
2025. 4. 5. 00:31ㆍ소개글/에세이
Diffusion-based의 T2I(Text-To-Image), T2A(Text-To-Audio) 모델 등 Conditioned Diffusion에서의 "Biases"는 많이는 알려지지 않은 것 같습니다.
아래 그림과 같이 T2I를 활용해 “인물”을 생성하는 경우를 예를 들어 보면, 성별(gender), 인종(race), 혹은 그 외 인구 통계학적(demographics)인 측면에서 데이터가 적은 그룹에 대해 생성이 많이 되지 않는 biases는 명백히 발생하고, 필자도 실제 경험하고 있습니다.

한가지 더 예를 보이자면, 인물외 아래와 같은 "사물"에 대해서도 아래와 같이 구성(compoition)이 다 비슷하게 생성되는 biases가 발생하기도 합니다.

특히나 이는 DiT(Diffusion Transformer)기반인 SD3(Stable Diffusion3) 혹은 Stable Audio Open 등에서 더욱 많이 발생하는 것처럼 보입니다.
예를 들어 특정 논문에서는 SD3를 활용해 “a photo of a CEO”라는 중립적인 프롬프트를 활용해 생성했음에도 불구하고, 거의 100% 가까이 남성 CEO만 생성이 되었다고 하기도 합니다.
** Rethinking Training for De-biasing Text-to-Image Generation: Unlocking the Potential of Stable Diffusion (CVPR'25)
이번 글에서는 이런 Biases에 대한 개인적인 생각을 정리하고, 이를 해결하기 위한 기존의 시도들을 살펴보려고 합니다.
시작하기에 앞서, 이번 글의 대부분은 개인적인 의견이 포함되어있음을 주의부탁드립니다.
이 글과 관련된 용어는 아래와 같습니다.
(+) fairness, balanced
(-) biases, skewed, density-chasm, mode collapse
(해결책) De-biasing
<구성>
1. Diffusion에서의 bias
a. 문제 정의
b. 예상 원인 : Diffusion Model에서의 biases
c. biases 측정 지표
2. Case B-a : Feature Space
a. DiffLens
b. TIW(Time-dependent Importance reWeighting)
3. Case B-b : Sampling & Case B-c : Condition Alignment
a. CADS(Condition-Annealed Sampling)
b. Rethinking Training for De-biasing
c. FT-Diff
글효과 분류1 : 논문 내 참조 및 인용
글효과 분류2 : 용어설명
1. Diffusion에서의 biases
이번 챕터에서는 biases에 대한 정의와 원인을 개인적인 의견으로 분류해보려고합니다.
먼저 biases에 대한 정의한 뒤, 그에 맞는 원인들을 살펴보겠습니다.
살펴보기에 앞서, 결과적으로 우리가 원하는 DM(Diffusion Models)의 학습 목적은 무엇일까요? 저는 아래와 같다고 생각합니다.
"우리가 원하는 데이터 분포"와 비슷하게 생성했으면 좋겠다
근데, 이 "DM이 배워야할 분포"에 대한 정의는 불분명하고, 현실 세계에서도 객관적이고 획일화된 기준은 없습니다.
아래와 같이 두가지 예를 보면 알 수 있습니다.
- (분포의 분류 기준이 주관적) 음악을 생성하기 위해 "재즈"와 "뉴에이지"를 구분해서 데이터를 준비해보았습니다. 하지만 누군가에게는 "재즈"와 "뉴에이지"의 기준이 다를 수도 있습니다.
- (분포의 실제 크기가 주관적) 사람을 생성하기 위해 "특정 직업"에서 "남자"와 "여자"의 비율을 객관적인 비율로 준비해보았습니다. 하지만 누군가에게는 일반적으로 해당 직업의 남자와 여자의 비율이 다르다고 생각할 수도 있습니다.
즉 DM 입장에서는, 배워야 할 "분포의 정의"는 주관적일 수 밖에 없고, 이런 주관적인 분포 기준과 우리가 학습한 DM의 생성 분포가 다를때 "biases가 생겼다"고 말하게 되는 것이죠.
이런 biases를 최소화하며 학습하려면, 이런 주관적인 분포의 기준 중에 어떤 것을 가지고 학습할 것인지 정해야하는데, 이에 따라 biases생기는 서로다른 경우가 있을 것 같습니다.
이렇게 기준에 따른 biases 문제 정의부터 살펴보겠습니다.
a. 문제 정의
상황을 아래와 같이 두가지로 나누어 살펴보겠습니다.
** 이때 데이터 자체의 Low-Quality(저품질)이나 Incorrect Data(부정확한 데이터) 등은 취급하지 않고 가정하겠습니다.
- ɑ상황. 원하는 데이터 분포를 만족하는 데이터셋을 준비한 상태 : 준비된 Data 분포가 기준
- β상황. 원하는 데이터 분포를 만족하지 않는 데이터셋 준비한 상태 : 상상의 분포가 기준
이 두가지 상황에 대해 "어떤 방식으로 분포를 잘못 학습하게 되는지"에 대한 다양한 문제 케이스들을 살펴보겠습니다.
(ɑ상황. 원하는 데이터 분포를 만족하는 데이터셋을 준비한 상태 : 준비된 Data 분포가 기준)
먼저, ɑ상황에 대해 살펴보겠습니다. 운이 좋게도 "완전히 balanced 하다고 생각되는 데이터셋"을 준비했고, 다른 사람이 옳다 하건 옳지 않다 하건 이 "개발자가 준비한 데이터의 분포"가 정답이라고 생각하는 상황입니다.
이때는 DM에 바라는 목표는 아래와 같습니다.
"준비한 데이터 분포"와 비슷하게 생성했으면 좋겠다
이 상황은 준비된 데이터의 분포가 결국 정답입니다. 따라서 결과적으로 우리가 할 수 있는 것은 이 분포와 비슷해지도록 DM을 학습하는 것이겠죠.
근데 데이터를 제대로 완벽하게 준비했는데도 conditional하게 생성된 분포가 실제 데이터 분포와 다른 biases가 생긴다면, 이는 DM을 학습하는 과정이 문제일 것 같습니다.
DM이 "어떻게 biases를 학습하게 되는지"에 대한 케이스를 아래와 같이 세가지로 나누어 봤습니다.
- Case1. 생성 분포의 "중심 위치"가 데이터 분포의 위치와 다르다.
예를 들어 A condition에 따라 생성한 결과의 중심 위치가 데이터의 중심 위치와 다를 때 biases가 발생합니다.
이는 생성 분포의 평균과 연관되었다고 볼 수도 있을 것 같습니다.
ex) ceo(A condition) 결과가 female-male(B condition)위치 중 준비된 데이터보다 female에 가깝게 위치했을 경우, A condition 입장에서는 B condition 중 한가지 분포와만 겹치는 부분이 많이 발생하는 biases로 보입니다. - Case2. 생성 분포의 "크기"가 데이터 분포의 크기와 다르다.
예를 들어 A,B condition에 따라 생성한 결과의 중심 위치가 준비된 데이터의 중심 위치와는 같지만, 분포의 경계선(Boundary)나 크기가 다를 때 biases가 발생합니다.
이는 생성 분포의 경계선(Boundary) 혹은 분산과 연관되었다고 볼 수도 있을 것 같습니다.
ex) female-male(B condition) 중 한가지 분포가 준비된 데이터보다 큰 경우, ceo(A condition)입장에서는 B condition 중 한가지 분포와만 겹치는 부분이 많이 발생해 biases로 보입니다. - Case3. 분포 자체에는 문제가 없지만, 특정 분포에서의 데이터 학습이 잘못된 경우
예를 들어 준비된 데이터의 분포와 중심위치 & 크기는 같지만, 특정 condition에서의 학습이 잘못되는 경우에 biases가 발생합니다.
ex) female-male(B condition) 중 한가지 분포가 준비된 데이터와 다른 분포가 학습된 경우, ceo(A condition)입장에서는 B condition 중 한가지 분포와만 겹치는 부분이 많이 발생해 biases로 보입니다.

(β상황. 원하는 데이터 분포를 만족하지 않는 데이터셋 준비한 상태 : 상상의 분포가 기준)
이번에는, β상황에 대해 살펴보겠습니다. 준비한 데이터 셋은 이미 skewed되어있고, 이를 그대로 학습하면 안될 것 같습니다.
이 상황에 DM이 학습해야할 정답은 어떤 분포일까요?
"상상의 데이터 분포"와 비슷하게 생성했으면 좋겠다
데이터를 원하는대로 준비하지 못했으므로, DM이 생성해야 할 분포는 결국 현재 데이터셋의 분포가 아니라 "상상의 데이터 분포"일 것입니다.
즉, “현재의 데이터 분포”를 떠나서 “우리가 상상하는 데이터의 분포”를 생성하는 DM을 만들어야 한다는 것이죠.
이 상황에서 DM이 "어떻게 biases를 학습하게 되는지"에 대한 케이스 중에는, ɑ상황에서 생긴 DM의 문제 케이스(Case1~3) 또한 그대로 발생할 것입니다.
더 최악인 것은, 이에 추가로 이미 사용할 데이터 자체가 skewed되어 있고 이 데이터를 그대로 학습해야하는 상황이므로, 당연히 데이터가 가지고 있는 skewed factor가 학습에 문제를 끼칠 것 같습니다.
정리하면 아래와 같은 4가지 문제 케이스가 있을 것 같습니다.
- Case1. 생성 분포의 위치가 데이터 분포의 위치와 다르다.
- Case2. 생성 분포의 크기가 데이터 분포의 크기와 다르다.
- Case3. 분포 자체에는 문제가 없지만, 특정 분포에서의 데이터 학습이 덜 된 경우
- Case4. 데이터 자체가 가진 skewed factor가 적용되어 학습되는 문제
단순히 "우리가 원하는 특정 몇개의 condition"에 대해서만 balanced하면 된다면 이상적으로 ɑ상황일 수 있습니다.
하지만 특정 condition에 대해서만 balanced하기를 원하는 것이 아니라면, 일반적으로 데이터가 많은 경우 준비된 데이터가 skewed 되어있는지 모든 condition에 대해 파악하기는 사실 어렵고, 검토된 condition들도 주관적이기 때문에 아마 "완전한 balanced 데이터"를 준비했다고 자신할만한 상황은 적을 것 같습니다.
따라서 대부분의 학습 상황은 β상황에 해당할 것 같습니다.
문제 정의를 위해 두 상황을 기준으로 분포 상의 문제 케이스들을 살펴보았습니다.
이번에는 상황과 무관하게, 위에서 생긴 다양한 biased 분포 문제들이 발생하는 실제 원인이 "DM 내의 어디서 발생"했을지 살펴보겠습니다.
b. 예상 원인 : Diffusion Model에서의 biases
이번에는 위에서 살펴본 문제의 케이스들이 발생하는 위치와 원인을 DM에서 찾아보고자 합니다.
앞서 살펴본 학습할 분포의 기준이 "현재 준비된 데이터"이건 "상상의 데이터"이건, 다양한 분포 차이가 발생하는 위치는 DM에서 크게 두가지로 나뉠 것같습니다.
- Case A. Initial Noise Space : 초기 노이즈
- Case B. Added Noise Space : 학습해 더해지는 diffusion 노이즈

위 각각의 위치에서 생기는 원인들을 조금더 상세히 분류해서 살펴보겠습니다.
- Case A. Initial Noise Space
- a. random space
- b. latent space (LDM)
- Case B. Added Noise Space
- a. Network Generation Mechanism Influence : Feature Space
- b. Sampling Condition Mechanism Influence : Sampling
- c. Network Condition Mechanism Influence : Condition Alignment
(Case A. Initial Noise Space)
먼저 CaseA는 denoise를 시작할 초기 noise자체에서 biases가 존재하도록 학습된 경우입니다. 나누어 살펴보겠습니다.
- a. random space
- b. latent space (LDM)

▶ CaseA-a는 학습한 초기 노이즈의 random space 자체가 skewed되어서, 생성을 시작할 때 이미 고르지 못한 상태에서 시작하는 경우입니다.
하지만, 초기 노이즈는 보통 isotropic noise를 직접적으로 활용하기 때문에, 사실 학습에서 정말 운이 좋지 않은 한 biases가 생길 확률은 낮을 것 같습니다.
▶ CaseA-b는 VAE(Variational Autoencoder) encoder-decoder를 통한 Latent의 분포가 skewed된 결과를 만들어, 생성을 시작할 때 이미 고르지 못한 상태에서 데이터 분포를 표현하고 이 분포를 기준으로 생성을 시작하는 경우입니다.
Latent는 VAE encoder를 통해 만들어진 "연산 크기" 개수 만큼의 [평균(mean), 분산(variance)]을 활용해, 각각 "연산 단위"에서 분포벡터로 만들어지며 표준정규분포에 가까운 분포가 되도록 기대됩니다.
** 연산 크기 : 이미지의 경우 이미지 사이즈 in Latent, 오디오의 경우 샘플 사이즈 in Latent
** 연산 단위 : 이미지의 경우 Pixel in Latent 단위, 오디오의 경우 Time Frame in Latent 단위
하지만, VAE encoder에서는 이 Latent를 input에 의존해서 만들어 내기 때문에 학습 중 biases가 생길 수 있습니다.
이는 살펴볼 필요는 있어보입니다만 VAE 혹은 VAE 기반 모델에서는 latent 공간이 표준 정규분포처럼 되도록 유도하기 위해 KL divergence Loss를 보통 활용하기 때문에 biases를 줄일 수 있는 방법이 있어 학습을 잘 하면 해결될 수도 있습니다.
** KL Loss에 대한 추가정보가 궁금하시면 참조하세요
-----------------------------------------------------------------
<VAE의 KL Loss>
VAE에서 KL Loss는 Latent 공간이 표준 정규분포처럼 되도록 유도하기 위한 Loss입니다.
위 Loss가 아닌, 일반적인 KL(Kullback-Leibler) Divergence Loss는 아래와 같이 생겼습니다.
$$\mathrm{KL}\left( q(z) \,\|\, p(z) \right) = \int q(z) \log \left( \frac{q(z)}{p(z)} \right) \, dz$$
- $q(z)$: 실제 분포 (posterior or approximate distribution)
- $p(z) $: 목표 분포 (prior)
- $\log \left( \frac{q(z)}{p(z)} \right)$: 두 분포의 차이를 측정하는 로그 비율
여기에 일반화된 Gaussian vs Gaussian의 KL divergence를 적용하기 위해 $q(z)=\mathcal{N}(\mu,\Sigma)$, $p(z)=\mathcal{N}(\mu_0, \Sigma_0)$를 대입하면 아래와 같을 것입니다.
$$\mathrm{KL}\left( \mathcal{N}(\mu, \Sigma) \,\|\, \mathcal{N}(\mu_0, \Sigma_0) \right)
= \frac{1}{2} \left[ \log \frac{|\Sigma_0|}{|\Sigma|} - d + \mathrm{Tr}(\Sigma_0^{-1} \Sigma) + (\mu_0 - \mu)^\top \Sigma_0^{-1} (\mu_0 - \mu) \right]$$
- $d$: 차원수
- $\Sigma, \Sigma_0$: 공분산행렬
- $|\cdot|$ : 행렬식
- $Tr$ : 대각합 (Trace)
다음으로 위에서 표준 정규 분포로 만들어주기 위해 $\mu_0 = 0, \Sigma_0 = I$를 넣으면 아래와 같은 수식이 되고, 이는 실제 KL Loss로 활용되는 수식입니다.
$$\mathrm{KL}\left(q(z|x) \,\|\, \mathcal{N}(0, I)\right)
= \frac{1}{2} \sum_{i=1}^{d} \left( \mu_i^2 + \sigma_i^2 - \log \sigma_i^2 - 1 \right)$$
- $q(z|x)$: 인코더가 추정한 posterior 분포
- $\mathcal{N}(0, I)$ : 표준 정규 분포 (평균 0, 단위 분산)
- $\mu_i^2,\sigma_i^2$ : 인코더가 출력한 평균과 분산
- $d$ : latent vector의 차원 수
근데 VAE에서는 정확히 어디의 분포를 표준정규분포와 비슷하게 만든다는 것일까요? 아래 코드는 실제 KL Loss를 구하는 식입니다.
kl = (mean * mean + var - logvar - 1).sum(1).mean()
각 상황에 대해 코드 상의 dimension을 살펴보면 알 수 있습니다.
1. Time-series (audio 등) 입력일 경우의 예
- Input Shape: [Batch, 2, Samplesize]
- Latent Shape: [Batch, C=64, T=Samplesize/D]
- KL Loss : [Batch, T]
- 즉, 각 시간 프레임 t 별로 latent vector([C], 64차원)이 표준 정규분포에 가까워지도록 학습됩니다.
2. Image 입력일 경우의 예
- Input Shape: [Batch, 3, H, W]
- Latent Shape: [Batch, C=64, H', W'] (downsampling된 spatial map)
- KL Loss : [Batch, H' × W']
- 즉, 각 위치 (pixel) 별로 latent vector([C], 64차원)이 표준 정규분포에 가까워지도록 학습됩니다.
위 두가지 예시 중 1. Time series일 경우를 예로 코드 상에서 다시 살펴보겠습니다.
- (mean * mean + var - logvar - 1) : [Batch, C, T]
- (mean * mean + var - logvar - 1).sum(1) : [Batch, T] → KL Loss의 정의
- (mean * mean + var - logvar - 1).sum(1).mean() : 모든 배치와 time series에 대해 위 KL Loss의 평균 값 적용
kl = (mean * mean + var - logvar - 1).sum(1).mean()
정리하자면, 개별 위치에서의 "Latent Vector"의 분포가 각각 $\mathcal{N}(0, I)$를 따르도록 유도되고, 그 결과를 평균 또는 합산하여 전체 loss를 계산합니다.
그럼 두가지 질문이 있습니다.
- 1. 위치별 Latent Vector들이 표준정규분포에 가까워지도록 유도하겠지만, 완벽하지 않아 bias가 생길 수도 있다?
- 2. Latent Vector 스페이스가 아닌, 모든 Latent Sample 스페이스에서도 biases가 발생할까?
1. 위치별 Latent Vector들이 표준정규분포에 가까워지도록 유도하겠지만, 완벽하지 않아 biases가 생길 수도 있다?
당연히 맞습니다. KL divergence Loss는 soft constraint이기 때문에 "표준정규분포와 비슷하게 만들어라"라고 유도할 뿐이지, 반드시 그렇게 되도록 보장하지 않습니다.
특히 보통 함께 사용하는 Reconstruction Loss(예: MSE, BCE 등)가 학습 중 더 중요하게 작용하면, KL Loss 항은 약화되어 Latent가 표준정규분포에서 멀어지는 경우도 자주 발생한다고 합니다.
** 이것을 posterior collapse 또는 latent code underutilization이라고 하기도 합니다.
** 이를 해결하기 위한 β-VAE, InfoVAE, KL annealing, free-bits 같은 기법들은 참조하세요
2. Latent Vector 스페이스가 아닌, 모든 Latent Sample 스페이스에서도 biases가 발생할까?
당연히 각 이미지 픽셀의 모든 Latent Vector가 표준정규분포를 따른다면, 이미지의 Latent Space도 표준정규분포를 따르겠지만, 그렇지 않은 경우는 이미지 Latent Space 입장에서 봤을때도 역시나 표준 정규분포의 집합이 아닐수도 있습니다.
하지만 이는 학습시에 Latent Vector 값들을 결정하는 mean과 variance가 VAE encoder에 의해 결정되기 때문이 더 큽니다.
즉, 네트워크가 잘 학습되지 않거나 데이터가 편향되어 있을 경우, Latent Sample Space 상에서도 biases가 발생할 수 있다는 것입니다.
실제로 시각적으로 나타내기 위해 t-SNE나 PCA로 각 Latent들을 시각화해보면, 원형의 $\mathcal{N}(0, I)$ 분포 대신 타원형 클러스터, 한쪽으로 몰린 모양, 빈 공간이 많은 구조가 나오는 경우가 많습니다.
** 실제 표준정규분포와 얼마나 다른지를 측정하려면 Wasserstein distance, MMD, t-SNE, Latent histogram을 참조하세요.

결국 VAE는 Latent의 분포를 $p(z)=\mathcal{N}(0,I)$, 즉 fully factorized Gaussian prior을 전제로 하지만, (Isotropic Prior Assumption)
실제로는 이 데이터 $x$를 보고 추정하고 학습하는 Latent $z$의 분포, 즉 posterior $q(z|x)$는 데이터에 따라서 서로 상관관계가 있을 수도 있으며, 이를 위 Isotropic Prior Assumption의 한계라고 볼 수 있습니다.
-----------------------------------------------------------------
(Case B. Added Noise Space)
다음으로 CaseB. 는 denoise 과정에서 사용하는 DM의 output인 noise 자체에 biases가 존재하도록 학습된 경우입니다. 나누어 살펴보겠습니다.
- a. Network Generation Mechanism Influence : Feature Space
- b. Sampling Condition Mechanism Influence : Sampling
- c. Network Condition Mechanism Influence : Condition Alignment

▶ CaseB-a는 DM 모델을 학습하는 과정에서 DM 자체의 문제로 인해 biased feature 분포를 만들어 생성하는 경우입니다.
biased 데이터셋을 활용하는 경우에 생기는 일반적인 문제점이 원인일 수도 있고, DM의 고질적인 학습 과정의 문제가 원인일 수도 있겠죠.
▶ CaseB-b는 DM에서 생성된 noise를 더하는 샘플링 과정에서 biased 분포를 만들어 생성하기 때문이라고 생각하는 경우입니다.
샘플링 과정에서 biases가 생기는 것은 조금은 명백해보입니다.
예를 들어 CFG를 활용해 conditoned output을 더하는 경우에 diversity가 줄어든다는 것은 많은 논문에서 이미 다루고 있습니다.
그 예를 간단히 살펴보겠습니다.
먼저, $\boldsymbol{z}$가 unconditional embedding이고 $\boldsymbol{c}$가 conditional embedding이라고 했을 때 CFG scale $\alpha$로 이루어진 noise결과 $\tilde{\epsilon}$는 아래와 같습니다.
$$\tilde{\epsilon}_\theta(\boldsymbol{z},\boldsymbol{c})=(1+\alpha)\cdot\epsilon_\theta(\boldsymbol{z},\boldsymbol{c})-\alpha\cdot\epsilon_\theta(\boldsymbol{z})$$
** CFG의 정의에 대해 살펴보려면 더보기를 참조하세요
-----------------------------------------------------------
<CFG의 두가지 정의>
CFG는 두가지 형태의 식으로 정의되어 활용됩니다. 그 두가지는 아래와 같습니다.
1. CFG 정의 $\omega_a$ : 최초로 정의된 CFG수식입니다.
** Classifier-Free Diffusion Guidance (arxiv’22) - Equation (6)
- uncond를 기준으로 cond방향으로 선형 외삽(extrapolation) 하는 느낌
- guidance scale인 $\omega_a$가 클수록 cond의 영향력이 커지지만, 7.5와 같은 큰 값도 활용
$$\begin{aligned}
\tilde{\epsilon}_\theta(\boldsymbol{z},\boldsymbol{c})&=(1+\omega_a)\cdot\epsilon_\theta(\boldsymbol{z},\boldsymbol{c})-\omega_a\cdot\epsilon_\theta(\boldsymbol{z})\\
&=\epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}) + \omega_a \cdot \left( \epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}) - \epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}_{null}) \right)\\
&{\color{OliveGreen}=\epsilon_{cond}+\omega_a(\epsilon_{cond}-\epsilon_{uncond})}
\end{aligned}$$
2. Imagen CFG $\omega_b$ : Imagen 논문에서 활용된 CFG수식으로, Diffusers 패키지 및 대부분의 구현에 활용됩니다.
** Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (NIPS’22) - Equation (2)
** diffusers > pipeline_stable_diffusion_xl.py#L1221
- uncond와 cond 사이를 선형 보간(Interpolation)
- guidance scale인 $\omega_b$ 클수록 cond의 영향력이 커지지만, 0.0에서 1.0사이는 interpolation, 1.0보다 크면 extrapolation
$$\begin{aligned}
\tilde{\epsilon}_\theta(\boldsymbol{z},\boldsymbol{c})&=\omega_b\cdot\epsilon_\theta(\boldsymbol{z},\boldsymbol{c})+(1-\omega_b)\cdot\epsilon_\theta(\boldsymbol{z})\\
&=\epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}_{null}) + \omega_b \cdot \left( \epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}) - \epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}_{null}) \right)\\
&{\color{OliveGreen}=\epsilon_{uncond}+\omega_b(\epsilon_{cond}-\epsilon_{uncond})}
\end{aligned}$$
위 두 $\omega_a$와 $\omega_b$의 관계는 $\omega_a=\omega_b-1$입니다.
-----------------------------------------------------------
먼저 CADS논문에서는 conditional DM이 높은 CFG를 활용하는 상황에서는 low diversity를 보이는 문제가 있다고 지적합니다.
** CADS: Unleashing The Diversity of Diffusion Models through Condition-Annealed Sampling(ICLR'24)
아래는 Guidance Scale에 따른 평가지표의 결과입니다. 아래 DDPM를 보면 높은 CFG를 활용할 때, Quality(FID↓, IS↑, Precision↑)를 개선하지만 Diversity(Recall↑)가 나빠집니다.
** 평가 지표는 아래에서 다시 설명합니다.

본 논문에서는 높은 CFG scale로 인한 집중도가 매우 높은 조건부 분포(highly peaked conditional distribution)가 다수의 샘플을 특정 mode로 이끌어가기 때문이라고 추측하고, gaussian noise를 활용해 이런 conditional 분포를 smooting하는 방법을 제안합니다.
다음으로 또 다른 논문에서도 CFG를 사용하면 특정된 의미론적 text condition에 의해 샘플의 diversity가 부족해진다고 강조합니다.
** Rethinking Training for De-biasing Text-to-Image Generation: Unlocking the Potential of Stable Diffusion (CVPR'25)
minor가 나타나는 비율을 “Minor Attribute Ratio”, major가 나타나는 비율을 “Major Attribute Ratio”라고 했을 때, 위 현상을 확인하기 위해 CFG가 늘어났을 때의 CLIP Score와 Major Attribute Ratio를 측정해냅니다.
** majority attribute : 생성된 이미지에서 자주 출현하는 이미지 attribute
** minority attribute : 생성된 이미지에서 그 반대 케이스 attribute
** neutral attribute : 중립적인 이미지를 생성해야하는 attribute
** CLIP Score : 결과와 텍스트간의 연관성
아래 결과는 CFG scale이 달라질 때 5000개의 이미지(5개의 CFG Scale x 1000번)를 4개의 직업에 대한 생성 결과입니다.

결과적으로 CFG가 감소할수록 Major Attribute Ratio도 감소하는 것을 볼 수 있습니다.
즉, CFG가 줄어들면 biases가 강한 attribute의 등장이 줄어드는 것을 보아, biases와의 연관성을 보이는 것입니다.
이에 따라 Sampling 과정에서의 biases는 꽤나 명백해보입니다.
▶ CaseB-c는 DM 네트워크 내부의 conditioning 과정으로 인해 biased 분포가 만들어진다고 생각하는 경우입니다.
즉, DM 자체는 skewed 된 분포를 생성하지 않지만 DM과 condition의 alignment가 skewed되어 있기 때문에 해당분포를 정확하게 생성하지 못한다는 것이죠.
여기까지 DM내에서 원인이 어디서 발생할지에 대한 구분을 CaseA, CaseB로 나누어 살펴보았습니다.
CaseA의 경우 원인을 해결할 수 있는 수단이 있기 때문에, 이번 글에서는 "Case B. Added Noise Space"에 대한 원인들을 해결하려고 하는 시도들을 위주로 살펴볼 예정입니다.
c. biases 측정 지표
이제 위와 같은 원인들을 해결하기 위한 방법들을 살펴보기 전에, 생성결과를 보고 "얼마나 de-biased 되었는지" 측정할 수 있는 Evaluation Metric들을 먼저 살펴보려고 합니다.
아래는 논문들에서 등장한 1. Diversity, 2. Quality, 3. Condition Alignment와 관련된 각각의 지표들입니다.
1. Diversity
- ↓FID : 모델이 생성한 이미지들의 feature를 다른 Test Set의 feature과 비교하는 방법으로, 생성된 이미지의 Quality와 Diversity를 한번에 측정하는 방법입니다.
- ↑Improved Recall : true distribution 이미지 중 생성된 이미지에 포함될 비율로, 생성된 이미지가 얼마나 많은 범위를 포용하는지에 대한 diversity를 의미합니다.
** https://tkayyoo.tistory.com/206 - ↓MSS(Mean Similarity Score) : feature extractor를 활용해 얻은 similarity matrix의 similarity matrix의 평균입니다.
** MSS의 수식이 궁금하시면 아래 더보기를 참조하세요 - ↑Vendi Score : feature extractor를 활용해 얻은 similarity matrix의 Von Neumann Entropy입니다.
** Vendi Score의 수식이 궁금하시면 아래 더보기를 참조하세요 - ↓FD(Fairness Discrepancy) : Reference 분포(일반적으로 uniform)와 class들 기준으로 biased된 distribution 사이의 Euclidean distance입니다.
** FD의 수식이 궁금하시면 아래 더보기를 참조하세요 - ↑CLIP-I : 생성된 이미지들의 CLIP embedding과 실제 이미지의 CLIP embedding간의 Cosine Similarity 평균입니다.
** DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation(CVPR’23) - ↕︎Log Gender Ratio : 생성된 이미지의 male과 female의 비율입니다.
** Log Gender Ratio의 수식이 궁금하시면 아래 더보기를 참조하세요 - ↓bias(P) : prompt P에 대해 생성된 그룹들(classes)의 빈도수 차이가 얼마나 적은지를 나타내는 지표입니다.
** bias(P)의 수식이 궁금하시면 아래 더보기를 참조하세요 - ↕(Mode Test) Minority Attribute Ratio : 해당 논문에서 소개된 Mode Test를 진행했을 때, minor attribute가 다시 나타나는 비율입니다. 자세한 내용은 아래 논문 설명을 참고하세요.
** Rethinking fid: Towards a better evaluation metric for image generation (CVPR'24)
--------------------------------------------------------------
<Vendi Score와 MSS 수식>
1. Vendi Score : similarity matrix의 Von Neumann Entropy를 구하는 방법으로, 행렬의 eigen values 분포가 얼마나 퍼져있는지를 살펴보는 방법입니다.
** The vendi score: A diversity evaluation metric for machine learning (arxiv’22)

먼저 원래 Von Neumann Entropy $\mathcal{H}(\rho)$는 아래와 같이 생겼습니다.
** $\rho$ : density matrix
** $\lambda_i$ : 해당 density matrix의 eigen value들
$$\mathcal{H}(\rho)= -\mathrm{tr}(\rho \log \rho) = -\sum_i \lambda_i \log \lambda_i$$
이제 여기에 density matrix를 similarity matrix $K_x$로, 대체 하면 수식은 아래와 같습니다.
** $ \mathbf{k}$ : user-defined similarity function
** N : N개의 input
$$\begin{aligned}
{VendiScore}(\mathbf{x}, \mathbf{k}) &= \exp\left( -\mathrm{tr}\left( \frac{K_x}{N} \log \frac{K_x}{N} \right) \right)\\
&= \exp\left( -\sum_i \lambda_i \log \lambda_i \right)
\end{aligned}$$
entropy이기 때문에 그 값이 클수록 다양하다고 할 수 있습니다.
2. MSS(Mean Similarity Score)
모든 이미지 쌍에 대해 얼마나 비슷한지를 단순 평균하는 방법입니다.
$${MSS}(K_y) = \frac{1}{N^2} \sum_{i=1}^{N} \sum_{j=1}^{N} K_y(i,j)$$
평균적으로 similarity가 얼마나 높은지를 측정하는 것이므로, 낮을수록 diversity가 좋습니다.
위 두 Metric 모두 같은 condition으로 생성된 이미지들 간의 Pair-wise Cosine Similarity Matrix $K_\boldsymbol{y}$를 얻어 내기 위해서 SSCD를 활용하는데 궁금하시면 아래 추가적인 더보기를 참조하세요
--------------------------------------------------------------
--------------------------------------------------------------
<SSCD(Self Supervised Copy Detec- tion) Feature Extractor>
** A self- supervised descriptor for image copy detection (CVPR’22)
Content Moderation이란 플랫폼(앱, 웹사이트 등)에 업로드되는 콘텐츠 중 부적절하거나 규칙에 어긋나는 콘텐츠(폭력성, 혐오 표현, 저작권 침해, 성인물 등)를 차단하거나 조치하는 과정입니다.
이를 위해 객체 수준에서 조명, 카메라 위치, 포즈 변화에 따라 같은 내용을 담았는지 판단하는 ReID(Re-Identification)이나 전체 이미지 차원에서 원본/복제/변형본 여부를 판별하는 Image Copy Detection을 활용하는데, 이 중 Image Copy Detection은 아래와 같은 두단계로 진행됩니다.
- Step1. Retrieval Stage : 해당 이미지와 비슷할 candidate를 제공하는 단계
- Step2. Verification Stage : Local Descriptor Matching을 활용해 검증하는 단계
이 중에 SSCD는 첫번째 Step1. 단계에 집중하며, ResNet-50 Conv 구조를 활용해 feature를 extract하는데 아래와 같은 Contribution을 제공합니다.
- Entropy Regulatization : feature vector들이 서로 너무 가까워지는 걸 방지해서 임베딩 공간에 다양성(spread)을 확보하기 위해 아래와 같은 Differential Entropy Regularization Loss를 기존 contrastive InfoNCE Loss에 추가합니다.
** [Differential Entropy Regularization, KoLeo(Kozachenko-Leononenko) Loss] Spreading vectors for similarity search(arxiv’19)
** N은 전체 샘플수, $z_i$는 i번째 feature vector, $\hat{P}_i$는 i번째 샘플과 같은 source들의 집합을 의미
$$L_{{KoLeo}} = -\frac{1}{N} \sum_{i=1}^{N} \log \left( \min_{j \notin \hat{P}_i} \| z_i - z_j \| \right)$$ - Inference-time Score Normalization : 마지막 CNN activation map을 vector로 만들어 주기 위한 기존 Mean Pooling에서 GeM(Generalized Mean Pooling)으로 대체합니다.
이는 feature map에서 더 discriminative한 벡터를 만들기 위해 사용됩니다.
** [GeM] Multigrain: a unified image embedding for classes and instances (arxiv’19)
** $x$는 feature들의 집합, $|x|$는 feature의 개수, $p$는 파라미터를 의미
$${GeM}(x) = \left( \frac{1}{|x|} \sum_{i=1}^{|x|} x_i^p \right)^{\frac{1}{p}}$$ - MixUp/CutMix Augmentations : 두 이미지의 pixel-wise weighted average를 활용하는 MixUp과 하나의 이미지에서 rectangular region을 움직이는 CutMix 방법을 활용해 augmentation을 진행합니다.
위 소개된 feature extractor에 간단한 2-Layer MLP를 붙여 학습하며 inference과정에서는 MLP는 제거하는 기존의 SimCLR방법과 달리,
본 논문에서는 아래 그림과 같이 MLP 대신 target descriptor size로 프로젝션하는 단순한 Linear Projection을 사용하고 학습과 inference시 동일하게 동작합니다.
** [SimCLR] A simple framework for contrastive learning of visual representations (ICLR’20)
위와 같이 만들어진 Descriptors들은 consine similarity 혹은 L2 distance를 통해 similarity가 구해지며, 전체 구조는 아래와 같습니다.

--------------------------------------------------------------
--------------------------------------------------------------
<FD(Fairness Discrepancy) >
** Balancing act: Distribution-guided debiasing in diffusion models (CVPR’24)
** Fair generative modeling via weak supervision (ICML’20)
attribute $\boldsymbol{a}$가 있을 때, $\boldsymbol{a}$를 잘 구분하는 classifier $C_\boldsymbol{a}$가 있다고 가정하면, classifier의 결과와 true distribution에 해당하는 분포간의 차이를 의미합니다.
** $\boldsymbol{y}$ : classifier $C_\boldsymbol{a}$의 softmax output
** $\bar{p}$ : $\boldsymbol{y}$와 같은 차원의 uniform vector
** $p_\theta$ : 생성된 이미지의 분포
$$\|\bar{p}-\mathbb{E}_{\boldsymbol{x}\sim p_\theta(\boldsymbol{x})}(\boldsymbol{y})\|_2$$
낮은 FD score는 더욱 balanced함을 의미합니다.
즉, 낮을 수록 attribute $\boldsymbol{a}$에 대해 uniform distribution 가까운 분포라는 것을 의미합니다.
--------------------------------------------------------------
--------------------------------------------------------------
<Log Gender Ratio>
** Dissecting and Mitigating Diffusion Bias via Mechanistic Interpretability (CVPR'25)
생성된 이미지의 male과 female의 비율을 나타내는 것으로, 0인 경우 가장 balanced합니다.
$$log\frac{p(Male)}{1-p(Male)}$$
--------------------------------------------------------------
--------------------------------------------------------------
<Bias(P)>
** Finetuning text-to-image diffusion models for fairness (ICLR’24)
prompt P에 대해 생성된 그룹들(classes)의 빈도수 차이가 얼마나 적은지를 나타내는 지표입니다.
** K : group의 개수
** freq(i) : 생성된 이미지 중에 group i가 등장할 빈도수
$$bias(P)=\frac{1}{K(K-1)/2}\sum_{i,j\in[K]:i<j}|freq(i)-freq(j)|$$
--------------------------------------------------------------
2. Quality
- ↓FID : 모델이 생성한 이미지들의 feature를 다른 Test Set의 feature과 비교하는 방법으로, 생성된 이미지의 Quality와 Diversity를 측정하는 방법입니다.
- ↓CMMD score : FID와 다르게, Inception 대신 CLIP을 활용하고 MDD라는 기법으로 distance를 측정하는 기법입니다.
** CMMD가 궁금하시면 아래 더보기를 참조하세요 - ↑IS(Inception Score) : 모델이 얼마나 데이터셋의 class distribution을 잘 파악하는지에 대한 지표입니다.
- ↑Improved Precision : 생성된 이미지 중에 true distribution 이미지에 포함될 비율로, 얼마나 정확하게 데이터와 비슷하게 생성했는지를 판단합니다.
** https://tkayyoo.tistory.com/206
--------------------------------------------------------------
<CMMD(CLIP-MMD) Distance>
** Rethinking fid: Towards a better evaluation metric for image generation (CVPR’24)
기존의 FID는 아래와 같은 단점이 있다고 합니다.
- Representation Bias : 측정에 사용되는 Inception-v3 embeddings는 다양하고 풍부한 컨텐츠를 반영하지 못한다.
- Incorrect Normality Assumption : FID는 양쪽 분포를 정규분포라고 가정하고 거리를 측정하지만, 실제 생성 이미지의 분포는 정규분포가 아닐 수 있다.
- Poor Sample Complexity : 적은 샘플 수로는 안정적인 결과를 얻기 어렵다.
- Contradicts Human Judgments : 사람이 실제로 평가한 human raters와 다르다.
- Inconsistency Across Sample Sizes : 일관성이 부족하다.
- Distortion Insensitivity : 이미지에 왜곡이 있는 경우에도 FID는 왜곡 정도를 민감하게 반영하지 못한다.
위와 같은 단점들을 해결하기 위한 시도가 있었습니다.
** Effectively unbiased FID and inception score and where to find them (arxiv’19) : FID가 biased estimator이므로, biase-free한 $FID_\infty$를 제안
** Sur la distance de deux lois de probabilité(’57) : FID측정시 compression이나 resize가 variation을 유도해 anti-aliased 연산을 시도
하지만 아래 표를 보면 다양한 distance와 embedding에 대한 옵션별로 기능은 아래와 같습니다.
** 왼쪽위가 FID, 본 논문의 CMMD가 오른쪽 아래

따라서 위를 반영해 본 논문에서는 CLIP embeddings를 Guassian RBF kernel에 대한 MMD(Maximum Mean Discrepancy) distance를 활용해 측정하는 CMMD방법을 제안합니다.
그럼 CMMD가 등장하는 과정을 살펴보겠습니다.
먼저, 두개의 확률 분포 P와 Q가 있을 때, Frechet distance는 아래식의 첫번째와 같이 정의되고, 이에 대한 Frechet distance의 closed form solution이 두번째 줄입니다.
** ${\Gamma(P, Q)}$ : 두 P와 Q사이의 모든 coupling을 의미합니다.
** 이는 $\mathbb{R}^d$에서의 Wasserstein-2 distance와 같습니다.
** $\mu_P,\mu_Q$는 각 분포의 평균 $\Sigma_P,\Sigma_Q$ 는 각 분포의 covariance
** close form solution은 두 분포가 multivariate normal distribution일때만 성립합니다.
$$\begin{aligned}
{dist}_F^2(P, Q) &:= \inf_{\gamma \in \Gamma(P, Q)} \mathbb{E}_{(\boldsymbol{x}, \boldsymbol{y}) \sim \gamma} \left\| \boldsymbol{x} - \boldsymbol{y} \right\|^2\\
&= \| \mu_P - \mu_Q \|_2^2 + \operatorname{Tr}(\Sigma_P + \Sigma_Q - 2(\Sigma_P \Sigma_Q)^{1/2})
\end{aligned}$$
이 때, FID는 위 Frechet Distance를 Inception embedding 간의 distance를 측정해 활용하는데, 이에 대해 아래와 같은 두가지 문제를 지적합니다.
- Inception Embedding은 d=2048의 높은 차원을 가지므로, covariance 2048x2048을 적은 샘플에서 얻으면 에러가 크다.
- Inception embedding은 실제로는 normally distributed하지 않다.
따라서 아래와 같이 해결책을 제안합니다.
- CLIP embeddings를 활용
** CLIP 또한 normally distributed 되지는 않았다고 합니다. 하지만 아래와 같이 normality에 대한 가정이 필요없는 다른 distance를 사용합니다. - Gaussian RBF kernel을 활용한 결과에 MMD(Maximum Mean Discrepancy) distance를 적용
두가지를 활요했을 때의 장점은 각각 아래와 같습니다.
- CLIP embedding : 기존의 Inception v3는 1000개의 제한된 classes로 학습되었지만, CLIP은 400 million의 text-image pair로 학습이 되기 때문에 다양하고 복잡한 컨텐츠를 표현하는데 더욱 유리하다고 합니다.
** CLIP은 CLIP ViT-L/14@336px 을 사용했다고 합니다. - MMD : 두 분포 사이의 distance를 구하기 위해 MMD distance를 사용하는데, 두 샘플 집단이 같은 distribution으로부터 나왔는지를 확인하는 방법으로, 그 차이를 측정하는데에도 활용됩니다.
** A kernel method for the two-sample-problem (NIPS’06)- Distribution-Free : characteristic kernel을 활용하면 기존 normality 가정 없이 distribution-free하게 적용할 수 있습니다.
** Characteristic kernels on groups and semigroups (NIPS’08) - Unbiased : 기존에 유한한 샘플에 대해 FID를 적용하면 bias가 존재한다고 하는 것과 반해, unbiased합니다.
- Efficient : 기존에 dxd covariance matrix를 사용해야하는 것과 다르게, 고차원의 vector과 동작하더라도 효율적입니다.
- Distribution-Free : characteristic kernel을 활용하면 기존 normality 가정 없이 distribution-free하게 적용할 수 있습니다.
위와 같은 해결책을 활용한 결과적인 수식은 아래와 같습니다.
** ${dist}_{{MMD}}^2$는 분포간의 결과이며, $\widehat{{dist}}_{{MMD}}^2(X, Y)$는 샘플을 활용한 방법입니다.
** $\boldsymbol{x},\boldsymbol{x}’$는 P에 의한 독립적인 분포, $\boldsymbol{y},\boldsymbol{y}’$는 Q에 의한 독립적인 분포
$$\begin{aligned}
{dist}_{{MMD}}^2(P, Q) &:= \mathbb{E}_{\boldsymbol{x}, \boldsymbol{x}'}[k(\boldsymbol{x}, \boldsymbol{x}')] + \mathbb{E}_{\boldsymbol{y}, \boldsymbol{y}'}[k(\boldsymbol{y}, \boldsymbol{y}')] - 2 \mathbb{E}_{\boldsymbol{x}, \boldsymbol{y}}[k(\boldsymbol{x}, \boldsymbol{y})]\\
\widehat{{dist}}_{{MMD}}^2(X, Y) &=
\frac{1}{m(m-1)} \sum_{i=1}^{m} \sum_{j \neq i}^{m} k(\boldsymbol{x}_i, \boldsymbol{x}_j)
+ \frac{1}{n(n-1)} \sum_{i=1}^{n} \sum_{j \neq i}^{n} k(\boldsymbol{y}_i, \boldsymbol{y}_j)
- \frac{2}{mn} \sum_{i=1}^{m} \sum_{j=1}^{n} k(\boldsymbol{x}_i, \boldsymbol{y}_j)
\end{aligned}$$
위의 $k(\cdot)$는 positive definite kernel을 의미하는데, 이는 Gaussian RBF kernel(혹은 Characteristic Kernel)를 활용했으며 이 kernel의 수식은 아래와 같습니다.
** $\sigma$는 bandwidth 파라미터로 본 논문에서는 $\sigma=10$을 사용했지만, 큰 영향이 있지는 않다고 합니다.
$$k(\boldsymbol{x},\boldsymbol{y})=exp(-\|\boldsymbol{x}-\boldsymbol{y}\|^2/2\sigma^2)$$
결과적으로 위와 같이 Gaussian Kernel을 활용한 MMD 결과는 완전히 다를 때는 최대 2.0, General Distribution일 때는 결과가 작습니다.
하지만 이를 0~1000으로 바꾸어 사용한다고 합니다.
--------------------------------------------------------------
3. Condition Alignment (Controllability, Semantic Feature Coherence)
- ↑ CLIP score(CLIP-T) : Text-To-Image Synthesis의 결과가 잘 나왔는지 확인되는데 사용되며, CLIP text embedding과 CLIP image embedding간의 Cosine Similarity 평균입니다. Semantic Similarity 혹은 Prompt Fidelity라고 불립니다.
** Learning transferable visual models from natural language supervision (ICML'21)
** DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation(CVPR’23) - ↑CLIP-D : 위와 같이 CLIP text embedding과 생성된 이미지의 CLIP image embedding간의 Cosine Similarity를 의미하지만, text와 image의 attribute를 반영한 결과입니다.
- ↑Top-1 accuracy : Class-Conditional 모델의 결과가 잘 나왔는지 확인하는데 사용됩니다.
- ↓MPJPE(Mean-Per-Joint Pose Error) : Pose-to-Image 모델의 결과가 잘 나왔는지 확인하는데 사용되며, 관절 위치가 잘 나왔는지를 확인해 수치화 합니다.
** MPJPE의 수식이 궁금하시면 아래 더보기를 참조하세요
--------------------------------------------------------------
<MPJPE(Mean-Per-Joint Pose Error)>
예측한 관절 위치(predicted joints) 와 정답 관절 위치(ground truth joints) 간의 거리 오차를 관절별로 평균한 값입니다.
** $J$ : 관절의 총 개수
** $\hat{\mathbf{x}}_j$ : 예측한 j 번째 관절의 좌표
** ${\mathbf{x}}_j$ : 정답 j 번째 관절의 좌표
$${MPJPE} = \frac{1}{J} \sum_{j=1}^{J} \| \hat{\mathbf{x}}_j - \mathbf{x}_j \|_2$$
--------------------------------------------------------------
--------------------------------------------------------------
<CLIP-D>
** Dissecting and Mitigating Diffusion Bias via Mechanistic Interpretability (CVPR'25)
target attribute text embedding $\boldsymbol{e}_{attr}$와 생성된 attribute image embedding $\boldsymbol{e}_{img}^{gen}$간의 cosine similarity를 의미합니다.
$$CLIP-D=\frac{\boldsymbol{e}_{attr}\cdot \boldsymbol{e}_{img}^{gen}}{\|\boldsymbol{e}_{attr}\|\|\boldsymbol{e}_{img}^{gen}\|}$$
--------------------------------------------------------------
2. Case B-a : Feature Space
먼저, biases가 DM 모델을 학습하는 과정에서 DM 자체에서 생기는 문제일 때, 어떻게 이 문제를 해결하려는 시도가 있었는지를 살펴보려고 합니다.

제가 찾아 본 논문들은 아래와 같습니다.
** Training의 기준은 (DM, Text Encoder)등을 포함한 Pretrained 모델을 학습했는지 입니다. 이외의 다른 네트워크를 학습하는 경우 Non-Training으로 분류했습니다.
- Non-Training-based : DiffLens, Balancing-act, Self-Disc,
** [DiffLens] Dissecting and Mitigating Diffusion Bias via Mechanistic Interpretability (CVPR'25)
** Balancing-act: Distribution-guided debiasing in diffusion models (CVPR’24) : H-Dist에 더해주기
** [Self-Disc, Self Discovering latent direction] Self-discovering interpretable diffusion latent directions for responsible text-to-image generation (CVPR’24): H-Dist에 더해주기 - Training-based : TIW,
** [TIW] Training unbiased diffusion models from biased dataset (ICLR'24)
이 중에 DiffLens와 TIW에 대해 살펴보겠습니다.
a. DiffLens
** Dissecting and Mitigating Diffusion Bias via Mechanistic Interpretability (CVPR'25)
기존의 DM은 gender, race, age에 있어서 skewed representation을 표현함으로서 biased content를 만드는 문제가 있다고 합니다.
이런 문제는 보통 학습 데이터에서 기원하는데, 학습 과정에서 증폭되기도 한다고 합니다.
먼저, 본 논문에서는 DM의 내부 neuron들이 집합적으로 biased concept을 생성하기 위한 핵심적인 역할을 하고 있다고 가정했습니다.
따라서 본 논문에서는 DM의 한 종류인 UNet 모델의 내부 동작을 살펴봄으로써 어느 부분이 bias generation을 하게 되는지 알아보고, DiffLens라는 기법을 소개합니다.
먼저, DM의 내부의 hidden states $\boldsymbol{h}=[h_1,h_2, \dots,h_n]\in\mathbb{R}^n$를 각 layer의 n개의 activation 값이라고 했을 때, 앞서 설명과 같이 이 hidden states들이 내부적으로 semantic정보를 얻어낸다고 가정했습니다.
** 이는 기존 LM에서도 시도되었던 내용이라고 합니다.
**** Knowledge neurons in pretrained transformers (ACL’22)
**** Locating and editing factual associations in gpt (NIPS’22)
** 또한 Asyrp이라는 논문에서 UNet의 bottleneck layer에 semantic space(H-Distribution)가 존재함을 보인 것을 근거로 합니다.
이런 neuron은 poly-semantic하지만 activation space내에서 sparse한 linear combination으로 표현 가능하기 때문에, 의미론적인 direction들을 구분화(disentangle) 하는 것으로 시작합니다.
** poly-semantic : 각 하나의 neuron은 여러개의 관계 없는 concept과 연관되어 있는 것
** Toy models of superposition (arxiv’22)
** Compositional explanations of neurons (NIPS’20)
** Zoom in: An introduction to circuits (Distill’20)
1. Disentangling Polysemantic Neurons
먼저 k-SAE(k-Sparse Autoencoder)를 활용해 hidden state를 아래그림과 같이 구성합니다.

위 k-SAE를 활용해 n차원의 latent feature space인 $\boldsymbol{H}^n=\{\boldsymbol{h}\}$를 sparse & high dimensional 한 m차원의 $\boldsymbol{S}^m=\{\boldsymbol{s}\},\, when\, m\gg n$로 mapping할 수 있습니다.
또한 이렇게 mapping된 $\boldsymbol{S}^m$의 feature, $\boldsymbol{s}$는 앞서와는 다르게 mono-semantic하게 됩니다.
이 때 위 Autoencoder에서 Mapping하는 과정($\Phi()$)과 다시 decoding하는 과정($\Phi^{-1}()$)은 아래와 같습니다.
** $k$ : mapping된 m개의 $\boldsymbol{s}$ 각각의 feature length
** $\boldsymbol{W}_{enc}\in\mathbb{R}^{m\times n}$ : encoding weight matrix
** $\boldsymbol{b}_{pre}\in\mathbb{R}^{n}$ : encoding/decoding weight bias
** $TopK(\cdot)$ : k 개의 가장 큰 feature를 선택하는 과정으로, 선택된 feature들을 “fired features”라고 부릅니다.
** $\boldsymbol{W}_{dec}\in\mathbb{R}^{n\times m}$ : decoding weight matrix
** $\hat{\boldsymbol{h}}\in\mathbb{R}^n$ : decoding된 reconstructed latent vector
$$\begin{aligned}
\boldsymbol{s}=[s_1,s_2,\dots,s_m]&=\Phi(\boldsymbol{h})&=&TopK(\boldsymbol{W}_{enc}(\boldsymbol{h}-\boldsymbol{b}_{pre}))\\
\hat{\boldsymbol{h}}&=\Phi^{-1}(\boldsymbol{s})&=&\boldsymbol{W}_{dec}\boldsymbol{s}+\boldsymbol{b}_{pre}
\end{aligned}$$
위는 아래와 같은 MSE를 reconstruction error로 활용해 학습하며, 기존의 latent를 reconstruction하는 형태로 학습됩니다.
$$\mathcal{L}(\boldsymbol{h})=\|\boldsymbol{h}-\hat{\boldsymbol{h}}\|^2_2$$
이제 이렇게 만든 sparse semantic space에서 영향있는 bias 컨셉 feature들을 찾아내기 위해 “Gradient-based Bias Attribution Method”를 제안합니다.
먼저, input $x$가 있을 때, 이에 해당하는 "disentangled feature인 $\boldsymbol{s}$가 social attribute class $y$일 확률"을 아래와 같이 구함으로써 bias level를 정량화합니다. 이를 bias measure이라고 부릅니다.
** 이때 social attribute class $y$는 “male”이나 “female”같은 gender bias 따위를 의미합니다.
** $F_{x}(\cdot;\psi)$ : $\psi$ 파라미터를 가진 light-weight classifier를 의미합니다. 여기 light-weight classifier는 Balancing act를 차용했습니다.
** Balancing act: Distribution-guided debiasing in diffusion models (CVPR’24)
$$\begin{aligned}
F_x&:\boldsymbol{S}^m\rightarrow \mathbb{R}\\
F_x(\boldsymbol{s})&=\mathrm{Pr}(y|\boldsymbol{s})\\
\end{aligned}$$
그 다음 위 식을 이용해 의미 있는 feature를 구하기 위해 아래와 같은 attribute score를 distangled feature의 각 $s_i$에 대해 구해냅니다.
** 파란 부분은 input image $x$에 대한 bias measure의 gradient 값을 의미합니다.
** $s’_i$는 baseline의 distangled feature의 요소를 의미하며, 0값을 사용하거나 특정한 input에 해당하는 값을 사용합니다.
$$S(s_i;x)=(s-s'_i)\cdot\int^1_{\alpha=0}{\color{blue}\frac{\partial F_x(\boldsymbol{s}'+\alpha(\boldsymbol{s}-\boldsymbol{s}'))}{\partial s_i}}\mathrm{d}\alpha$$
다음으로 N개의 생성된 샘플들 $\boldsymbol{x}_j\in X$에 대해 해당 semantic feature 요소 $s_i$를 아래와 같이 더해줍니다
$$S(s_i;X)=\sum^N_{j=1}S(s_i;X_j)$$
마지막으로 본 논문에서 제안하는 DiffLens는 결국 여기서 top $\tau$개의 feature $\boldsymbol{A}=\{i_1,\dots,i_\tau\}$를 선택해 “bias features”라고 부릅니다.
이들은 DM에서 bias contents를 다루는데 사용되는 가장 영향력있는 semantic feature이며, DM에 대해 딱 한번만 미리 실행되면 됩니다.
2. Intervening in Bias Features
이제 본격적으로 DM의 social bias를 덜기 위해 위에서 구한 bias features에 개입(intervening)하는 방법을 살펴보겠습니다.
단순히 해당 feature를 억압(suppress)/증폭(amplify)하는 방법이 모두 가능하지만, 다른 방법들과는 다르게 본 논문에서는 확인된(identified) “bias feature”만 개입하며 그 과정은 아래와 같습니다.
** $\beta$ : 억압(suppress)/증폭(amplify)하기 위한 파라미터
$$\boldsymbol{s}_i = {Intervene}(\boldsymbol{s}_i) =
\begin{cases}
\beta \boldsymbol{s}_i & \text{(Scaling)}, \\
\boldsymbol{s}_i + \beta & \text{(Adding)},
\end{cases}
\quad \forall i \in \boldsymbol{A},\ \beta \in \mathbb{R}$$
이는 생성과정에 진행되며, 그 과정은 아래 그림과 같습니다. 이를 통해 decision-making 과정을 정확히 이해하고 de-biasing을 효율적으로 가능합니다.

그럼 실험 결과를 보겠습니다. baseline으로는 기존의 guidance-based 방법들을 활용합니다.
** [Latent Editing] Diffusion models already have a semantic latent space (ICLR’23)
** [H-Distribution] Balancing act: Distribution-guided debiasing in diffusion models (CVPR’24)
아래 결과는 de-biasing이 social attributes(gender)에서 얼마나 balanced한 결과를 내는지에 대한 정량평가 결과입니다.

결과를 보면 DiffLens가 높은 bias mitigation을 보이면서도, generation quality를 유지했다고 합니다.
실제로 생성한 결과를 봐도, 다른 모델에 비해 well-balanced된 결과를 보입니다.

b. TIW(Time-dependent Importance reWeighting)
** Training unbiased diffusion models from biased dataset (ICLR'24)
데이터셋의 bias는 real world에서는 굉장히 많은 영향을 미치고 있습니다.
따라서 본 논문에서는 generative model을 de-biasing하는 학습 기법의 일종인 Importance Reweighting의 새로운 기법을 제안합니다.
기존의 Importance Reweighting는 기존에 학습된 모델에서 측정한 density ratio를 활용해 학습하는데,
이는 부정확하기 때문에 time-dependent discriminator를 활용해 biased distribution과 un-biased distribution 간의 time-dependent density ratio를 활용해 개선합니다.
** 여기서의 time은 diffusion time step을 의미합니다.
그럼 그 방법을 한번 살펴보겠습니다.
시작하기에 앞서 용어를 정의하기 위해 problem setup과정을 살펴보겠습니다.
- Observed Dataset : $D_{obs}=D_{bias}\cup D_{ref}$ : 보통 일반적으로 접근가능한 데이터셋
- Biased Dataset $D_{ref}$ : $p_{bias}$ 으로 추출해낸 샘플들
** biased data distribution $p_{bias}$ : unknown biased distribution로, biases가 있는 데이터 분포 - True Dataset $D_{ref}$ : Generative Modeling의 목표로, $p_{data}$으로 추출해낸 샘플들
** true data distribution $p_{data}$ : 원하는 데이터 분포
** 보통 $|D_{ref}|$는 상대적으로 $|D_{bias}|$에 비해 그 수가 적습니다.
1. Time-Dependent Importance Re-weighting
먼저, DRE(Density Ratio Estimation)는 두 분포 사이의 density ratio를 측정하는 방법으로, noise contrastive estimation 혹은 discriminative training 방법을 활용해 두개의 분포 사이의 likelihood(어떤 분포에서 온 샘플인지)를 알기 위해 활용하는 방법입니다.
이는 score-based 등 probabilistic ML에서 큰 장점을 제공하기도하고, 위 소개한 Importance Re-weighting 방법에도 활용됩니다.
근데, density-chasm라는 문제 때문에 estimation error가 생긴다고 합니다.
** Density-Chasm문제에 대해 궁금하시면 아래 더보기를 참조하세요
----------------------------------------------------------------
<Density-Chasm 문제>
** Telescoping density-ratio estimation (NIPS'20)
DRE(Density-ratio Estimation)는 보통 p 분포와 q분포를 구분하기 위해 NN classifier를 활용해 p/q 비율(Density-Ratio)을 측정하는 discriminative approach입니다.
즉, 각각의 개별적인 확률분포는 완벽히 추정하기 어렵기 때문에 그 상대적인 비율만 추정하는 방법이죠.
** p 분포 : 보통 우리가 관심 있는 target distribution, 즉 실제 데이터 분포
** q 분포 : 우리가 만들어낸 model distribution, 모델이 만들어낸 샘플의 분포
Density Ratio의 수식은 정확히는 아래와 같습니다. 즉, 특정 x에서 두 분포가 얼마나 서로 다른지를 나타낸 것이죠.
$$r(x)=\frac{p(x)}{q(x)}$$
하지만 이런 Density-ratio estimation을 활용하는 방법들은 Density-Chasm문제가 있다고 합니다.
직역하면 “깊은 밀도 골짜기”라는 뜻으로, 데이터가 충분하다가 갑자기 부족해지는 부분에서 모델이 낭떨어지로 떨어지는 문제라고 해석할 수 있습니다.
즉, p분포와 q 분포 중 갑자기 밀도 차이(chasm)가 크면, 상대적으로 classifier는 두 분포를 정확하게 구분할 수 있지만서도 Density Ratio 자체는 제대로 추정하지 못하는 현상입니다.
** 보통 위에서 얘기한 밀도차이가 큰 경우는, 고밀도 영역(dense region)과 저밀도 영역(sparse region)사이의 밀도차이 때문에 발생합니다.
1. Density-Chasm in Score-Based DM
DRE는 score-based 등 probabilistic ML 자체에서도 큰 장점을 제공므로, 이런 score-based DM자체에 DRE를 사용하면서 생기는 Density-Chasm에 대해 대입해보겠습니다.
상황은, 데이터 분포인 p 분포를 가진 데이터셋의 경우 특정한 manifold에 밀집되어있고 그 주변은 비어있거나 끊어져있습니다.
근데 score-based DM은 결국 아래식과 같이 데이터의 log-density gradient를 “추정”하는 역할을 하고 있습니다.
$$\nabla_xlog\,p(x)$$
이런 경우 데이터가 많은 곳에서는 문제가 없지만, 데이터가 sparse한 곳에서는 모델의 분포와 데이터의 분포에서 밀도차이가 크기 때문에 Density Ratio를 정확히 추정하지 못하게 됩니다.
따라서 모델이 제대로 학습하지 못하게되고 이렇게 학습된 모델이 생성한 q분포는 데이터가 적은 곳에서 학습이 불안하게 되는 현상이 나옵니다.

위와 같이 Score-Based DM에서 발생하는 Density-Chasm문제는 주로 아래와 같을때 발생합니다.
- 두 분포사이의 distance가 너무 클때
- 각 두 분포에서의 샘플 개수가 너무 작을 때
2. Density-Chasm in Importance Reweighting
이번엔 biased 데이터 $p_{bias}$를 활용해 학습하는 상황에서, 이를 개선하기 위해 사용하는 Importance Re-weighting기법을 활용하는데, 이때 DRE를 활용하는 경우에 대입해보겠습니다.
데이터의 bias를 덜기 위한 Importance Reweighting 기법에서는 아래식과 같은 density ratio $w_\phi(\boldsymbol{x}_0)$를 미리 학습하고, 이 값에 따라 de-biased 데이터 분포인 $p_{data}$에서 추출된 샘플에 대해 조금 더 높은 weight를 제공합니다.
** Fair generative modeling via weak supervision (ICML’20)
** 본 논문에서는 이를 IW-DSM(Importance Reweighted Denoising Score-Matching)이라고 부릅니다.
$$\begin{aligned}
\mathcal{L}_{DSM}&=\frac{1}{2}\int^T_0\mathbb{E}\left[{\color{red}w_{\phi^*}(\boldsymbol{x}_0)}\mathbb{E}_{p(\boldsymbol{x}_t|\boldsymbol{x}_0)}[\lambda(t)\|\boldsymbol{s}_\theta(\boldsymbol{x}_t,t)-\nabla log\,p(\boldsymbol{x}_t|\boldsymbol{x}_0)\|^2_2]\right]\\
w_\phi(\boldsymbol{x}_0)&\approx \frac{p_{data}(\boldsymbol{x}_0)}{p_{bias}(\boldsymbol{x}_0)}
\end{aligned}$$
이로써 학습할 모델인 $p_\theta$가 biased dataset $p_{bias}$를 활용해 true data distribution $p_{data}$로 converge할 수 있도록 해줍니다.
** diffusion time step과 무관하게 t=0에서의 density ratio만을 활용하므로 설명하고 있는 논문에서는 Time-Indendent Importance Reweighting이라고 부르기도 합니다.
하지만 역시나, 위와 같은 Importance Reweighting 방법에서도 $p_{bias}$와 $p_{data}$간의 밀도차이로 인해 Density-Chasm문제가 발생할 수도 있습니다.
특히 Importance Re-weighting에서 생기는 density chasm은 아래와 같은 원인이 크다고 합니다.
- real-world 데이터셋은 고차원일 때
- Reference로 활용되는 de-biased 데이터 분포인 $p_{data}=|D_{ref}|$의 개수가 굉장히 작을 때
----------------------------------------------------------------
따라서 이 문제를 다루기 위해 준비된 데이터 $p^t_{bias}(\boldsymbol{x}_t)$와 reference데이터 $p^t_{data}(\boldsymbol{x}_t)$ 간의 time-dependent density ratio를 활용하려고 합니다.
즉 time step에 따라 서로 다른 density ratio를 얻어내겠다는 뜻이며, 이를 활용하면 아래와 같은 장점이 있습니다.
- 1. t가 커질 때 forward process에서의 두 분포 사이의 perturbation이 가까워 질 수 있다.
- 2. 이런 perturbration은 각 분포에서 생기는 Monte Carlo error를 줄일 수 있습니다.
** Monte Carlo Error : 확률적 샘플링에 의해 계산된 추정치가 참값과 차이 나는 오차
먼저 time-dependent density ratio 수식은 아래와 같습니다.
** $d_\phi:\mathcal{X}\times [0,T]\rightarrow [0,1]$ : time-dependent discriminator로, $p^t_{bias}(\boldsymbol{x}_t)$에서 추출된 샘플로부터 $p^t_{data}(\boldsymbol{x}_t)$를 분리해내는 NN입니다.
$$w_{\boldsymbol{\phi}^*}^t(\boldsymbol{x}_t)
:= \frac{p_{{data}}^t(\boldsymbol{x}_t)}{p_{{bias}}^t(\boldsymbol{x}_t)}= \frac{d_{\boldsymbol{\phi}^*}(\boldsymbol{x}_t, t)}{1 - d_{\boldsymbol{\phi}^*}(\boldsymbol{x}_t, t)}$$
위에서의 $d_\phi$ 는 아래와 같은 T-BCE(Temporally-weighted Binary Cross-Entropy)를 활용해 최적화합니다.
** $\lambda’(t)$ : temporal weighting function입니다.
$$\mathcal{L}_{{T-BCE}}(\boldsymbol{\phi}; p_{{data}}, p_{{bias}})
:= \int_0^T \lambda'(t) \left[
\mathbb{E}_{p_{{data}}^t}(\boldsymbol{x}_t)\left[ -\log d_{\boldsymbol{\phi}}(\boldsymbol{x}_t, t) \right]
+ \mathbb{E}_{p_{{bias}}^t}(\boldsymbol{x}_t)\left[ -\log\left(1 - d_{\boldsymbol{\phi}}(\boldsymbol{x}_t, t)\right) \right]
\right] dt$$
아래 그림은 diffusion time interval인 $t\in[0,T=1]$에서 Density Ratio Estimation결과의 정확성을 의미합니다.

(c)와 (d)는 추정한 Ratio와 실제 Ratio를 비교한 것인데, t=0일 때 discriminator가 너무 과신(overconfident)하기 때문에 skewed된 결과를 보이지만 time step이 증가 할수록 이런 현상이 줄어든다고 합니다.
이는 (e)를 보아도 확인할 수 있는데, time step에 따른 정확도 MSE(Mean Sqaured Error)가 time step이 증가할수록 줄어듭니다.
하지만 빨간선을 보면 기존의 importance reweighting에서는 t=0에서의 true ratio만을 활용하므로 전체 time step으로 에러가 propagate됩니다.
2. TIW in Score Matching
그럼 이제 위와 같이 수정된 re-weighting을 score matching에 적용해보겠습니다.
먼저 marginal distibution을 기존의 re-weightning방법과 동일하게 아래와 같이 정의합니다.
** 기존의 식에서는 아래 파란 부분이 $\nabla log\,p(\boldsymbol{x}_t|\boldsymbol{x}_0)$와 같은 joint space를 활용한 식이 포함되어있었기 때문에 직관적이지는 않기 때문에 일단 정의를 먼저 해보겠습니다.
$$\begin{aligned}
\mathcal{L}_{{SM}}(\boldsymbol{\theta}; p_{{data}})
&= \frac{1}{2} \int_0^T \mathbb{E}_{p_{{bias}}^t}(\boldsymbol{x}_t)
\left[
{\color{red}w_{\boldsymbol{\phi}^*}^t(\boldsymbol{x}_t)}\ell_{{sm}}(\boldsymbol{\theta}, \boldsymbol{x}_t)
\right] dt\\
\ell_{{sm}}(\boldsymbol{\theta}, \boldsymbol{x}_t)
&:= \lambda(t) \left\| \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) - {\color{blue}\nabla \log p_{{data}}^t(\boldsymbol{x}_t)} \right\|_2^2
\end{aligned}$$
위 objective는 파란부분에 대한 문제는 아래 두가지와 같습니다.
- 1. 이전의 joint space에서 샘플링 하는 $\nabla log\,p(\boldsymbol{x}_t|\boldsymbol{x}_0)$가 아닌 $\boldsymbol{x}_t$에서 직접 샘플링을 하는 ${\color{blue}\nabla \log p_{{data}}^t(\boldsymbol{x}_t)}$이기 때문에 interactable합니다.
- 2. 우리가 직접적으로 활용할 데이터가 아닌 true 분포인 $p_{{data}}^t(\boldsymbol{x}_t)$ 분포가 score화 된 ${\color{blue}\nabla \log p_{{data}}^t(\boldsymbol{x}_t)}$를 활용한다면, 직접적으로 "실제 데이터"를 활용한 표현인 score-based matching 수식으로 바꾸기 쉽지 않습니다.
이를 해결하기 위해 아래와 같은 TIW-DSM(Time-Dependent Importance re-Weighted Denoising Score-Matching)이라는 objective function을 새로 보입니다. 위 파란색 부분이 아래와 같이 변형되었습니다.
** 첫번째 줄은 본 논문에서는 위 TIW-DSM objective function이 Score Matching Loss에 상수를 더한 형태인 것을 증명한 결과입니다.
$$\begin{aligned}
\mathcal{L}_{{TIW-DSM}}(\boldsymbol{\theta}; p_{{bias}}, w_{\boldsymbol{\phi}^*}^t(\cdot))
&= \mathcal{L}_{{SM}}(\boldsymbol{\theta}; p_{{data}}) + C\\
&:= \frac{1}{2} \int_0^T \mathbb{E}_{p_{{bias}}(\boldsymbol{x}_0)} \mathbb{E}_{p(\boldsymbol{x}_t \mid \boldsymbol{x}_0)}
\left[
\lambda(t) w_{\boldsymbol{\phi}^*}^t(\boldsymbol{x}_t)
\left\| \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)
- {\color{blue}(\nabla \log p(\boldsymbol{x}_t \mid \boldsymbol{x}_0)
+ \nabla \log w_{\boldsymbol{\phi}^*}^t(\boldsymbol{x}_t))}
\right\|_2^2
\right] dt\\
\nabla \log w_{\boldsymbol{\phi}^*}^t(\boldsymbol{x}_t)&= \nabla\log \frac{p_{{data}}^t(\boldsymbol{x}_t) }{p_{{bias}}^t(\boldsymbol{x}_t)}\\
&= \nabla \log p_{{data}}^t(\boldsymbol{x}_t) - \nabla \log p_{{bias}}^t(\boldsymbol{x}_t)
\end{aligned}$$
변형된 파란부분을 보면, 기존의 score matching term과 같은 ${\color{blue}\nabla log\,p(\boldsymbol{x}_t|\boldsymbol{x}_0)}$를 활용하고 ${\color{blue}\nabla \log w_{\boldsymbol{\phi}_*}^t(\boldsymbol{x}_t)}$가 추가된 형태입니다.
추가된 항은 본 논문에서 새로운 Score Correction Term이라고 부르는 L2 loss내의 regularization입니다.
이는 ${\nabla \log p_{{bias}}^t(\boldsymbol{x}_t)}$에서 출발해 ${\nabla \log p_{{data}}^t(\boldsymbol{x}_t)}$ 방향으로 model score를 이동시키는 역할을 합니다.
실제 score인 ${\nabla \log p_{{bias}}^t(\boldsymbol{x}_t)}$와 ${\nabla \log p_{{data}}^t(\boldsymbol{x}_t)}$, 그리고 보정하는 위 Score Correction Term에 대해 display한 결과는 아래 그림과 같고,
실제로 모델이 ${\nabla \log p_{{data}}^t(\boldsymbol{x}_t)}$의 방향으로 향하도록 수정하고 있는 것을 볼 수 있습니다.

또한 본 논문에서는 제안된 objective function이 true data distribution인 $p_{{data}}^t(\boldsymbol{x}_t)$를 활용한 score matching objective와 동일하다는 것을 증명해냈습니다.
이는 TIW-DSM objective function으로 학습한 모델이 optimal한 solution이 될 수 있다고 말합니다.
결과를 살펴보겠습니다.
Reference size를 개수를 기준으로한 $\frac{|D_{ref}|}{|D_{bias}|}$라고 할때, 아래는 Reference size에 따른 FID 결과와 그림, 그리고 학습 추이입니다.
** DSM(ref) : reference 데이터로만 학습
** DSM(obs) : reference + bias 데이터로 학습
** IW-DSM : 기존의 time-independent Importance re-Weighting 활용
** TIW-DSM : 본 논문의 time-dependent Importance re-Weighting활용

결과적으로 모든 경우에 reference size가 늘어날수록 성능이 좋아지며, 본 논문에서 제안한 TIW-DSM을 활용하는 경우 큰 margin으로 다른 경우보다 성능이 좋았다고 합니다.
또한 그림 (d)를 보면 다양한 샘플들을 un-biased하게 생성하는 것을 볼 수 있으며, 그림 (e)의 convergence curve를 보면 DSM & IW-DSM 등은 overfitting되는 경우가 있지만 TIW-DSM은 그렇지 않습니다.
3. Case B-b : Sampling & Case B-c : Condition Alignment
이번엔 biases가 DM에서 생성된 noise를 더하는 샘플링 과정에서 생기는 경우(CaseB-b)와 DM 네트워크 내의 conditioning과정에서 생기는 경우(CaseB-c)에, 어떻게 이 문제를 해결하려는 시도가 있었는지를 살펴보려고 합니다.

제가 찾아 본 논문들은 아래와 같습니다.
** Training의 기준은 (DM, Text Encoder)등을 포함한 Pretrained 모델을 학습했는지 입니다. 이외의 다른 네트워크를 학습하는 경우 Non-Training으로 분류했습니다.
- Non-Training-based : CADS, Rethinking Training for De-biasing, TIME, UCE, FairDiff,
** CADS: Unleashing The Diversity of Diffusion Models through Condition-Annealed Sampling(ICLR'24)
** Rethinking Training for De-biasing Text-to-Image Generation: Unlocking the Potential of Stable Diffusion (CVPR'25)
** [TIME] Editing implicit assumptions in text-to-image diffusion models (ICCV’23) : 기존 Weight를 closed-form solution으로 수정
** [UCE, Unified Concept Editing] Unified concept editing in diffusion models (WACV’24) : 기존 Weight를 closed-form solution으로 수정
** [FairDiff, FairDiffusion] Instructing text-to-image generation models on fairness (arxiv’23) : prompt에 더해주기 - Training-based : FT-Diff, UCE, De-stereotyping,
** [FT-Diff] Finetuning text-to-image diffusion models for fairness (ICLR’24)
** De-stereotyping text-to-image models through prompt tuning (ICML’ 23) : prompt embedding 학습해 더해주기
이중에 CADS, Rethinking Training for De-biasing, FT-Diff에 대해 살펴보겠습니다.
a. CADS(Condition-Annealed Sampling)
** CADS: Unleashing The Diversity of Diffusion Models through Condition-Annealed Sampling(ICLR'24)
Generative 모델링은 unstructured input (images)를 통해 정확하게 target data distribution의 특징을 파악하는 것이 목표입니다.
따라서 모델은 포괄적인 데이터 분포(comprehensive data distribution coverage)를 통해 다양한 결과를 만들어내고 high quality의 샘플들을 만들어내는 것이 목표일 것입니다.
이때, 우리가 지향하는 Diversity를 고정된 condition에 대해 initial random sample을 변화시키는 것만으로 다양한 output을 만들어내는 능력이라고 정의한다면, 아직까지는 DM을 diverse한 output을 만드는 것에 대해서는 관심이 적다고 합니다.
또한 conditional DM은 아직까지 실제로도 낮은 diversity의 결과를 내고 있는데, 이에 대한 원인이 아래와 같은 두 가지라고 지적합니다.
- 1. 많은 데이터셋(ex. SHHQ, 40k samples)에 대해 학습된 DM은 높은 퀄리티를 위해 높은 CFG를 요구하지만, 낮은 diversity를 보입니다.
- 2. 적은 데이터셋(ex. DeepFashion, 10k samples)에 대해 학습된 DM은 심지어 적은 CFG에서도 제한된 variation을 제공합니다.
하나의 가능한 솔루션은 많은 데이터셋에 대해 CFG를 줄이는 것이겠지만 이는 이미지의 퀄리티와 compromise합니다.
본 논문은 이런 문제들이 inference과정에서의 conditioning signal 역할로 인해 "특정 학습된 분포 내의 강한 mode"를 향해 converge하는 것이 원인이라고 주장합니다.
즉, 높은 CFG scale로 인해 모델이 conditioning signal과 생성된 샘플간의 1:1 매핑을 만들어내고, 집중도가 매우 높은 조건부 분포(highly peaked conditional distribution)에 집중되기 때문에 제한된 diversity를 제공하게 되는 것입니다.
따라서 본 논문에서는 높은 CFG scale에서 diversity를 높이면서도 샘플 quality의 minimal loss만 존재하는 방법을 제안합니다.
간단히 제안된 기술을 보자면, 학습 없이도 inference 과정에서 conditioning vector(signal)에 scheduled & monotonically decreasing Gaussian noise를 더해줌으로써, conditioning signal을 담금질(annealing)하는 효과를 주는 smoothing 방법입니다.
자세하게 살펴보겠습니다.
1. Conditioning Vector Annealing
먼저, time step t에서의 conditional probability $p_t(\boldsymbol{z}_t|\boldsymbol{y})$가 있을 때, 주어진 condition $\boldsymbol{y}$를 corrupt하는 과정은 아래 수식과 같습니다.
** s는 initial noise scale로, corrupt하기 위한 noise를 scaling하는 역할을 합니다. 본 논문에서는 0.025~0.25의 중간을 활용합니다.
** $\gamma(t)$는 annealing schedule로, 아래에서 소개하겠습니다.
$$\hat{\boldsymbol{y}} = \sqrt{\gamma(t)}\,\boldsymbol{y} + s\sqrt{1 - \gamma(t)}\,\boldsymbol{n},\,\,when\,\,\boldsymbol{n}\sim\mathcal{N}(0,\mathrm{I})$$
이 때 annealing schedule function $\gamma(t)$는 구간별 선형 함수(Piecewise Linear Function)로 주어집니다.
** user-defined threshold인 $\tau_1, \tau_2\in[0,1]$는 직접 설정해야합니다.
** $\tau_1$는 cut-off threshold로 본 논문에서는 0.2~0.9 사이 값을 사용합니다.
$$\gamma(t) =
\begin{cases}
1 & \text{if } 0 \leq t \leq \tau_1, \\
\frac{\tau_2 - t}{\tau_2 - \tau_1} & \text{if } \tau_1 < t < \tau_2, \\
0 & \text{if } \tau_2 \leq t \leq 1.
\end{cases}$$
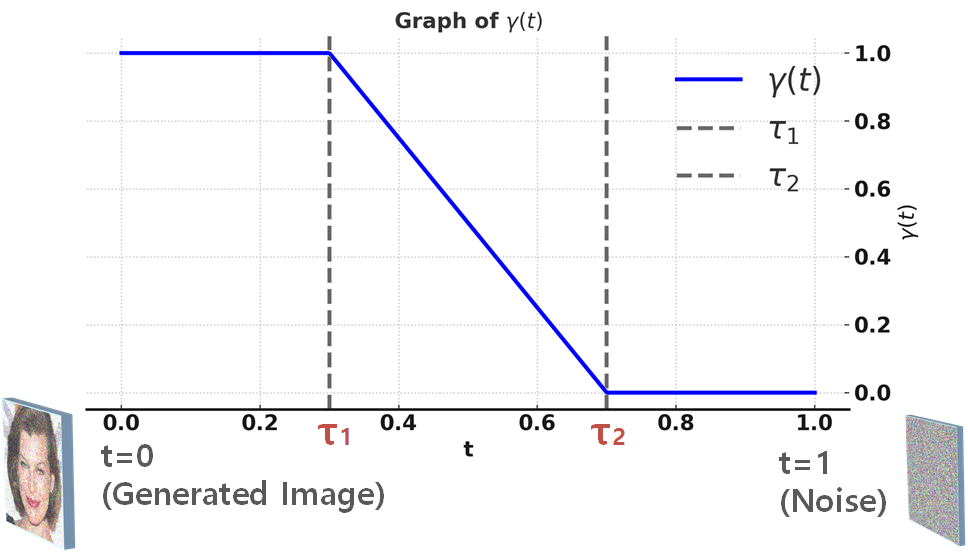
결과적으로 DM은 t=1에서 t=0으로 이동하면서 위 식을 통해 annealing이 가능해져, early step(t=1)에서는 $\hat{\boldsymbol{y}} \approx s\boldsymbol{n}$에 가까운 많은 corruption이 발생하고, late step(t=0)에서는 거의 corruption이 발생하지 않습니다.

수식적으로 한번 살펴보겠습니다.
결과적으로 위의 수식을 활용해 확률 분포 $p_t(\boldsymbol{z}_t|\boldsymbol{y})$를 $p_t(\boldsymbol{z}_t|\hat{\boldsymbol{y}})$로 변경가능하며, 아래와 같이 표현 가능합니다.
$$p_t(\boldsymbol{z}_t \mid \hat{\boldsymbol{y}})
= \frac{p_t(\hat{\boldsymbol{y}} \mid \boldsymbol{z}_t) \, p_t(\boldsymbol{z}_t)}{p_t(\hat{\boldsymbol{y}})}$$
그렇다면 결국 score는 $\nabla_{\boldsymbol{z}_t}log\,p_t(\boldsymbol{z}_t|\hat{\boldsymbol{y}})$와 같습니다.
이로 인해 early step에서는, 인풋으로 들어온 현재 noisy sample $\boldsymbol{z}_t$과 $\hat{\boldsymbol{y}}$가 독립적인 상태가 되어, 아래 식중에 파란부분이 0에 가까워져 unconditional한 생성인 $\nabla_{\boldsymbol{z}_t} \log p_t(\boldsymbol{z}_t)$와 같이 생성할 수 있게 됩니다.
$$\nabla_{\boldsymbol{z}_t}log\,p_t(\boldsymbol{z}_t|\hat{\boldsymbol{y}})=
{\color{blue}\nabla_{\boldsymbol{z}_t} \log p_t(\hat{\boldsymbol{y}} \mid \boldsymbol{z}_t)
}+ \nabla_{\boldsymbol{z}_t} \log p_t(\boldsymbol{z}_t)$$
이 말인 즉슨, early step에서는 unconditional하게 생성을 하다가, late step으로 갈수록 conditional한 term이 적용되는 것입니다.
이런 절차를 통해 early stage에서는 random space를 더욱 탐험하는 것이고, 높은 diversity와 high quality의 샘플을 만들어낼 수 있다고 합니다.
2. Rescaling To Prior
다음으로, 위와 같이 구현시 conditioning vector의 mean과 std(standard deviation)가 바뀌기 때문에, 위에서 나온 condition vector $\hat{\boldsymbol{y}}$를 rescaling해 prior의 mean과 std로 바꿔줍니다.
즉, 기존의 condition vector $\boldsymbol{y}$의 mean $\mu_{in}$, std $\sigma_{in}$이 있을때, 마지막 $\hat{\boldsymbol{y}}_{final}$은 아래와 같습니다.
** $\psi\in[0,1]$는 mixing factor로, 본 논문에서는 1을 사용합니다.
$$\begin{aligned}
\hat{\boldsymbol{y}}_{rescaled} &= \frac{\hat{\boldsymbol{y}} - \mathrm{mean}(\hat{\boldsymbol{y}})}{\mathrm{std}(\hat{\boldsymbol{y}})} \, \sigma_{in} + \mu_{in}, \\
\hat{\boldsymbol{y}}_{final} &= \psi \hat{\boldsymbol{y}}_{rescaled} + (1 - \psi)\hat{\boldsymbol{y}},
\end{aligned}$$
위와 같이 rescaling을 함으로써 noise scale s가 너무 클 경우에도 발산(divergence)하는 것을 방지합니다.
3. Dynamic CFG
추가적으로 본 논문에서는 또 다른 방법으로 Dynamic CFG를 소개합니다.
아래와 같은 CFG수식에서의 guidance scale인 $\omega$를 guidance weight인 $\hat{\omega}$로 바꿔줍니다.
$$\begin{aligned}
\tilde{\epsilon}_\theta(\boldsymbol{z},\boldsymbol{c})&=\omega\cdot\epsilon_\theta(\boldsymbol{z},\boldsymbol{c})+(1-\omega)\cdot\epsilon_\theta(\boldsymbol{z})\\
&=\epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}_{null})+\omega \cdot ( \epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}) - \epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}_{null}))\\
&\rightarrow\epsilon_\theta(\boldsymbol{z}, {\boldsymbol{c}_{null}})+{\color{red}\hat{\omega}} \cdot ( \epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}) - \epsilon_\theta(\boldsymbol{z}, \boldsymbol{c}_{null}) )
\end{aligned}$$
이때 guidance weight는 앞에서 정의한 schedule function $\gamma(t)$를 활용하기 때문에, early step(t=1)에서는 0이 적용되고, late step(t=0)에서는 1이 적용됩니다.
$$\hat{w}_{\mathrm{CFG}} = \gamma(t) w_{\mathrm{CFG}}$$
즉, 앞에서 정의했던 것과 같이 early step에서는 unconditional score에 의존하며, late step로 갈수록 conditional score에 의존하도록 하는 것입니다. 실제 본 논문의 수식은 아래와 같습니다.
$$\hat{D}_{CFG}(\boldsymbol{z}_t, t, \boldsymbol{y}) = D(\boldsymbol{z}_t, t, \hat{\boldsymbol{y}}_{null}) + w_{CFG} \cdot \left( D(\boldsymbol{z}_t, t, \hat{\boldsymbol{y}}) - D(\boldsymbol{z}_t, t, \hat{\boldsymbol{y}}_{null}) \right)$$

실험 결과를 살펴보겠습니다.
본 실험에서 진행한 4개의 conditional generation tasks에 따른 실험 셋팅을 간단하게 보면 아래와 같습니다.
- Class-conditional generation
- Model : (pretrained) DiT-XL/2
- Condition : DiT-XL/2 : class embeddings (ImageNet 기반)
- Pose-to-image generation
- Model : (scratch) Diffusion Model
- dataset : DeepFashion, SHHQ
- Condition : directly add noise to the pose image
- Identity-conditioned face generation
- Model : (pretrained) ID3PM
- Condition : face-ID embeddings
- Text-to-Image generation
- Model : (pretrained) Stable Diffusion
- Condition : text embeddings
아래는 높은 guidance scale을 사용할 때의 CADS와 DDPM을 비교한 결과입니다.
CADS가 diversity를 명백하게 증가시켜 모든 tasks에서 이는 quality를 의미하는 Precision을 유지하면서도, diversity를 의미하는 FID, Recall, Similarity Scores를 향상시키는 것을 볼 수 있습니다.

Ablation Study는 아래와 같습니다.
- 1. noise scale $s$ : corrupt하기 위한 noise를 scaling하는 역할
- 최소 noise인 s=0.025일 때 diversity를 줄이며, 과한 noise인 s=0.25일 때 quality를 줄입니다.
- 2. cut-off threshold $\tau_1$ : late step(t=0)일 때 noise를 완전히 없애는 시점
- 적은 noise인 $\tau_1$=0.9일 때 diversity를 줄이며, 과한 noise인 $\tau_1$=0.2일 때 quality를 줄입니다.
- 3. cut-off threshold $\tau_2$ : early step(t=1)일 때 완전한 noise를 줄이기 시작하는 시점
- CFG가 높을 때 ($\omega_{CFG}$=5) : 더 많은 noise를 주기 위해 $\tau_2$를 줄이면 diversity가 증가합니다.
- CFG가 낮을 때 ($\omega_{CFG}$=2.5) : 더 많은 noise를 주기 위해 $\tau_2$를 줄이면 악효과입니다.
- CFG가 높을 때 ($\omega_{CFG}$=5) : 더 많은 noise를 주기 위해 $\tau_2$를 줄이면 diversity가 증가합니다.
- 4. rescaling $\psi$ : noise scale s가 크더라도 regularizer로서의 역할을 잘해내는지
- 많은 regularization인 $\psi$ =1.0일 때는 diversity를 줄이며, 적은 regularization인 $\psi$ =0.0일 때는 quality를 줄입니다.
- 본 논문에서는 $\psi$ =1.0을 추천합니다.
- 5. functional form of annealing schedule function $\gamma(t)$ : polynomial function과 비교했을 때의 결과
- polynomial의 degree가 증가할수록 크게는 바뀌지 않았지만 linear function일 때 제일 좋은 성능을 보였습니다.

- 6. 더해지는 noise $\boldsymbol{n}$의 distribution비교 : Uniform Noise / Gaussian Noise / Laplace Noise / Gamma noise 간의 비교
- 더해지는 noise의 종류에 크게 민감하지 않았지만, 표준편차는 noise scale $s$에 영향을 주기 때문에 영향이 컸습니다.
마지막으로 기존 DDPM sampler와 CADS, 그리고 Dynamic CFG를 비교한 결과, class-conditional model에서는 CADS가 Dynamic CFG보다 더 좋은 diversity를 보였습니다.

b. Rethinking Training for De-biasing
** Rethinking Training for De-biasing Text-to-Image Generation: Unlocking the Potential of Stable Diffusion (CVPR'25)
본 논문에서는 먼저 minority region이라는 존재에 대해 주장하며, 이를 확인하기 위해 Mode Test라는 것을 진행합니다.
그럼 하나씩 살펴보겠습니다.
설명에 앞서 condition은 아래와 같은 조건 사이의 biases를 조사하며, 이에 대한 결과는 CLIP zero-shot classifier를 이용해 측정해냅니다.
- 1. 4개의 직업 : doctor, CEO, nurse, teacher
- 2. Social Biases
- Gender : male, female
- Racial : white, black, asian, indian, latino
이 때, "자주 나타나는지"에 대한 기준으로 attribute를 아래와 같이 나누어 정의합니다.
- Majority Attribute : 생성된 이미지에서 자주 출현하는 이미지 attribute
- Minority Attribute : 생성된 이미지에서 그 반대 케이스 attribute
- Neutral Attribute : 중립적인 이미지를 생성해야하는 attribute
1. Mode Test
Mode Test의 단계는 아래와 같이 진행합니다.
기존에는 몇백개 & 몇천개의 제한된 이미지를 생성해 minority 비율을 얻어냈다면, 이 방법은 sparse하거나 극소의(minuscule)한 minority region을 얻어낼 수 있다고 합니다.
- Step1. 먼저 minority attribute와 함께 이미지를 생성해냅니다.
ex) A photo of a female CEO - Step2. 해당 이미지를 initial noise space로 다시 forward합니다.
** SDEdit의 forward process를 활용했다고 합니다. - Step3. neutral attribute의 prompt를 활용해 다시 생성합니다.
ex) A photo of a CEO
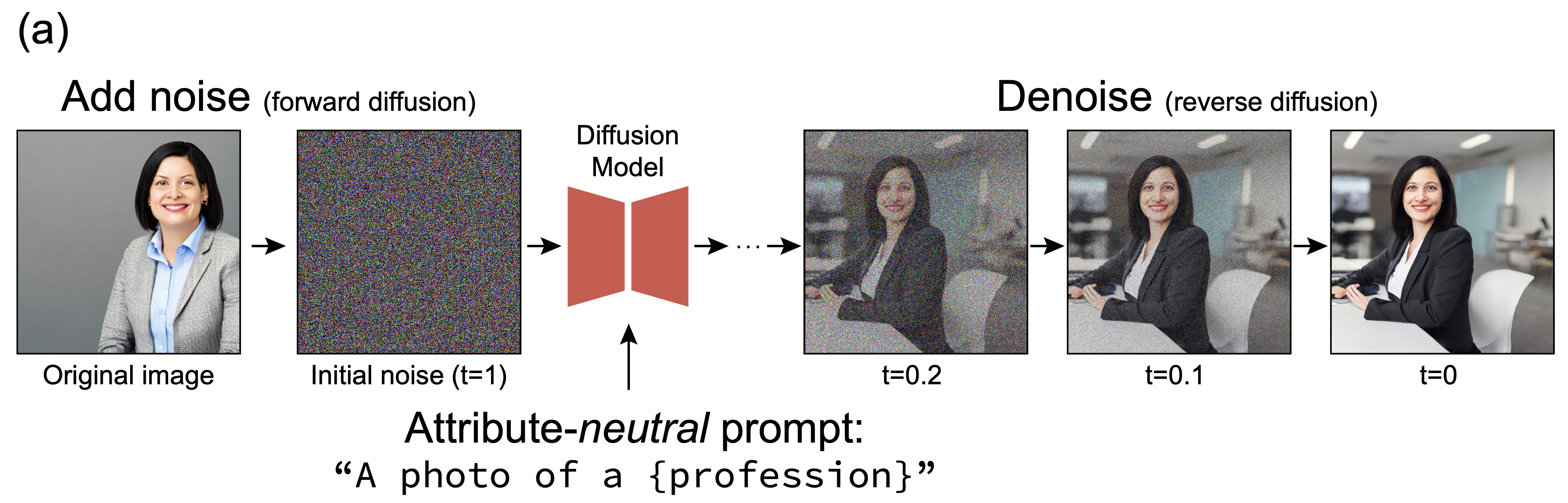
Step2에서 더해지는 noise는 표준 정규 분포(Standard Gaussian Distribution)이기 때문에 Step2의 결과인 Step3의 initial noise는 Step1의 initial noise와 가까운 곳에 위치할 것입니다.
그럼에도 불구하고 Step3의 결과에서 minor attribute가 재등장한다면, "더해지는 noise가 무작위 분포(randomly scattered)되지 않고 특정 위치에 몰려있다"는 것을 의미합니다.
minor가 다시 나타나는 비율을 “Minor Attribute Ratio”이라고 했을 때, 아래 그림은 minor attribute ratio의 결과를 나타냅니다.
이 결과가 높다면 이 글에서 정의한 minority region이 확실히 존재한다는 것을 의미합니다.
** 본 논문에서는 이것이 initial noise가 clustered되어 있다 표현했지만, 잘못 이해 했을 수도 있지만 필자는 added noise가 clustered된 것이지, initial noise가 clustered된 것을 증명하는 방법은 아닌 것 같습니다.

또한 본 논문에서는 early steps(t=1)에서는 minor attribute prompt를 적용하고, late steps(t=0)에서는 neutral attribute prompt를 적용하는 방법을 실험해봅니다.
아래 그림은 mode test가 아닌 일반적인 생성을 했을 때, 위와 같은 방법을 활용한 minor attribute prompt의 비율에 따른 minor attribute ratio를 나타냅니다.

결과를 보면, minor attribute가 거의 사용되지 않은(비율 0%) 때에는 biases가 꽤 강하며, minor attribute가 모두 사용된(비율 100%) 때에는 모두 minor attribute가 생성된 것을 확인할 수 있었습니다.
본 논문에서는 이 결과를 통해 early steps에서 guidance를 제공하는 것이 biases를 어느정도 해결할 수 있다고 말합니다.
** 이는 CADS가 late step에서만 guidance를 제공하는 것과는 반대의 의견이네요.
2. Text Condition Perturbation
이를 기반으로 text condition을 perturbation하는 방법을 제안합니다. 이때 아래와 같은 두개의 목표를 가지고 접근합니다.
- Efficiency : 학습 없이 inference과정에서 개선이 가능
- Versatility : biases를 필요에 의해서만 조정가능하며, general generation을 저해하지 않도록
이에 따라 본 논문에서 제안하는 방법은 text condition에 addition & subtraction을 통해 conceptual direction을 제공하겠다는 것입니다.
본 논문에서 특정 text attribute k의 attribute embedding direction은 아래와 같습니다.
** $\phi()$는 text encoder의 encoding function
** $’'\cdot''$는 empty text를 의미
$$\boldsymbol{a}_k=\vec{k}=\phi(k)-\phi(''\cdot'')$$
그다음 기존의 text condition embedding인 $\boldsymbol{c}$에 위의 vector를 적용하고 새로운 text condition을 얻어냅니다.
$$\hat{\boldsymbol{c}}=\boldsymbol{c}+\boldsymbol{a}_k$$
또한 위와 같은 변형 방법 전 input의 semantic integrity를 유지하지 위해, 모든 $\boldsymbol{c}$에 $\boldsymbol{a}_k$를 더하는 것이 아니고, 아래 그림과 같이 [EOS] 토큰 이후에 있는 토큰에만 attribute embedding direction를 더해줍니다.

결과적으로 실제 구현에 포함된 masking $\boldsymbol{m}$ 등을 포함한 수식은 같습니다.
$$\hat{\boldsymbol{c}}=\boldsymbol{c}+\boldsymbol{m}\odot\boldsymbol{a}_k\,\, (where\,m_i=1\, when\, i\geq[EOS])$$
또한 이런 target attribute로 바꿔주는 과정에 아래와 같이 추가적인 조건을 제공합니다.
- early steps인 $\tau$ step 이전에만 적용
- 기존 condition embed인 $\boldsymbol{c}$와 $\hat{\boldsymbol{c}}$를 번갈아가면서 진행합니다.
실험 결과를 살펴보겠습니다. 실험은 아래와 같은 condition들을 활용해 테스트했습니다.
- 1. 8개의 직업
- Male-dominated(CEO, doctor, pilot, technician)
- Female-dominated(fashion designer, librarian, teacher, nurse)
- Prompt example : A photo of a/an profession
- 2. Social Biases : Gender, Race
먼저 각각의 profession에 대해서 직접적으로 Gender를 명시하면서 300개의 이미지를 생성했을 때, condition에 따라 잘 생성되었는지를 확인하는 Target Attribute Ratio결과입니다.
본 논문에서 제안한 방법을 활용했을 때, 기존의 target attribute를 잘 명시할 수 있었다고 합니다.

다음으로 아래는 General한 생성결과의 퀄리티를 확인하기 위한 CLIP과 CMMD score입니다.
본 논문에서 제안한 방법은 효과가 있었다고 합니다.

마지막으로 본 논문에서 제안한 방법에 대한 중립적인 생성을 했을 때 diversity를 조사한 결과입니다.
아래 표는 "target ratio인 0.5와의 차이"의 평균값을 나타냅니다.
Generalizability가 SD에 비해 좋아졌다고 합니다.

c. FT-Diff
** [FT-Diff] Finetuning text-to-image diffusion models for fairness (ICLR’24)
Text-To-Image DM에서는 직업적인, 인종적인 등의 biases들이 존재하는데, 기존의 논문들은 넓은 범위의 prompt에 적응하는 기법을 제안하지만 생성되는 이미지를 컨트롤하는 작업은 많지 않다고 합니다.
본 논문에서는 이 fairness는 "생성한 이미지들의 attribute 분포의 user-defined target 분포와의 alignment"가 문제라고 가정하고 새로운 학습 방법을 제안합니다.
그럼 방법을 하나씩 살펴보겠습니다.
1. Losses
본 논문에서 제안하는 최종 Loss는 아래와 같습니다. 이중에 아래 파란색 부분에 대해 살펴보겠습니다.
$$\mathcal{L}={\color{blue}\mathcal{L}_{align}}+\lambda_{img}{\color{blue}\mathcal{L}_{img}}+\lambda_{face}\mathcal{L}_{face}$$
▶ 1-a. DAL Loss
먼저 ${\color{blue}\mathcal{L}_{align}}$는 DAL(Distributional Alignment Loss)로, 본 논문에서 제안한 Loss입니다.
먼저 상황을 가정해보겠습니다.
K개의 classes를 가진 categorical attribute를 통해 생성되는 이미지를 컨트롤 하고 싶을 때, 이들의 target distribution은 $D$입니다.
** 각 class는 K-length의 one-hot vector를 가지고, $D$는 discrete한 벡터 형태를 가집니다.
이제 생성 분포를 의미하는 생성한 샘플들을 준비합니다.
- $\mathcal{I}=\{\boldsymbol{x}^{(i)}\}_{i\in[N]}$ : finetuned DM으로 몇가지 prompt P에 대한 이미지들을 생성합니다
- $\boldsymbol{p}^{(i)}=[p_1^{(i)},\dots, p_K^{(i)}]=h(\boldsymbol{x}^{(i)})$: 모든 생성된 이미지 $\boldsymbol{x}^{(i)}$에 대해 classifer $h(\cdot)$을 통과한 class probability vector를 구해냅니다.
** $p^{(i)}_k$는 i번째 이미지가 k class에 해당할 estimated probability입니다. - $\{\boldsymbol{p}^{(i)}\}_{i\in[N]}$ : 결과적으로 준비된 생성 분포를 의미하는 생성한 샘플들입니다.
다음으로 target distribution $D$을 가진 벡터를 생성한 샘플만큼 준비합니다.
- $\boldsymbol{u}^{(i)}=[u_1^{(i)},\dots, u_K^{(i)}]$ : K classes 길이를 가진 분포를 의미하는 벡터 하나 준비합니다. 이는 클래스 하나를 의미하는 one-hot vector 벡터일 것입니다.
- $\{\boldsymbol{u}^{(i)}\}_{i\in[N]}$ : 준비된 샘플들의 개수만큼 target distribution $D$을 고려해 준비합니다.
** 이 때 선정되는 샘플들은 target distribution $D$에 의해 i.i.d.하게 되도록 샘플링 된 샘플들입니다.
** i.i.d.(independent and identically distributed) : 확률 변수나 데이터 포인트들이 “서로 독립적”이며 “동일한 확률 분포”를 따른다는 가정
이후에 위 두가지를 활용해 아래와 같은 OT로 그 차이를 구할 수 있습니다.
** OT(Optimal Transport) : 모델의 예측 분포를 true one-hot target 분포로 "최소 비용으로" 옮기는 최적 매칭 $\sigma^* $를 계산하는 방법으로, 단순한 cross-entropy loss 대신 상세한 정보까지 고려하는 방법을 사용하는 것 같습니다.
** $ \mathcal{S}_N$은 N의 샘플 사이의 모든 permutations(순열)을 의미합니다. 즉 i번째 $\boldsymbol{p}^{(i)}$는 i번째 $\boldsymbol{u}^{(i)}$와 매핑되는 것이 아니라, $\sigma_i\in[N]$를 통해 매칭 됩니다.
** 즉, $\boldsymbol{u}^{(\sigma_i)}$는 $\boldsymbol{p}^{(i)}$와 매핑될 $\{\boldsymbol{u}^{(i)}\}_{i\in[N]}$ 중 하나일 확률을 의미합니다.
$$\sigma^* = \arg\min_{\sigma \in \mathcal{S}_N} \sum_{i=1}^{N} \left| \mathbf{p}^{(i)} - \mathbf{u}^{(\sigma_i)} \right|_2$$
이 때 아래식처럼, 위 $\mathbf{u}^{(\sigma_i)}$에 대한 기대값 $\boldsymbol{q}^{(i)}$은, i 번째 생성된 이미지 $\boldsymbol{x}^{(i)}$가 “target distribution $D$를 따를 경우에!” 각 클래스에 속할 확률을 나타내는 K-dimensional probability vector입니다.
$$\mathbf{q}^{(i)} = \mathbb{E}_{u^{(1)}, \ldots, u^{(N)} \sim \mathcal{D}} \left[ \mathbf{u}^{(\sigma_i^*)} \right], \quad \forall i \in [N]$$
그래서 위처럼 “target distribution $D$를 따를 경우에!”, i 번째 생성된 이미지 $\boldsymbol{x}^{(i)}$가 학습해야할 class인 $y^{(i)}$와 그 class의 confidence인 $c^{(i)}$는 아래와 같습니다.
$$\begin{aligned}
y^{(i)}&=arg\,max(\boldsymbol{q}^{(i)})\in[K]&\,\,when \forall i\in[N]\\
c^{(i)}&=max(\boldsymbol{q}^{(i)})\in[K]&\,\,when \forall i\in[N]\\
\end{aligned}$$
이제 원래 대로 돌아와서, 우리가 사용하고 싶은 DAL(Distributional Alignment Loss)는 아래식과 같이 i 번째 생성된 이미지에 대해 $y^{(i)}$와의 cross-entropy loss입니다.
** $C$는 confidence threshold이고, $\boldsymbol{1}$는 indicator function(조건이 참이면 1, 아니면 0)입니다.
$$\mathcal{L}_{{align}} = \frac{1}{N} \sum_{i=1}^{N} \boldsymbol{1}\left[ c^{(i)} \geq C \right] {\color{red}\mathcal{L}_{\text{CE}}\left( h\left( \mathbf{x}^{(i)} \right), y^{(i)} \right)}$$
▶ 1-b. 나머지 Loss
전체 loss를 다시 보면 아래와 같습니다.
$$\mathcal{L}={\color{blue}\mathcal{L}_{align}}+\lambda_{img}{\color{blue}\mathcal{L}_{img}}+\lambda_{face}\mathcal{L}_{face}$$
${\color{blue}\mathcal{L}_{img}}$는 Image Semantics Preserving Loss로, frozen 모델로 생성한 결과 $\mathcal{I}'=\{\boldsymbol{o}^{(i)}\}_{i\in[N]}$가 있을 때, 기존의 CLIP과 DINO의 결과가 비슷하도록 image dissimilarity에 대한 패널티를 제공합니다.
** frozen모델로 생성한 결과는 같은 initial noise를 가지고 있어야합니다.
** CLIP은 text supervision으로 학습되며, DINO는 image self-supervision으로 학습됩니다.
** CLIP은 실제 laion/CLIP-ViT-H-14-laion2B-s32B-b79K, DINO는 dinov2-vitb14를 활용합니다.
$$\mathcal{L}_{\text{img}} = \frac{1}{N} \sum_{i=1}^{N} \left[
\left(1 - \cos\left( \text{CLIP}\left( \boldsymbol{x}^{(i)} \right), \text{CLIP}\left( \mathbf{o}^{(i)} \right) \right) \right)
+ \left(1 - \cos\left( \text{DINO}\left( \boldsymbol{x}^{(i)} \right), \text{DINO}\left( \mathbf{o}^{(i)} \right) \right) \right)
\right]$$
마지막으로 ${\mathcal{L}_{face}}$ 는 Face Realism Preserving Loss로, 본 논문에서 face-centric한 attribute에 집중했으므로, 생성된 샘플 $\boldsymbol{x}^{(i)}$ 얼굴과 외부 실제 얼굴 데이터셋 $D_F$의 dissimilarity에 대한 패널티를 제공합니다.
** face detector $d_{face}$과 face embedding model $emb()$를 활용해 비교합니다.
** face-centric attribute : gender, race, age
$$\mathcal{L}_{{face}} = \frac{1}{N} \left( 1 - \min_{F \in \mathcal{D}_F} \cos\left({emb}\left( d_{{face}}( \boldsymbol{x}^{(i)} ) \right), {emb}(F) \right) \right)$$
2. Adjusted DFT(Direct Fine Tuning)
본 논문에서는 모든 time step에 대해 noise prediction loss를 학습하는 기존 Diffusion Fine-tuning 방법과 다르게, DFT(Direct Fine Tuning)이라는 기법을 사용합니다.
이는 이전과 다르게 생성된 이미지에 대한 직접적인 Loss $\mathcal{L}(\boldsymbol{x}_0)$만 활용하는 것입니다.
**finetuning 상황에서는, 기존 학습 처럼 noise prediction이 잘되는 것보다는 원하는 목적으로 변형하거나 MSE loss외의 다양한 loss를 활용할 수 있기 때문에 사용하는 것 같습니다.
** Directly fine-tuning diffusion models on differentiable rewards (arxiv’23)
이때 LDM에서는 prompt P와 초기 노이즈 $\boldsymbol{z}_T$가 있을 때 아래 식을 활용해 $\boldsymbol{x}_0$를 생성합니다.
$$\boldsymbol{x}_0=f_{Dec}(\boldsymbol{z}_0)$$
먼저 본 논문에서는 naive DFT의 gradient를 적용해보았는데, Loss인 $\mathcal{L}(\boldsymbol{x}_0)$를 학습과정에 대한 변화를 보니 아래 그림과 같이 학습 iteration동안 감소가 되지 않았습니다.

그래서 해당 gradient를 아래와 같이 분리해보았습니다.
$$\begin{aligned}
\frac{\mathrm{d}\mathcal{L}(\boldsymbol{x}_0)}{\mathrm{d}\boldsymbol{\theta}}&=\frac{\mathrm{d}\mathcal{L}(\boldsymbol{x}_0)}{\mathrm{d}\boldsymbol{x}_0}\frac{\boldsymbol{x}_0}{\boldsymbol{z}_0}\frac{\mathrm{d}\boldsymbol{z}_0}{\mathrm{d}\boldsymbol{\theta}}\\
\frac{\mathrm{d}\boldsymbol{z}_0}{\mathrm{d}\boldsymbol{\theta}}&=- \underbrace{ \frac{1}{\sqrt{\bar{\alpha}_1}} \frac{\beta_1}{\sqrt{1 - \bar{\alpha}_1}} }_{\color{red}A_1}
\underbrace{ \mathbf{I} }_{\color{blue}B_1}
\frac{\partial \boldsymbol{\epsilon}^{(1)}}{\partial \boldsymbol{\theta}}
- \sum_{t=2}^{T} \left(
\underbrace{ \frac{1}{\sqrt{\bar{\alpha}_t}} \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} }_{\color{red}A_t}
\underbrace{ \left( \prod_{s=1}^{t-1} \left( 1 - \frac{\beta_s}{\sqrt{1 - \bar{\alpha}_s}} \frac{\partial \boldsymbol{\epsilon}^{(s)}}{\partial z_s} \right) \right) }_{\color{blue}B_t}
\frac{\partial \boldsymbol{\epsilon}^{(t)}}{\partial \boldsymbol{\theta}}
\right)
\end{aligned}$$
위 식을 보니, T step동안 recurrent evaluation을 위해 UNet을 활용한 reverse diffusion process를 여러번 진행하는데, 위의 exponentially 커지는 ${\color{blue}B_t}$ factor를 만들게 됩니다.
이 factor는 아래와 같은 두가지 문제를 발생합니다.
- 문제1. t가 T=1000에 가까울 수록(초기noise에 가까울 수록) $\frac{\mathrm{d}\boldsymbol{z}_0}{\mathrm{d}\boldsymbol{\theta}}$가 component ${\color{red}A_t}{\color{blue}B_t}\frac{\partial \boldsymbol{\epsilon}^{(t)}}{\partial \boldsymbol{\theta}}$에 의해 지배됩니다.
- 문제2. ${\color{blue}B_t}$는 모든 $\{\frac{\partial \boldsymbol{\epsilon}^{(s)}}{\partial \boldsymbol{z}_s}\}_{s\leq t-1}$사이의 products를 포함하게 되는데, 이로 인해 서로 다른 시점(t)들의 gradient들이 얽히면서, variance(분산)이 엄청 커져버립니다.
따라서 본 논문에서는 ${\color{red}A_t=1},\,{\color{blue}B_t=\mathbf{I}}$를 통한 adjusted DFT를 소개합니다. 위에서 본 gradient는 아래와 같이 adjusted gradient로 변화됩니다.
$$(\frac{\mathrm{d}\boldsymbol{z}_0}{\mathrm{d}\boldsymbol{\theta}})_{adjusted}=-\sum^T_{t=1}\frac{\partial \boldsymbol{\epsilon}^{(t)}}{\boldsymbol{\theta}}$$
위와 같이 변형되면, time step t에 대해 uncoupled 된 gradient를 활용할 수 있으며(${\color{blue}B_t}$), UNet의 결과를 standardize할 수 있다고(${\color{red}A_t}$) 합니다.
위에서 보았던 아래의 그림을 다시 보면, adjusted gradients가 적절하게 적용될 수 있음을 알 수 있습니다.
위와 같은 adjusted DFT를 그림으로 보면 아래와 같이, 기존에 하나의 gradient를 계산하기 위해 모든 gradient path가 엮어있는 것과 달리, 현재는 다른 time step과의 coupling 없이 연산 가능합니다.
** 회색은 Sampling Process를 의미합니다
** 빨간색은 모델 파라미터 $\theta$에 대한 Gradient Computation을 의미합니다.
** $\boldsymbol{z}_t$는 해당 step에서의 noisy image를 의미합니다.
** $\boldsymbol{\epsilon}^{(t)}$는 해당 step에서의 noise prediction을 의미합니다.
** $D_i$는 direct gradient path를 의미합니다.
** $I_i$는 indirect gradient path를 의미합니다.

결과는 간단하게 보겠습니다.
아래 결과를 보면, 가장 낮은 bias를 보이면서도, text prompt와의 높은 alignment를 보입니다.
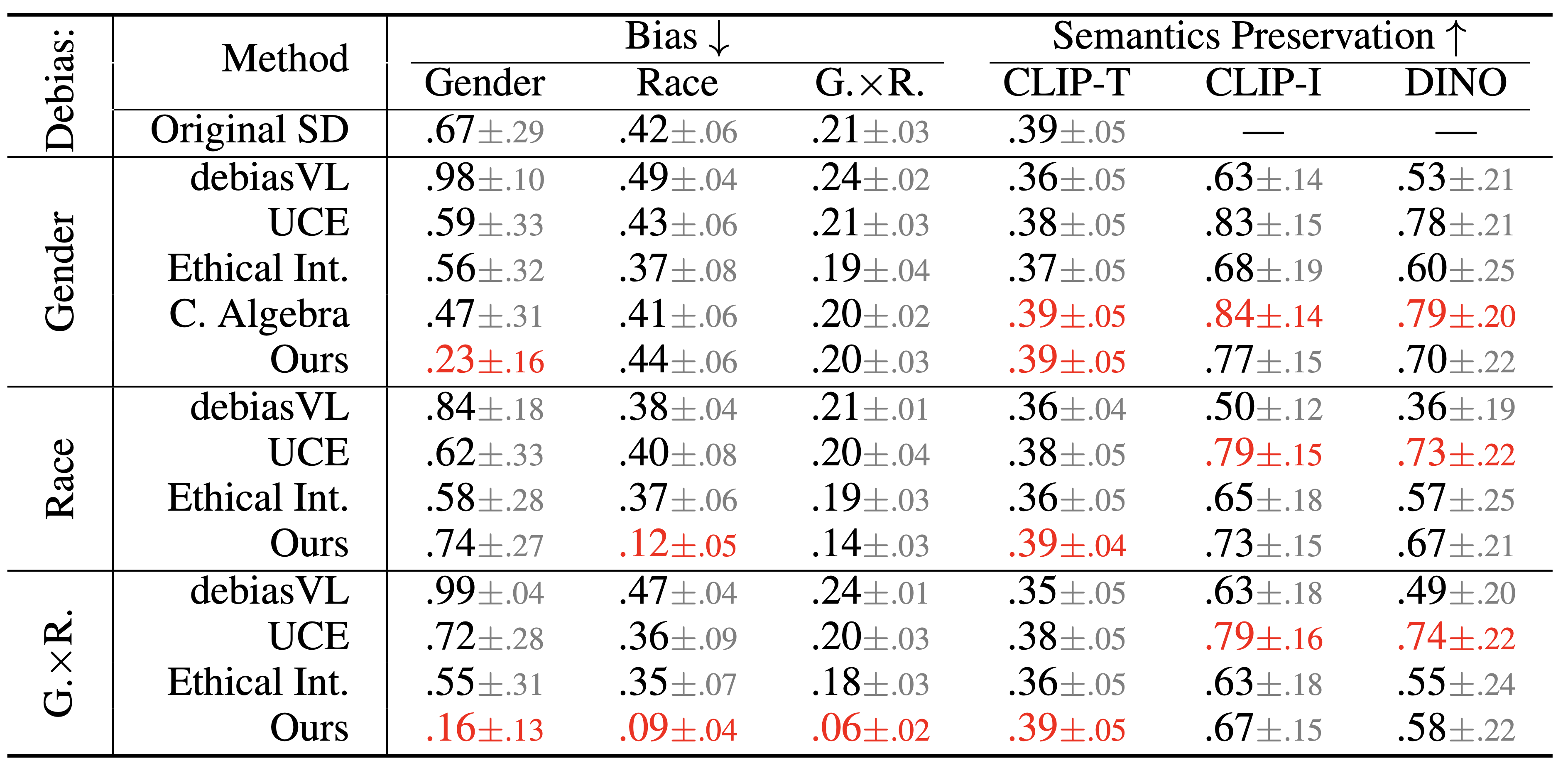
https://github.com/huggingface/diffusers/issues/5882
'소개글 > 에세이' 카테고리의 다른 글
| [Generative] Diffusion Model에서의 Multi-modality에 대한 생각 (0) | 2025.07.30 |
|---|---|
| [PyTorch] num_workers 최적화에 대한 생각 (0) | 2025.03.19 |
| [Generative] Diffusion-based Inversion과 Personalization에 대한 생각 (2) | 2024.04.19 |
| [Spec] 재능, 강점, 그리고 보완 (1) | 2023.10.20 |