야합니다.
- Compute-Bound (CPU-bound) : CPU에서 처리하는데 걸리는 시간 때문에 작업속도가 결정됩니다.
- Memory-Bound (I/O-bound) : 데이터를 I/O로 가져오는데 걸리는 시간 때문에 작업속도가 결정됩니다.
위 "A. Data Loading", "B. Data Processing" 두 경우에 대해 각각 Compute-Bound와 Memory-Bound는 아래와 같습니다.
- A. "worker들이 많은 데이터를 처리해서 보내는 속도" : 스토리지에서 데이터를 가져와 처리해 메인프로세스로 보내는 속도
- Compute-Bound (CPU-bound) : 데이터를 collate_fn()하고 IPC를 통해 메인프로세스로 보내는 시간
- Memory-Bound (I/O-bound) : 스토리지에서 데이터를 읽어오는 시간
- B. "GPU에서 처리하는 속도" : 메인프로세스에서 GPU로 보내 처리하는 속도 (num_workers에 영향 없음)
- Compute-Bound (CPU-bound) : GPU에서 연산을 처리하는 시간
- Memory-Bound (I/O-bound) : 메인 프로세스에서 GPU로 메모리를 보내는 시간
이 중에 num_workers를 변경할때 달라지는 것은 "A. worker들이 많은 데이터를 처리해서 보내는 속도"입니다.
| Compute-Bound | Memory-Bound | |
| num_workers 증가 | 데이터로드 속도 향상 (+) CPU 오버헤드 증가 (-) |
Disk I/O Bottleneck 감소 (-) |
| num_workers 감소 | 데이터로드 속도 감소 (-) CPU 오버헤드 감소 (+) |
Disk I/O Bottleneck 증가 (+) |
결론적으로 "A. Data Loading"의 작업속도를 개선하기 위해 num_workers를 많이 사용하고 싶지만 Compute-Bound와 Memory-Bound의 밸런스를 잘 맞춰주어야할 것 같습니다.
<메모리>
다음으로 "메모리"에 있어서는 우리가 원하는 건 GPU에서 필요한 메모리(B. Data Processing)와 worker들이 처리하는데 필요한 메모리(A. Data Loading)를 최대한 많이 사용할 수 있으면 좋습니다.
** 너무 많으면 OOM(Out-Of-Memory)이 발생합니다.
역시나 두 경우에 대해 대해 정리하면 아래와 같습니다.
- A. "worker들이 처리하는데 필요한 메모리" : CPU 메모리
- B. "GPU에서 필요한 메모리" : GPU 메모리 (num_workers에 영향 없음)
이 중에 num_workers를 변경할 때 달라지는 것은 "A. worker들이 처리하는데 필요한 메모리"입니다.
| 메모리 변화 | |
| num_workers 증가 | worker 임시 메모리 증가 (-) IPC Bottleneck 메모리 증가 (-) |
| num_workers 감소 | worker 임시 메모리 감소 (+) IPC Bottleneck 메모리 감소 (+) |
결론적으로, 당연히 num_workers가 증가할수록 "A. Data Loading"의 메모리가 증가하므로, 최대한 많이 쓸 수 있도록 하면 좋겠습니다.
위와 같이 작업속도와 메모리를 최적화하기 위해, 우리가 미리 고려해야하는 있는 변수는 아래와 같습니다.
즉, 이 글의 목적은 아래의 변수들 변화시킴으로써 실제 속도를 개선할 수도 있겠지만, 아래 변수들은 유지할 "통제 변수"이며, "조작변수"는 num_workers 뿐 입니다.
- A. "worker들이 많은 데이터를 처리하는 과정"
- GPU 개수 : PyTorch에서 Multi-GPU를 활용할 때 DDP를 사용하는 경우 각 GPU마다 별도의 프로세스가 생성되며, 각 프로세스는 독립적인 DataLoader 인스턴스를 갖게 되므로, "num_workers x GPU개수"만큼의 worker들이 만들어집니다.
→ <작업속도> 중 Compute-Bound를 파악할 수 있습니다. - CPU 코어 개수 : num_workers가 늘어나면 subprocess의 개수 자체가 많아지므로 CPU 코어 개수가 중요합니다.
→ <작업속도> 중 Compute-Bound를 파악할 수 있습니다. - batch_size : 배치개수가 늘어나면 worker 하나가 리턴하는 batch tensor가 커지므로, Queue에 넣는 데이터 크기와 IPC 오버헤드가 커집니다.
→ <작업속도> 중 Compute-Bound와 Memory-Bound 모두와 연관됩니다.
→ <메모리> 와도 연관됩니다. - persistent_workers (default : False): 기본적으로 DataLoader는 epoch마다 worker를 재시작하는데, 이를 방지하여 메모리 사용을 줄이거나 전체 학습속도를 향상시킬 수 있습니다.
→ <작업속도> 중 Compute-Bound와 Memory-Bound 모두와 연관됩니다. - prefetch_factor (default: 2): 미리 _data_queue에 로드하는 데이터의 크기 num_workers × prefetch_factor와 연관이 있습니다.
→ <작업속도> 중 Compute-Bound와 Memory-Bound 모두와 연관됩니다.
→ <메모리> 와도 연관됩니다.
- GPU 개수 : PyTorch에서 Multi-GPU를 활용할 때 DDP를 사용하는 경우 각 GPU마다 별도의 프로세스가 생성되며, 각 프로세스는 독립적인 DataLoader 인스턴스를 갖게 되므로, "num_workers x GPU개수"만큼의 worker들이 만들어집니다.
- B. "전체 GPU에서 처리하는 과정" (num_workers에 영향 없음)
- GPU 개수 : GPU개수가 많을 수록 한번에 더 많은 데이터를 처리할 수 있습니다.
→ <작업속도> 중 Compute-Bound를 파악할 수 있습니다. - batch_size : 배치개수가 늘어나면 GPU가 처리해야할 batch tensor가 커지므로, 속도와 메모리 모두 증가합니다.
→ <작업속도> 중 Compute-Bound와 Memory-Bound 모두와 연관되어있습니다.
→ <메모리> 와도 연관되어있습니다. - pin_memory (default:False) : pin_memory옵션을 키면 Dataloader 메인 프로세스가 데이터를 받아서 바로 device/CUDA pinned memory로 복사합니다. 따라서 CPU 메모리에서 GPU로 데이터로 비동기 복사도 가능하고, 메모리 전송 속도가 빨라집니다.
→ <작업속도> 중 Memory-Bound와 연관됩니다.
- GPU 개수 : GPU개수가 많을 수록 한번에 더 많은 데이터를 처리할 수 있습니다.
그럼 위와 같은 통제변수들을 고려해서 num_workers를 설정하는 방법을 살펴보겠습니다.
b. 일반적인 최적화
이번엔 위 보인 변수들 각각에 대해 사람들이 일반적으로 따르는 규칙들을 살펴보겠습니다.
결론을 먼저 이야기하자면 "답은 없습니다". 즉, 어떤 작업인지 & 어떤 데이터인지에 따라 다르게 셋팅되어야합니다.
시작하기에 앞서 전제조건은 다른 통제조건(batch_size 등)을 통해 GPU를 최대한으로 사용하는 상황에, num_workers를 최대한 사용해서 CPU 메모리를 최대한 사용하면서도 성능을 최대화하려는 상황입니다.
즉, OOM이 발생하지 않는한 "작업속도"를 기준으로 최적화를 진행해야 하는 것인데, 앞서 말한 것과 같이 "작업속도"의 목적은 아래와 같습니다.
전체 GPU에서 처리할 수 있는 처리 속도(B)에 적합하게
worker들이 최대한 데이터를 많이 만들어 보내줘야(A)하는 것이다
그럼 일반적으로 num_workers를 어떻게 설정하는지 살펴보겠습니다.
1. GPU에서 처리할 수 있는 처리 속도를 고려해서, num_workers를 최대화 설정해보자.
▶ num_workers를 GPU의 개수와 연관지어 할당하는 것
GPU의 개수가 많을 수록 처리할 수 있는 처리 속도가 빨라지므로, 이에 맞게 GPU의 개수에 따라 num_workers를 할당하는 경우가 있습니다.
** https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813/5
▷ num_workers = 4 * num_GPU (or 8, 16, 2 * num_GPU)
▷ num_workers = batch_size / num_GPU
위 링크에서 뿐 아니라 다양한 곳에서 이런 식의 기준을 활용하며, 마치 "일반적인 방법"으로 여겨지기도 합니다.
하지만 이와 같은 방법은 "Dataloader를 여러개의 GPU에서 공유하는 상황"에서만 적합한 말입니다.
앞서 설명한 바와 같이 DDP를 활용하는 경우 "하나의 GPU에 해당하는 인스턴스 각각"이 독립적인 worker들을 할당하기 때문에 num_workers를 GPU개수에 맞게 설정하면 전체 생성되는 worker들의 개수는 아래와 같습니다.
▷ num_workers = 4 * num_GPU → 4 * num_GPU * num_GPU workers
즉, "GPU 하나에서 처리할 수 있는 양"에 따라 적절하게 병렬적으로 처리할 수 있는 subprocess를 조절해야 하는데, DDP를 사용하는 등의 상황에서는 이렇게 "GPU의 개수"를 통해 num_workers를 설정하는 것은 맞지 않습니다.
결과적으로 설정하려는 num_workers가 "GPU 전체에서" 필요로 하는 worker의 개수인지를 먼저 확인해야하고,
그렇지 않더라도, GPU전체의 throughput을 정확히 계산해 고려하지 않는한 정확하지 않습니다.
2. 모르겠고, 최대한 num_workers를 최대한 많이 할당해보자
▶ num_workers를 CPU 코어의 개수와 연관지어 할당하는 것
CPU 코어가 많을 수록 overhead 없이 worker들은 많이 할당될 수 있으므로, CPU 코어의 개수와 연관해서 할당하기도 합니다.
PyTorch Lightning 가이드에서는 num_workers가 CPU 코어 개수와 같게 만드는게 일반적이라고 말합니다.
** https://lightning.ai/docs/pytorch/stable/advanced/speed.html
A general place to start is to set num_workers equal to the number of CPU cores on that machine.
You can get the number of CPU cores in Python using os.cpu_count(), but note that depending on your batch size, you may overflow CPU RAM.
▷ num_workers = num_CPU_cores
당연히 CPU 코어의 개수를 고려해서 최대한 많이 할당해야 하는 것은 맞지만, 단순히 많이만 할당한다면 오히려 CPU overhead만 기하급수적으로 늘어날 수도 있습니다.
3. GPU에서 처리할 수 있는 처리 속도와 worker들이 처리하는데 모두 연관이 되어 있는 값을 활용해 할당해보자.
▶ num_workers를 batch_size와 연관지어 할당하는 것
batch_size가 크다는 말은 GPU에서 한번에 처리해야하는 양(Compute Load)이 크고 worker들 입장에서는 로드해야하는 양이 많으므로, 양쪽과 연관이 되어있습니다.
따라서 아래와 같이 num_workers를 batch_size와 동일하게 셋팅하는 경우도 있습니다.
** https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813
▷ num_workers = batch_size
예상하셨겠지만 batch_size에 따라 GPU가 처리해야하는 속도가 종속적이지만, worker들의 성능도 바뀌므로 batch_size를 반영해 num_workers를 설정하는 것은 어렵습니다.
최종적으로 앞서 말한 결론과 같이 "어떤 하나의 값을 보고 결정하기는 쉽지 않습니다".
따라서 그냥 먼저 적정 값을 설정하고 아래와 같이 실험적으로 num_workers를 할당하는 방법밖에 없습니다.
- GPU 사용률 모니터링 : GPU 사용률이 낮다 → 데이터 공급이 느리다 → num_workers를 늘립니다.
- CPU 메모리 모니터링 : 메모리 부족(OOM)이 발생한다 → num_workers를 줄입니다.
- 학습 속도 모니터링 : 학습 속도가 느려졌다 → GPU Throughput에 맞게 num_workers를 조절해 할당해줍니다.
이외에 위에서 "통제변수"로 설정한 값도 당연히 최적화에 활용될 수 있습니다.
** 아시다시피 모든 과정에 앞서 batch_size는 최대한으로 할당하는 것이 좋습니다.
- A. "worker들이 많은 데이터를 처리하는 과정" : worker측 최적화
- persistent_workers (default : False): persistent_workers를 켜서 작업속도를 개선할 수 있습니다.
- prefetch_factor (default: 2): 값을 늘려 더 많이 미리 로드해 작업속도를 개선하거나, 값을 줄여 메모리를 최적화할 수 있습니다.
- B. "전체 GPU에서 처리하는 과정" : gpu측 최적화
- pin_memory (default:False) : pin_memory옵션 켜서 작업속도를 개선할 수 있습니다.
c. 수치적인 최적화
이번엔 수치적으로 살펴보면서 최적화하는 예시를 살펴보려고합니다.
먼저, torch.utils.data.Dataset를 상속한 데이터셋을 구성해줍니다. 아래는 단순한 예시입니다.
my_dataset = SampleDataset(
configs,
sample_rate=44100,
sample_size=15876096,
random_crop=True,
)
이제 find_best_num_workers()라는 함수에 다양한 num_workers를 적용해서 위 기술한 과정중 "A. Data Loading"의 시간이 얼마나 되는지를 확인할 수 있습니다.
from torch.utils.data import DataLoader
import time
import torch
def find_best_num_workers(dataset, batch_size, prefetch_factor=2):
gpu_count = torch.cuda.device_count()
start_workers = min(2, torch.multiprocessing.cpu_count())
max_workers = min(32, torch.multiprocessing.cpu_count()) # CPU 코어보다 크게 설정하지 않음 : Mine :64
best_time = float('inf')
best_workers = 0
for num_workers in range(start_workers, max_workers + 1, 2): # 2씩 증가하며 테스트
dataloader = DataLoader(dataset, batch_size=batch_size, prefetch_factor=prefetch_factor,
num_workers=num_workers, persistent_workers=True, pin_memory=True, drop_last=True)
start = time.time()
for _ in range(5): # 5개 배치만 테스트
_ = next(iter(dataloader))
elapsed = time.time() - start
print(f"num_workers={num_workers}, Time={elapsed:.4f}s")
if elapsed < best_time:
best_time = elapsed
best_workers = num_workers
return best_workers
best_workers = find_best_num_workers(my_dataset, batch_size=4)
print(f"Optimal num_workers: {best_workers}")Found 19105 files
num_workers=2, Time=39.1067s
num_workers=4, Time=37.5119s
num_workers=6, Time=39.0739s
num_workers=8, Time=38.2929s
num_workers=10, Time=43.1767s
num_workers=12, Time=43.7089s
num_workers=14, Time=42.1315s
num_workers=16, Time=43.8033s
num_workers=18, Time=44.7415s
num_workers=20, Time=46.7260s
num_workers=22, Time=53.0701s
num_workers=24, Time=55.1415s
worker입장에서는 num_workers가 8개일 때 가장 빠르게 load할 수 있네요.
하지만 역시나 정확한 GPU의 throughput을 고려해서 제공해야합니다.
위 코드는 단순한 예시이고 아래와 같은 다른 방법들도 존재합니다.
이중에는 "GPU의 throughput"인 데이터를 받아 loss를 계산하기까지의 시간을 고려하는 내용도 있습니다.
** https://github.com/developer0hye/Num-Workers-Search
** https://chtalhaanwar.medium.com/pytorch-num-workers-a-tip-for-speedy-training-ed127d825db7
spawn과 fork : https://velog.io/@jk01019/spawn-VS-fork
CoW : https://code-lab1.tistory.com/58
dataloder copy-on-write : https://github.com/pytorch/pytorch/issues/13246#issuecomment-905703662
numpy reference count test : https://stackoverflow.com/questions/45087883/python-type-extension-w-numpy-array-reference-count-behavior
numpy reference count test : https://stackoverflow.com/questions/65981307/how-does-numpy-avoid-copy-on-access-on-child-process-from-gc-reference-counting
num_workers 증가했는데 느려지는 경우 : https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813/23
num_workers와 GPU : https://github.com/Lightning-AI/pytorch-lightning/issues/18149#issuecomment-1677616610
num_workers와 GPU : https://github.com/Lightning-AI/pytorch-lightning/discussions/9251'
pin_memory : https://velog.io/@smuhyeon/Pytorch-Dataloader-pinmemory설정
'소개글 > 에세이' 카테고리의 다른 글
| [Generative] Diffusion-based Inversion과 Personalization에 대한 생각 (2) | 2024.04.19 |
|---|---|
| [Spec] 재능, 강점, 그리고 보완 (1) | 2023.10.20 |