
2025. 1. 2. 21:14ㆍDevelopers 공간 [Basic]/Software Basic
모델을 구축하다 보면, 네트워크의 부분적 구조마다 Loss를 다르게 적용하고 싶은 경우가 생깁니다.
이번 글에서는 이런 상황일 때, PyTorch에서 Multi-Loss를 구현하는 방법을 전반적으로 살펴보겠습니다.
또한 LLM이나 Generative Model을 다루는 경우 분산 컴퓨팅을 위한 Huggingface 라이브러리의 Accelerator를 활용하기도 합니다.
따라서 기존에 존재하는 PyTorch의 코드를 Accelerator로 적용하는 방법을 살펴보고, 이 때도 Multi-Loss를 구현하면서 어떤 것을 주의해야하는지도 살펴보려고합니다.
<구성>
1. PyTorch
a. 기본 구조
b. Multi-Loss
2. Accelerate
a. PyTorch에서 Accelerate로
b. Accelerate에서의 Multi-Model 주의점
c. Accelerate에서의 Multi-Loss
글효과 분류1 : 코드
글효과 분류2 : 폴더/파일
글효과 분류3 : 용어설명
글효과 분류4 : 글 내 참조
글효과 분류5 : 글 내 참조2
글효과 분류6 : 글 내 참조3
1. PyTorch
Multi-Loss를 PyTorch에서 구현하는 방법을 살펴보기 위해, 먼저 PyTorch의 기본 구현 구조 먼저 살펴본 뒤, Multi-Loss를 구현함에 있어 주의해야 할 것들을 실험과 함께 살펴보겠습니다.
a. 기본 구조
기본 구조는 아래와 같이 여섯개의 Step으로 이루어집니다.
- Step1. 모델 선언
- Step2. 데이터로더 선언
- Step3. 옵티마이저 & Loss 선언
- Step4. 학습
- Step5. 학습 종료
- Step6. 실행
각각의 Step에 대해 간단히 살펴보겠습니다.
Step1. 모델 선언
모델은 아래와 같이 선언하게 됩니다.
class MyModel(torch.nn.Module):
def __init__(self):
raise NotImpelentedError
def forward(self, input):
raise NotImpelentedError
model = MyModel()
MODEL = MODEL.cuda(0)
Step2. 데이터로더 선언
데이터로더를 위해 먼저 데이터셋을 정의합니다.
class MyDataset(torch.utils.data.Dataset):
def __init__(self):
raise NotImpelentedError
def __len__(self):
raise NotImpelentedError
def __getitem__(self,idx):
raise NotImpelentedError
데이터셋이 정의되었으면, 데이터셋을 활용해 아래와 같이 데이터로더를 만들어줍니다.
train_set = MyDataset()
batch_size = 4
num_workers = 2
def collation_fn(samples):
batched = list(zip(*samples))
result = []
for b in batched:
if isinstance(b[0], (int, float)):
b = np.array(b)
elif isinstance(b[0], torch.Tensor):
b = torch.stack(b)
elif isinstance(b[0], np.ndarray):
b = np.array(b)
else:
b = b
result.append(b)
return result
if is_distributed():
sampler = torch.utils.data.DistributedSampler(datasets['train'], shuffle=CONFIG.shuffle)
elif shuffle:
sampler = torch.utils.data.RandomSampler(datasets['train'])
else:
sampler = torch.utils.data.SequentialSampler(datasets['train'])
dataloader = torch.utils.data.DataLoader(
train_set,
batch_size,
shuffle=True,
sampler=sampler,
num_workers=num_workers,
persistent_workers=True,
pin_memory=True,
drop_last=True,
collate_fn=collation_fn)
Step3. 옵티마이저 & Loss 선언
다음으로 학습에 활용할 옵티마이저를 선언해줍니다.
optimizer = torch.optim.Adam(MODEL.parameters(), lr=1e-3)
역시나 옵티마이저는 Learning Rate Scheduler와 함께 사용됩니다.
lr_scheduler = ExponentialLR(optimizer, gamma=0.9)
이제 Loss를 만들어줄 함수를 정의해야합니다. 아래는 단순한 예시 하나를 보였습니다.
import torch.nn.functional as F
def Loss(model_pred, target):
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
return loss
Step4. 학습
이제 학습을 진행합니다. 보통은 아래와 같은 순서로 구성됩니다.
for epoch in range(start_epoch, max_epoch):
for batch_idx, batch_data in enumerate(dataset_loader):
# 1. Clear Gradients
optimizer.zero_grad()
# 2. Data to Device
input = batch_data['input'].to(device)
target = batch_data['target'].to(device)
# 3. Get Loss
output = MODEL(input)
loss = Loss(output, target)
# 4. Compute Gradients in Parameter
loss.backward()
# 5. Optmization Step
optimizer.step()
lr_scheduler.step()
4번째의 backward()를 통해 모델 내부의 grad라는 객체의 값을 만들어주고 optimizer.step()를 통해 업데이트를 진행합니다.

Step5. 학습 종료
PyTorch는 따로 학습을 종료할 때 처리해주어야할 부분은 없습니다.
Step6. 실행
이제 실행해보겠습니다. 아래와 같이 만들어준 파일을 argument와 함께 실행해줍니다.
python3 train.py \
--pretrained="./path/to/model"
이 글에서 설명할 예시 코드는 고맙게도 다른 블로그에 예시코드가 있어 이를 기준으로 설명하겠습니다.
** https://yoonchang.tistory.com/36
-----------------------------------------------------------
<PyTorch 기본 예시 코드>
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchsummary import summary
import platform
import matplotlib.pyplot as plt
import numpy as np
# build a network model,
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 5) #in, out, filtersize
self.pool = nn.MaxPool2d(2, 2) #2x2 pooling
self.conv2 = nn.Conv2d(32, 64, 5)
self.fc1 = nn.Linear(64 * 4 * 4, 1000)
self.fc2 = nn.Linear(1000, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 4 * 4)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
def train(log_interval, model, device, train_loader, optimizer, epoch):
model.train()
running_loss =0.0
criterion = nn.CrossEntropyLoss() #defalut is mean of mini-batchsamples
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), running_loss/log_interval), end="\r")
running_loss =0.0
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
criterion = nn.CrossEntropyLoss(reduction='sum') #add all samples in a mini-batch
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
test_loss += loss.item()
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
epochs = 5
learning_rate = 0.001
batch_size = 32
test_batch_size=1000
log_interval =100
#print(torch.cuda.get_device_name(0))
print(torch.cuda.is_available())
use_cuda = torch.cuda.is_available()
print("use_cude : ", use_cuda)
device = torch.device("cuda" if use_cuda else "cpu")
print(device)
#device = "cpu"
nThreads = 1 if use_cuda else 2
if platform.system() == 'Windows':
nThreads =0 #if you use windows
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# datasets
trainset = torchvision.datasets.FashionMNIST('./data',
download=True,
train=True,
transform=transform)
testset = torchvision.datasets.FashionMNIST('./data',
download=True,
train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=nThreads)
test_loader = torch.utils.data.DataLoader(testset, batch_size=test_batch_size,
shuffle=False, num_workers=nThreads)
# constant for classes
classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot')
# model
model = Net().to(device)
summary(model, input_size=(1, 28, 28))
#optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
optimizer = optim.Adam(model.parameters(),lr=learning_rate)
for epoch in range(1, epochs + 1):
train(log_interval, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
# Save model
torch.save(model.state_dict(), "저장할 파일의 경로를 써주도록 하자")
if __name__ == '__main__':
main()-----------------------------------------------------------
b. Multi-Loss
그럼 위에서 소개된 예시코드의 모델에 Multi-Loss를 적용하는 과정을 살펴보겠습니다.
1. Single Model
먼저 단순히 하나의 모델에 Multi-Loss를 적용했을 때 gradient가 어떻게 되는지 확인해보겠습니다.
실험을 정확히 살펴보기 위해 위 예시 코드를 아래와 같이 deterministic하게 만들어주었습니다.
- Dataloader의 데이터 shuffle을 off합니다.
- 모델을 초기화할 때 uniform으로 초기화 해줍니다.
def weight_init_function(submodule, mode="uniform"):
if isinstance(submodule, torch.nn.Conv2d) or isinstance(submodule, torch.nn.Linear) :
if mode=="xavier":
torch.nn.init.xavier_uniform_(submodule.weight)
submodule.bias.data.fill_(0.01)
elif mode=="uniform":
submodule.weight.data.fill_(1.0)
submodule.bias.data.zero_()
else :
raise Exception("mode {} is not supported".format(mode))
def main():
# ...
train_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=False, num_workers=nThreads)
# ...
# model
model = Net().to(device)
model.apply(weight_init_function)
summary(model, input_size=(1, 28, 28))
optimizer = optim.Adam(model.parameters(),lr=learning_rate)
for epoch in range(1, epochs + 1):
train(log_interval, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
# ...
if __name__ == '__main__':
main()
학습 코드는 아래와 같이 진행했습니다. 학습시 아래 4개의 케이스를 살펴보려고 합니다.
- CaseA : 주석제거하지 않고 실행 : loss만 적용
- CaseB : OptionB만 주석제거하고 실행 : loss2만 적용
- CaseC : OptionC만 주석제거하고 실행 : loss+loss2 적용
- CaseD : OptionD만 주석제거하고 실행 : loss에 대해 gradient 계산하고 loss2에 대해 gradient계산
def train(log_interval, model, device, train_loader, optimizer, epoch):
model.train()
running_loss =0.0
criterion = nn.MSELoss()
criterion2 = nn.MSELoss()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(torch.float32).to(device), target.to(torch.float32).to(device)
optimizer.zero_grad()
print("Check1 : {}".format(model.conv1.weight.grad)) # None
output = model(data)
loss = criterion(output, target)
loss2 = criterion2(output, target)
print("Check2 : {}".format(model.conv1.weight.grad)) # None
#loss = loss2 # OptionB
#loss += loss2 # OptionC
loss.backward()
#loss2.backward() # OptionD : Error
print("Check3 : {}".format(model.conv1.weight.grad))
optimizer.step()
print("Check4 : {}".format(model.conv1.weight.grad))
# ...
코드를 보면 기본적으로 위 결과를 자세히 보기위해 모델의 첫번째 conv1 layer의 gradient를 프린트했는데, 프린트 결과는 항상 아래와 같을 것입니다.
- Check1, Check2 : 둘은 같으며, 항상 None입니다.
- Check3, Check4 : 둘은 같으며, loss의 gradient가 얼마나 적용되었는지 확인할 수 있습니다.
Check1,2는 항상 None이고 Check4는 항상 Check3과 같을 것이므로, 위 정의한 Case A,B,C,D 별로 Check3가 어떻게 다르게 나오는지 살펴보겠습니다.
하나의 모델에 두개의 Loss를 적용한 결과는 아래와 같았습니다.
- CaseA : loss만 적용
Check3 : tensor([[[[1.2601e+17, 1.6547e+17, 2.1513e+17, 2.2090e+17, 2.1946e+17],
- CaseB : loss2만 적용
Check3 : tensor([[[[1.2601e+17, 1.6547e+17, 2.1513e+17, 2.2090e+17, 2.1946e+17],
- CaseC : loss+loss2 적용
Check3 : tensor([[[[2.5202e+17, 3.3093e+17, 4.3025e+17, 4.4181e+17, 4.3891e+17],
결국, gradient가 loss와 loss2가 중복으로 적용되었네요.
- CaseD : loss에 대해 gradient 계산하고 loss2에 대해 gradient계산

같은 모델에 대해 backward()를 여러번 부름으로써 위와 같은 에러가 납니다.
보통 foward() 과정에서 PyTorch 모델의 Graph가 생성되는데, 이후에 backward()함수가 실행되면 gradient를 구한 이후에 Graph와 Intermediate Tensors들은 필요없어 이들을 버립니다.
따라서 backward()를 두번째 호출하는 경우 이 값들이 필요한데 없기 때문에 에러가 납니다.
해결 방법은 아래와 같이 두가지입니다.
- 방법1. 첫번째 loss를 계산할 때 loss.backward(retain_graph=True)를 통해 모델의 그래프들을 삭제하지 않고 계산합니다.
- 방법2. Loss에서 사용될 graph가 서로 exclusive하게 만들어지도록 forward()과정에서 잘 조율합니다.
** "3. Multi Model (Detached Loss)" 참조 - 방법3. 여러개 Loss를 각각의 backward()를 실행해 구하지 않고, Loss를 모두 더해준뒤 한번에 backward()를 계산합니다.
CaseD는 이후의 실험에서도 같은 양상을 보일 것이기 때문에 이후에는 따로 보지 않겠습니다.
결과적으로 하나의 모델에 두개의 Loss를 적용한 그림은 아래와 같습니다.
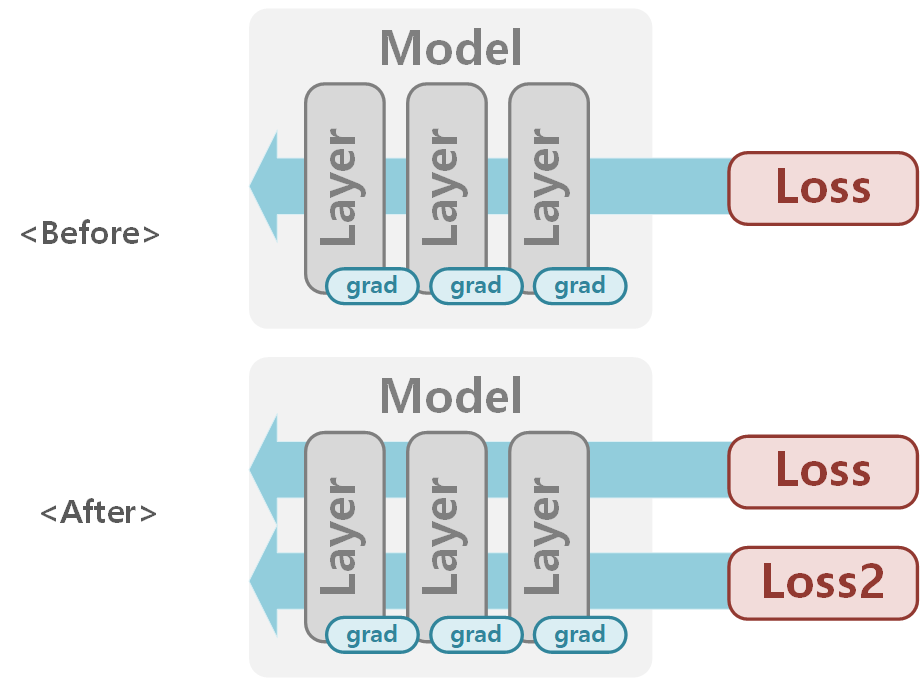
2. Multi Model (Duplicated Loss)
이번엔 연계되어있는 두 개의 Model에 Loss를 각각 적용해보겠습니다. 이를 위해 코드를 아래와 같이 수정했습니다.
- 연결될 두개의 모델 Net과 Net2를 선언하고 위와 같이 uniform으로 초기화 했습니다.
- optimizer 하나에 두 모델을 함께 사용하겠습니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 5) #in, out, filtersize
self.pool = nn.MaxPool2d(2, 2) #2x2 pooling
self.conv2 = nn.Conv2d(32, 64, 5)
self.fc1 = nn.Linear(64 * 4 * 4, 1000)
self.fc2 = nn.Linear(1000, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 4 * 4)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
class Net2(nn.Module):
def __init__(self):
super(Net2, self).__init__()
self.fc = nn.Linear(10, 10)
def forward(self, x):
x = self.fc(x)
return x
def main():
# ...
# model
model = Net().to(device)
model.apply(weight_init_function)
model2 = Net2().to(device)
model2.apply(weight_init_function)
summary(model, input_size=(1, 28, 28))
import itertools
params = itertools.chain(model.parameters(), model2.parameters())
optimizer = optim.Adam(params,lr=learning_rate)
# ...
if __name__ == '__main__':
main()
학습은 아래와 같이 진행됩니다.
def train(log_interval, model, model2, device, train_loader, optimizer, epoch):
model.train()
running_loss =0.0
criterion = nn.MSELoss()
criterion2 = nn.MSELoss()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(torch.float32).to(device), target.to(torch.float32).to(device)
optimizer.zero_grad()
print("Check1 : {}".format(model.conv1.weight.grad)) # None
print("Check1-2 : {}".format(model2.fc.weight.grad)) # None
output = model(data)
loss = criterion(output, target)
output2= model2(output)
loss2 = criterion2(output2, target)
print("Check2 : {}".format(model.conv1.weight.grad)) # None
print("Check2-2 : {}".format(model2.fc.weight.grad)) # None
#loss = loss2 # OptionB
#loss += loss2 # OptionC
loss.backward()
print("Check3 : {}".format(model.conv1.weight.grad)) #
print("Check3-2 : {}".format(model2.fc.weight.grad)) #
optimizer.step()
print("Check4 : {}".format(model.conv1.weight.grad)) #
print("Check4-2 : {}".format(model2.fc.weight.grad)) #
# ...
이번엔 위 결과를 보기위해 첫번째 모델 첫번째 conv1 layer와 두번째 모델 첫번째 fc layer의 gradient를 프린트했는데, 역시나 케이스 별로 Check3만 어떻게 다르게 나오는지 살펴보겠습니다.
- CaseA : loss만 적용
Check3 : tensor([[[[1.2601e+17, 1.6547e+17, 2.1513e+17, 2.2090e+17, 2.1946e+17],
Check3-2 : None
예상한 것과 같이 첫번째 모델의 loss는 적용하고, 두번째 모델은 loss2는 적용되지 않았습니다.
- CaseB : loss2만 적용
Check3 : tensor([[[[1.2593e+19, 1.6537e+19, 2.1500e+19, 2.2077e+19, 2.1932e+19],
Check3-2 : tensor([[1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20,
첫번째 모델의 loss는 적용하지 않고, 두번째 모델의 loss2는 적용되었습니다. 근데 두 모델 모두 결국 grad는 계산되었네요.
- CaseC : loss+loss2 적용
Check3 : tensor([[[[1.2724e+19, 1.6708e+19, 2.1722e+19, 2.2306e+19, 2.2159e+19],
Check3-2 : tensor([[1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20,
첫번째 모델의 loss와 두번째 모델의 loss2 모두 적용되었습니다. 역시 두 모델 모두 grad가 계산되었습니다.
두개의 모델의 두개의 Loss를 각각 적용한 형태는 아래와 같습니다.
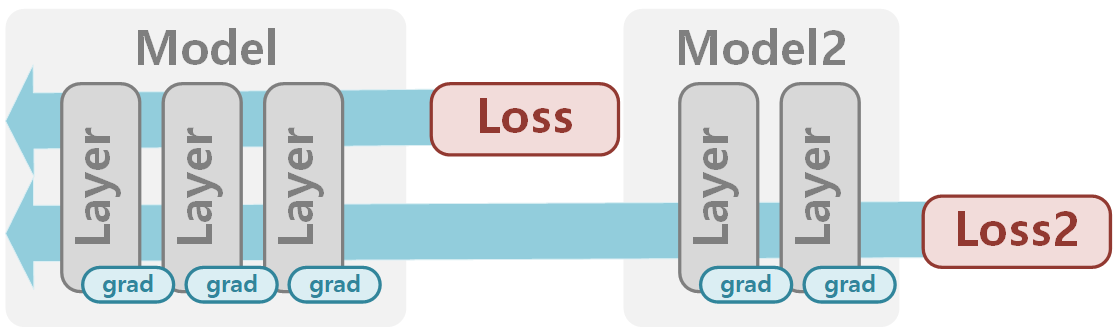
3. Multi Model (Detached Loss)
근데 위와 같이 Loss를 적용하면, 내가 만든 Loss가 원하지 않는 모델까지 적용되는 경우가 생깁니다.
그래서 원하는 부위에만 Loss를 적용하기 위해 foward()과정에서 detach()를 활용해 graph를 서로 구분했습니다.
def train(log_interval, model, model2, device, train_loader, optimizer, epoch):
model.train()
running_loss =0.0
criterion = nn.MSELoss()
criterion2 = nn.MSELoss()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(torch.float32).to(device), target.to(torch.float32).to(device)
optimizer.zero_grad()
print("Check1 : {}".format(model.conv1.weight.grad)) # None
print("Check1-2 : {}".format(model2.fc.weight.grad)) # None
output = model(data)
loss = criterion(output, target)
output2= model2(output.detach())
loss2 = criterion2(output2, target)
print("Check2 : {}".format(model.conv1.weight.grad)) # None
print("Check2-2 : {}".format(model2.fc.weight.grad)) # None
#loss = loss2 # OptionB
#loss += loss2 # OptionC
loss.backward()
print("Check3 : {}".format(model.conv1.weight.grad)) #
print("Check3-2 : {}".format(model2.fc.weight.grad)) #
optimizer.step()
print("Check4 : {}".format(model.conv1.weight.grad)) #
print("Check4-2 : {}".format(model2.fc.weight.grad)) #
# ...
결과는 아래와 같습니다.
- CaseA : loss만 적용
Check3 : tensor([[[[1.2601e+17, 1.6547e+17, 2.1513e+17, 2.2090e+17, 2.1946e+17],
Check3-2 : None
첫번째 모델의 loss는 적용하고, 두번째 모델은 loss2는 적용되지 않았습니다.
- CaseB : loss2만 적용
Check3 : None,
Check3-2 : tensor([[1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20,
첫번째 모델의 loss는 적용하지 않았습니다. 두번째 모델의 loss2는 적용되었는데, 이전과 다르게 첫번째 모델에는 영향을 주지 않았습니다.
- CaseC : loss+loss2 적용
Check3 : tensor([[[[1.2601e+17, 1.6547e+17, 2.1513e+17, 2.2090e+17, 2.1946e+17],
Check3-2 : tensor([[1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20, 1.8269e+20,
첫번째 모델의 loss와 두번째 모델의 loss2 모두 적용되었습니다. 숫자를 살펴보면 정확히 CaseA와 CaseB의 결과를 더한 loss가 적용되었습니다.
이렇게 detach되어 loss를 적용한 형태는 아래와 같습니다.
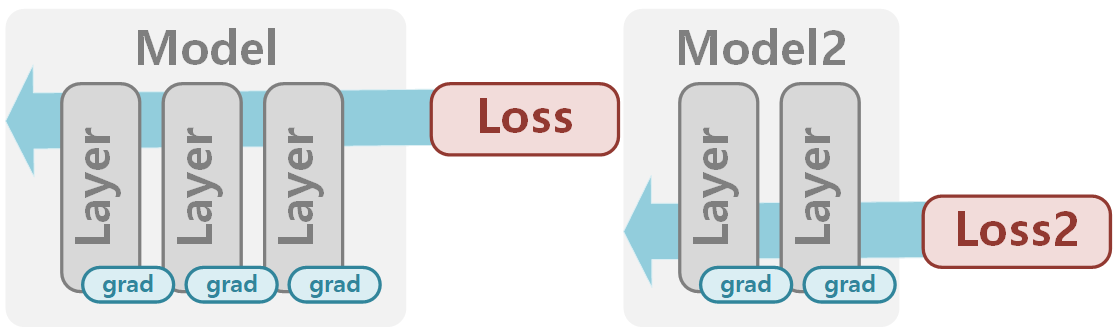
4. Multi Model (Detached Loss) + Multi Optimizer
사실 위와 같이 적용할 수도 있지만, 보통은 위와 같이 하나의 Optimizer를 통해 Loss를 여러개 적용하는 것은 어렵습니다.
왜냐하면 Optimizer는 "전체 Weight"를 고려하기 때문에 해당 Loss가 적용될 곳의 weight만을 고려하기 어렵기 때문입니다.
따라서 이번엔 Optimizer를 구분해서 제공하겠습니다. 어렵지는 않습니다. 그냥 두 모델의 파라미터에 대해 각각의 optimizer를 먼저 선언해줍니다.
def main():
# ...
model = Net().to(device)
model.apply(weight_init_function)
model2 = Net2().to(device)
model2.apply(weight_init_function)
optimizer = optim.Adam(model.parameters(),lr=learning_rate)
optimizer2 = optim.Adam(model2.parameters(),lr=learning_rate)
for epoch in range(1, epochs + 1):
train(log_interval, model, model2, device, train_loader, optimizer, optimizer2, epoch)
test(model, device, test_loader)
# ...
if __name__ == '__main__':
main()
아래와 같이 학습하는 과정에도 두 개의 Optimizer를 활용해 적용합니다.
def train(log_interval, model, model2, device, train_loader, optimizer, optimizer2, epoch):
model.train()
running_loss =0.0
criterion = nn.MSELoss()
criterion2 = nn.MSELoss()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(torch.float32).to(device), target.to(torch.float32).to(device)
optimizer.zero_grad()
optimizer2.zero_grad()
print("Check1 : {}".format(model.conv1.weight.grad)) # None
print("Check1-2 : {}".format(model2.fc.weight.grad)) # None
output = model(data)
loss = criterion(output, target)
output2= model2(output.detach())
loss2 = criterion2(output2, target)
print("Check2 : {}".format(model.conv1.weight.grad)) # None
print("Check2-2 : {}".format(model2.fc.weight.grad)) # None
#loss = loss2 # OptionB
#loss += loss2 # OptionC
loss.backward()
print("Check3 : {}".format(model.conv1.weight.grad)) #
print("Check3-2 : {}".format(model2.fc.weight.grad)) #
optimizer.step()
optimizer2.step()
print("Check4 : {}".format(model.conv1.weight.grad)) #
print("Check4-2 : {}".format(model2.fc.weight.grad)) #
# ...2. Accelerate
transformers 라이브러리에서 주로 사용하는 Huggingface Accelerate는, PyTorch 분산 학습을 매우 간단히 만들어 줍니다.
학습 코드는 거의 수정하지 않아도 되며, accelerate CLI 도구로 분산 설정을 자동화합니다.
그럼 위에서 구축한 모델에서 시작해 Accelerate를 적용하기 위해 셋팅하는 과정을 살펴보고, 위에서 살펴본 것처럼 multi-loss를 적용하는 과정의 주의점을 살펴보겠습니다.
a. PyTorch에서 Accelerate로
PyTorch 코드를 Accelerate로 바꾸는 과정은 Huggingface에서도 잘 설명이 되어있습니다.
** https://huggingface.co/docs/accelerate/main/en/basic_tutorials/migration
이번 글은 Huggingface에서 구축해 놓은 아래의 예시 코드를 참고해서 작성했습니다.
** https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py
Step0. Logger와 Accelerate선언
Accelerate를 활용하기 위해 필요한 객체를 먼저 선언해줍니다.
로깅에 활용한 logger는 아래와 같이 선언해줍니다.
from accelerate.logging import get_logger
logger = get_logger(__name__, log_level="INFO")
그리고 Accelerate를 중재할 accelerator 객체는 아래와 같이 선언해줍니다.
from accelerate import Accelerator
from accelerate.utils import ProjectConfiguration
accelerator_project_config = ProjectConfiguration(project_dir=/path/to/output, logging_dir=/path/to/logs)
accelerator = Accelerator(
gradient_accumulation_steps=1,
mixed_precision="fp16",
log_with="tensorboard",
project_config=accelerator_project_config,
)
이후에 accelerator 객체를 활용해 다양한 셋팅을 진행합니다.
아래 설명되지 않은 아래와 함수들은 아래 더보기를 참조하시고, 기본적으로 내용은 아래와 같습니다.
- accelerator_init() : verbosity와 seed 등을 설정하고, 결과를 담을 폴더를 만들어줍니다.
- accelerator_no_func() : transformers.PreTrainedModel의 save_pretrained()와 torch.nn.Module의 load_state_dict() 등의 함수를 위한 hook을 등록해줍니다.
- weight_dtype : accelerator의 weight precision 정보를 얻어냅니다. 학습되지 않을 inference전용 weight들을 cast하는데 사용됩니다.
- mixed_precision : accelerator의 연산 precision 정보를 얻어냅니다. 이 글에서는 사용되지 않습니다.
# Disable AMP for MPS.
if torch.backends.mps.is_available():
accelerator.native_amp = False
logger.info(accelerator.state, main_process_only=False)
from tools.accelerator_func import accelerator_init, accelerator_no_func
accelerator_init(accelerator)
accelerator_no_func(accelerator)
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
mixed_precision = accelerator.mixed_precision
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
mixed_precision = accelerator.mixed_precision-------------------------------------------------------------------
<accelerator_init과 accelerator_no_func 함수>
위에서 초기화하는데 쓰인 함수는 아래와 같습니다.
import os
import accelerate
from packaging import version
import datasets
import transformers
from accelerate.utils import set_seed
import diffusers
from diffusers import UNet2DConditionModel
def accelerator_init(accelerator):
seed = 42
output_dir="./result_path"
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if seed is not None:
set_seed(seed)
# Handle the repository creation
if accelerator.is_main_process:
if output_dir is not None:
os.makedirs(output_dir, exist_ok=True)
def accelerator_no_func(accelerator):
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
for _ in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)-------------------------------------------------------------------
Step1. 모델 선언
모델 선언은 PyTorch와 다르지 않습니다.
하지만 내부에 여러개의 모델이 있는 경우 문제가 될 수 있는데 이는 다음 챕터에서 다루겠습니다.
class MyModel(torch.nn.Module):
def __init__(self):
raise NotImpelentedError
def forward(self, input):
raise NotImpelentedError
model = MyModel()
다음으로 모델을 accelerator와 같은 device나 data type으로 바꿔주기 위해 아래와 같이 prepare()함수를 활용합니다. prepare()함수는 input에 관계 없이 iterative하게 동작하므로, 뒤에서도 활용됩니다.
또한 to_acc_type()함수는 필자가 직접 정의한 함수인데, 학습에 사용하지 않는 모델들의 파라미터를 infererence에 적합한 dtype(fp16 등)으로 바꾸어 줍니다.
** to_acc_type 함수는 간단하므로 뒤 multi-model 관련 코드를 참조하세요
unet = accelerator.prepare(MODEL.unet)
model.to_acc_type(accelerator.device, weight_dtype)
Step2. 데이터로더 선언
Dataloader 선언은 PyTorch와 다르지 않습니다.
dataset, image_column, caption_column = get_dataset(args)
# Load scheduler, tokenizer and models.
from transformers import CLIPTokenizer
tokenizer = CLIPTokenizer.from_pretrained(
pretrained_model_name_or_path, subfolder="tokenizer", revision=None
)
train_dataloader, train_len = get_loader(
args, dataset,
image_column, caption_column,
accelerator, tokenizer
)
그리고 역시나 이렇게 선언된 데이터로더도 prepare()함수를 통해 준비를 해줍니다.
train_dataloader = accelerator.prepare(train_dataloader)
Step3. 옵티마이저 & Loss 선언
Optimizer와 Learning Rate Scheduler를 선언하는 것도 PyTorch와 다르지 않습니다. 먼저 Optimizer를 선언합니다.
scale_lr=False
adam_beta1=0.9
adam_beta2=0.999
adam_weight_decay=1e-2
adam_epsilon=1e-08
train_batch_size=16
if scale_lr:
learning_rate = (
learning_rate * train_batch_size * accelerator.num_processes
)
optimizer = torch.optim.AdamW(
model.unet.parameters(),
lr=learning_rate,
betas=(adam_beta1, adam_beta2),
weight_decay=adam_weight_decay,
eps=adam_epsilon,
)
learning scheduler의 경우는 사용할 num_warmup_step과 num_training_step을 accelerator를 활용해서 정해줍니다.
** accelerator.num_processes는 가용한 GPU의 개수를 의미합니다.
- num_warmup_step : 가용한 GPU 개수에 일부 곱한 만큼 warmup을 진행합니다.
- num_training_step : 가용한 GPU 개수만큼 데이터 전체를 sharding하고, 하나의 GPU에서 처리할 num_update_steps를 기준으로 전체 num_training_steps를 측정합니다.
import math
max_train_steps=None
num_train_epochs=1000
num_warmup_steps_for_scheduler = 500 * accelerator.num_processes
if max_train_steps is None:
len_train_dataloader_after_sharding = math.ceil(len(train_dataloader) / accelerator.num_processes)
num_update_steps_per_epoch = math.ceil(len_train_dataloader_after_sharding / 1)
num_training_steps_for_scheduler = (
num_train_epochs * num_update_steps_per_epoch * accelerator.num_processes
)
else:
num_training_steps_for_scheduler = max_train_steps * accelerator.num_processes
if max_train_steps is None:
max_train_steps = num_train_epochs * num_update_steps_per_epoch
num_train_epochs = math.ceil(max_train_steps / num_update_steps_per_epoch)
from diffusers.optimization import get_scheduler
lr_scheduler = get_scheduler(
“cosine_with_restarts”,
optimizer=optimizer,
num_warmup_steps=num_warmup_steps_for_scheduler,
num_training_steps=num_training_steps_for_scheduler,
)
그리고 역시나 이렇게 선언된 optimizer와 lr_scheduler도 prepare()함수를 통해 준비를 해줍니다.
optimizer, lr_scheduler = accelerator.prepare(optimizer, lr_scheduler)
Step4. 학습
이제 학습을 진행합니다. 시작에 앞서 accelerator의 tracker를 main_process에서만 초기화합니다. 필수적이지는 않습니다.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
tracker_config.pop("validation_prompts")
accelerator.init_trackers("my-t2i", tracker_config)** 학습을 resume에서 하고 싶은 경우 아래 더보기 코드를 참조하세요
------------------------------------------------------
<accelerator에서 resume하기>
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint, epoch
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint-epoch")]
dirs = sorted(dirs, key=lambda x: int(x.split("checkpoint-epoch")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
if '/' in args.resume_from_checkpoint:
# checkpoint from other path
output_dir = args.resume_from_checkpoint.split(path)[0]
else:
output_dir = args.output_dir
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(output_dir, path))
first_epoch = int(path.split("checkpoint-epoch")[1]) + 1
if lr_scheduler.scheduler.base_lrs[0] != args.learning_rate:
# Update optimizer
for param_group in optimizer.param_groups:
param_group['lr'] = args.learning_rate
param_group['initial_lr'] = args.learning_rate
# Update lr scheduler
new_lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=0,
)
del lr_scheduler
lr_scheduler = accelerator.prepare(new_lr_scheduler)
global_step = first_epoch * num_update_steps_per_epoch + 1
initial_global_step = global_step
else:
initial_global_step = 0------------------------------------------------------
시작하기에 앞서 accelerator.num_processes를 활용해 모든 process의 배치사이즈를 구해줄 수 있습니다.
total_batch_size = train_batch_size * accelerator.num_processes
global_step = 0
first_epoch = 0
initial_global_step=0
from tqdm.auto import tqdm
progress_bar = tqdm(
range(0, max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
이제 학습을 진행합니다. accelerate의 주요한 활용은 아래와 같습니다.
- accelerator.accumulate() : 학습시 많은 배치 사이즈를 활용하게 되는데, 모델의 weight를 업데이트하기 전에 여러개의 배치에 대한 gradient를 accumulate하는 방법입니다.
즉, gradient를 분산시키고 accumulation함으로써, 메모리 limitation을 극복하기 위해 사용됩니다. - accelerator.gather() (선택): logging을 위해 모든 process에서 loss 정보들을 모아오는 과정입니다.
- accelerator.backward(loss) : loss.backward()였던 코드를 accelerator에서는 이와 같이 변경해주어야합니다.
- accelerator.sync_gradients (선택): gradients가 모든 process에서 처리되었는지 확인할 때 사용합니다.
max_grad_norm = 1.0
for epoch in range(first_epoch, num_train_epochs):
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
target_model = [model.unet]
with accelerator.accumulate(*target_model):
pixel_values = batch['pixel_values']
input_text_ids = batch['input_ids']
model_pred, target, timesteps = model(pixel_values, input_text_ids)
loss_DM = DM_Loss(model_pred, target, timesteps)
loss_All = loss_DM
avg_loss = accelerator.gather(loss_All.repeat(train_batch_size)).mean()
train_loss += avg_loss.item()
accelerator.backward(loss_All)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(model.unet.parameters(), max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
accelerator.log({
"train_loss": train_loss,
}, step=global_step)
train_loss = 0.0
logs = {"step_loss_DM": loss_DM.detach().item(),
"lr_DM": lr_scheduler.get_last_lr()[0],
}
progress_bar.set_postfix(**logs)
if global_step >= max_train_steps:
break
위에서 with accelerator.accumulate(model.unet)와 같이 구현했는데, 사실 accelerator.accumulate를 활용하지 않고 아래와 같이 직접 flexible하게 loss를 쌓는 방법도 있습니다.
loss = loss / gradient_accumulation_steps
accelerator.backward(loss)
if (index+1) % gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step()
optimizer.zero_grad()
Step5. 학습 종료
accelerator에서는 학습을 종료할 때 필수적으로 불러주어야하는 코드가 있습니다.
먼저, 아래와 같은 함수를 통해 모든 프로세스들이 join할 수 있도록 해줍니다.
accelerator.wait_for_everyone()** Validation을 위한 코드가 궁금하시면 아래 더보기를 참조하세요
------------------------------------------------------------
<Validation하는 코드>
Validation하는 내용은 선택이기 때문에 따로 준비했습니다. 아래에서 참고할 점은 아래와 같습니다.
- accelerator.save_state(save_path) : 현재 모델의 checkpoint를 저장해줍니다.
- accelerator.unwrap_model(model) : 앞서 accelerator.prepare()로 인해 accelerator화 된 모델을 unwrap합니다.
- pipeline.save_pretrained(output_dir) : 나중에 from_pretrained()로 부를 수 있는 huggingface의 모델 형태 저장입니다.
from diffusers import StableDiffusionPipeline
from diffusers.utils.torch_utils import is_compiled_module
# Function for unwrapping if model was compiled with `torch.compile`.
def unwrap_model(model, accelerator):
model = accelerator.unwrap_model(model)
model = model._orig_mod if is_compiled_module(model) else model
return model
# Create the pipeline using the trained modules and save it.
if accelerator.is_main_process:
accelerator.save_state(save_path)
unet = unwrap_model(DM_MODEL.unet, accelerator)
vae = VAE_MODEL.vae
pipeline = StableDiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
text_encoder=DM_MODEL.text_encoder,
vae=vae,
unet=unet,
revision=None,
variant=None,
)
pipeline.save_pretrained(args.output_dir)
# Run a final round of inference.
images = []
if args.validation_prompts is not None:
logger.info("Running inference for collecting generated images...")
pipeline = pipeline.to(accelerator.device)
pipeline.torch_dtype = weight_dtype
pipeline.set_progress_bar_config(disable=True)
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
for i in range(len(args.validation_prompts)):
with torch.autocast("cuda"):
image = pipeline(args.validation_prompts[i], num_inference_steps=20, generator=generator).images[0]
images.append(image)------------------------------------------------------------
다음으로 accelerate의 tracker가 모든 기능을 끝낼 수 있도록 아래 함수를 불러줍니다.
accelerator.end_training()
Step6. 실행
앞서 아래와 같이 실행했던 코드라고 했을 때
python3 train.py \
--pretrained="./path/to/model"아래와 같이 실행해줍니다.
accelerate launch --main_process_port $MAIN_PROCESS_PORT --mixed_precision=fp16 -m train \
--pretrained="./path/to/model"b. Accelerate에서의 Multi-Model 주의점
이제 위와 같이 구현된 Accelerator기반의 코드를 Multi-Loss 실험을 진행하려고 하는데, 실험 중 "두개의 구분된 모델"을 Accelerate에서 다룰 수 있어야하는데, 두개의 구분된 모델을 Accelerator을 활용해 학습할 때는 주의점들이 있습니다.
먼저 라이브러리 import하고 시작하겠습니다.
import torch
import accelerate
from accelerate.state import AcceleratorState
from transformers.utils import ContextManagers
그럼 이제 위 코드에서 구현된 하나의 모델을 두개로 나눈 것을 살펴보겠습니다.
첫번째 모델은 아래와 같습니다. 일반적인 모델과 같지만 ContextManagers(deepspeed_zero_init_disabled_context_manager())라는 함수로 감싸진 후에 선언이 되었습니다.
from diffusers import AutoencoderKL
class MyVAE(torch.nn.Module):
def __init__(self, pretrained_model_name_or_path, training_mode):
super().__init__()
def deepspeed_zero_init_disabled_context_manager():
"""
returns either a context list that includes one that will disable zero.Init or an empty context list
"""
deepspeed_plugin = AcceleratorState().deepspeed_plugin if accelerate.state.is_initialized() else None
if deepspeed_plugin is None:
return []
return [deepspeed_plugin.zero3_init_context_manager(enable=False)]
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
self.vae = AutoencoderKL.from_pretrained(
pretrained_model_name_or_path,
subfolder="vae",
revision=None,
variant=None
)
self.training_mode = training_mode
if self.training_mode:
self.vae.train()
else:
self.vae.requires_grad_(False)
self.weight_dtype = torch.float32
def to_acc_type(self, device, weight_dtype):
if not self.training_mode:
self.vae.to(device, dtype=weight_dtype)
self.weight_dtype=weight_dtype
def forward(self, pixel_values):
# Convert images to latent space
posterior = self.vae.encode(pixel_values.to(self.weight_dtype))
latents = posterior.latent_dist.sample()
reconstructed = self.vae.decode(latents).sample
latents = latents * self.vae.config.scaling_factor
return latents, reconstructed, posterior
두번째 모델은 아래와 같습니다. 역시나 일반적인 모델과 같지만 ContextManagers(deepspeed_zero_init_disabled_context_manager())라는 함수로 감싸진 후에 선언이 되었습니다.
from transformers import CLIPTextModel
from diffusers import DDPMScheduler, UNet2DConditionModel
class MyDM(torch.nn.Module):
def __init__(self, pretrained_model_name_or_path):
super().__init__()
def deepspeed_zero_init_disabled_context_manager():
"""
returns either a context list that includes one that will disable zero.Init or an empty context list
"""
deepspeed_plugin = AcceleratorState().deepspeed_plugin if accelerate.state.is_initialized() else None
if deepspeed_plugin is None:
return []
return [deepspeed_plugin.zero3_init_context_manager(enable=False)]
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
self.text_encoder = CLIPTextModel.from_pretrained(
pretrained_model_name_or_path, subfolder="text_encoder", revision=None, variant=None
)
self.unet = UNet2DConditionModel.from_pretrained(
pretrained_model_name_or_path, subfolder="unet", revision=None
)
# Freeze vae and text_encoder and set unet to trainable
self.text_encoder.requires_grad_(False)
self.unet.train()
self.noise_scheduler = DDPMScheduler.from_pretrained(pretrained_model_name_or_path, subfolder="scheduler")
self.weight_dtype = torch.float32
self.noise_offset = 0
self.input_perturbation = 0
self.prediction_type=None
def to_acc_type(self, device, weight_dtype):
# Move text_encode and vae to gpu and cast to weight_dtype
self.text_encoder.to(device, dtype=weight_dtype)
self.weight_dtype=weight_dtype
def forward(self, latents, input_text_ids):
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
if self.noise_offset:
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
noise += self.noise_offset * torch.randn(
(latents.shape[0], latents.shape[1], 1, 1), device=latents.device
)
if self.input_perturbation:
new_noise = noise + self.input_perturbation * torch.randn_like(noise)
bsz = latents.shape[0]
# *************************************************************** timestep & Forward
# Sample a random timestep for each image
timesteps = torch.randint(0, self.noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
if self.input_perturbation:
noisy_latents = self.noise_scheduler.add_noise(latents, new_noise, timesteps)
else:
noisy_latents = self.noise_scheduler.add_noise(latents, noise, timesteps)
# *************************************************************** text condition
# Get the text embedding for conditioning
encoder_hidden_states = self.text_encoder(input_text_ids, return_dict=False)[0]
# *************************************************************** Reverse
# Get the target for loss depending on the prediction type
if self.prediction_type is not None:
# set prediction_type of scheduler if defined
self.noise_scheduler.register_to_config(prediction_type=self.prediction_type)
if self.noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif self.noise_scheduler.config.prediction_type == "v_prediction":
target = self.noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {self.noise_scheduler.config.prediction_type}")
# Predict the noise residual and compute loss
model_pred = self.unet(noisy_latents, timesteps, encoder_hidden_states, return_dict=False)[0]
return model_pred, target, timesteps
제가 참고한 코드에는 위와 같이 ContextManagers(deepspeed_zero_init_disabled_context_manager())라는 함수로 감싸진 이유에 대해 아래와 같이 설명이 되어있습니다.
Currently Accelerate doesn't know how to handle multiple models under Deepspeed ZeRO stage 3.
For this to work properly all models must be run through 'accelerate.prepare'.
But accelerate will try to assign the same optimizer with the same weights to all models during 'deepspeed.initialize', which of course doesn't work.
For now the following workaround will partially support Deepspeed ZeRO-3, by excluding the 2 frozen models from being partitioned during 'zero.Init' which gets called during 'from_pretrained'
So CLIPTextModel and AutoencoderKL will not enjoy the parameter sharding across multiple gpus and only UNet2DConditionModel will get ZeRO sharded.
이는 Deepspeed의 특징과 연관이 있어보이네요. 이에 대해 살펴보겠습니다.
먼저 Accelerate와 Deepspeed의 관계는 무엇일까요? Accelerate의 가이드에 보면 Accelerate는 DeepSpeed ZeRO의 아래와 같은 모든 feature를 포함하고 있다고 합니다.
** https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed
- ZeRO stages 1, 2 and 3
** ZeRO: Memory Optimizations Toward Training Trillion Parameter Models(HiPC'20) - ZeRO-Offload
** ZeRO-Offload: Democratizing Billion-Scale Model Training (USENIX ATC'21) - ZeRO-Infinity (which can offload to disk/NVMe)
** ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning (HiPC'21) - ZeRO++
** ZeRO++: Extremely Efficient Collective Communication for Giant Model Training (arxiv'23)
그렇다면 Accelerate는 항상 Deepspeed를 활용할까요?
Accelerate의 셋팅을 살펴보겠습니다.
** https://huggingface.co/docs/accelerate/package_reference/cli
# Check Setting
accelerate env
이번엔 직접 환경셋팅 하는 과정을 살펴보겠습니다. 아래와 같은 CLI를 통해 ~/.cache/huggingface/accelerate/default_config.yaml에 사용할 셋팅을 설명하는 파일이 위치하게 됩니다.
# Get Custom Setting
accelerate config
설정하기 귀찮은 경우 아래와 같이 default셋팅으로 할수도있습니다.
# Get Default Setting
accelerate config default
위 config하는 과정에서 보셔서 알 수 있겠지만 Deepspeed를 사용하는 것은 "선택"입니다.
또한 당연한 얘기지만 Deepspeed를 활용하려면 Deepspeed가 깔려 있어야 하는데, 위 테스트한 config과정에서 Deepspeed는 설치되어있지도 않았습니다.
그래도 만약 Deepspeed가 깔려있다면 Deepspeed ZeRO stage 1,2,3은 무엇일까요?
- DeepSpeed ZeRO Stage 1 : optimizer states를 sharding
** full parameter sharding : local 연산에 필요한 model parameter, gradients, optimizers들 의 부분집합만을 사용하게 하는 방법입니다. - DeepSpeed ZeRO Stage 2 : optimizer states와 gradients를 sharding
- DeepSpeed ZeRO Stage 2 Offload : optimizer states와 gradients를 CPU로 내려서 계산합니다.
- DeepSpeed ZeRO Stage 3 : optimizer states, gradients, parameters(, activation)를 sharding
컨셉을 살펴보았으니 다시 위에서 나왔던 글을 보겠습니다.
Currently Accelerate doesn't know how to handle multiple models under Deepspeed ZeRO stage 3.
For this to work properly all models must be run through 'accelerate.prepare'.
But accelerate will try to assign the same optimizer with the same weights to all models during 'deepspeed.initialize', which of course doesn't work.
For now the following workaround will partially support Deepspeed ZeRO-3, by excluding the 2 frozen models from being partitioned during 'zero.Init' which gets called during 'from_pretrained'
So CLIPTextModel and AutoencoderKL will not enjoy the parameter sharding across multiple gpus and only UNet2DConditionModel will get ZeRO sharded.
내용을 살펴보니 현재 Accelerate는 Deepspeed ZeRO stage 3에서 여러개의 모델을 관리하는 방법에 대해 준비가 안된 것 같습니다.
여러개 모델을 다루기 위해, accelerate.prepare()를 사용하면, 모든 모델을 GPU간에 partition(sharding)하지만 모든 모델을 한번의 deepspeed.initialize()를 통해 "하나의 optimizer"로 관리합니다.
근데, 이렇게 하면 "각각의 모델"의 파라미터를 서로 정확히 분리해서 Sharding하지 않기 때문에 원하지 않는 Gradient Update가 일어날 수도 있습니다.
임시해결책이자 부분적으로 Deepspeed ZeRO-3를 지원하기 위해, 세개 중 두개의 모델은 parition(sharding)되지 않도록 exclude하고 있는데, 이로 인해 CLIPTextModel과 AutoencoderKL는 멀티 GPU에 대해 parameter sharding을 막았다는 뜻입니다.
그럼 위와 같은 임시방편말고 방법이 없을까요? Huggingface에 따르면 예로 Teacher-Student모델을 학습할 때 두개의 Accelerator를 각각 선언해서 해결합니다.
물론 Deepspeed를 활용하지 않는 경우 이런 문제를 생각할 필요는 없습니다.
이제 여러개의 모델을 구현할 때 구현방법은 아래와 같습니다.
- 위와 같이 여러개의 모델을 각각의 Accelerator를 활용해 학습하기
** 두개의 Accelerator를 활용하는 경우 아래 링크의 코드와 같이 with accelerator1.accumulate(model1, model2)과 같이 둘중 하나의 accelerator에서 두 모델을 감싸면 됩니다.
** https://huggingface.co/docs/accelerate/main/en/usage_guides/deepspeed_multiple_model#using-multiple-models-with-deepspeed - Wrapper Model을 만들어 "하나의 모델"로 학습하기
- 각각의 모델을 따로 학습해보기 (Deepspeed ZeRO-3 활용 X)
위 해결책 1번과 2번은 직관적이므로, 3번으로 구현하고 싶은 상황에 대해 다뤄보겠습니다.
먼저 위 소개했던 모델을 선언하겠습니다.
DM_MODEL = MyDM(pretrained_model_name_or_path)
VAE_MODEL= MyVAE(pretrained_model_name_or_path, True)
두 모델은 하나의 Optimizer를 사용해서 학습하겠습니다. (추천드리지는 않고 이건 간단히 보이기 위함입니다.)
import itertools
params_to_optimize = itertools.chain(DM_MODEL.unet.parameters(), VAE_MODEL.vae.parameters())
optimizer = torch.optim.AdamW(
params_to_optimize,
lr=learning_rate,
betas=(adam_beta1, adam_beta2),
weight_decay=adam_weight_decay,
eps=adam_epsilon,
)
역시나 accelerator.prepare()를 통해 바꿔줍니다.
DM_MODEL.unet, VAE_MODEL.vae = accelerator.prepare(DM_MODEL.unet, VAE_MODEL.vae)
이제 학습하는 코드는 아래와 같습니다.
각각의 모델을 활용할 때 gradient를 분산시킨 뒤 accelerator.accumulate를 통해 다시 축적시킬 때, 이전과 다르게 accelerator.accumulate(DM_MODEL.unet, VAE_MODEL.vae)와 같이 두개의 모델을 넘겨줍니다.
max_grad_norm = 1.0
for epoch in range(first_epoch, num_train_epochs):
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
target_model = [DM_MODEL.unet, VAE_MODEL.vae]
with accelerator.accumulate(*target_model):
pixel_values = batch['pixel_values']
input_text_ids = batch['input_ids']
latents, reconstructed, posterior = VAE_MODEL(pixel_values)
model_pred, target, timesteps = DM_MODEL(latents, input_text_ids)
loss_DM = Loss(model_pred, target, timesteps)
loss_All = loss_DM
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss_All.repeat(train_batch_size)).mean()
train_loss += avg_loss.item()
# Backpropagate
accelerator.backward(loss_All)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(DM_MODEL.unet.parameters(), max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
accelerator.log({
"train_loss": train_loss,
}, step=global_step)
train_loss = 0.0
logs = {"step_loss_DM": loss_DM.detach().item(),
"step_loss_VAE": loss_VAE.detach().item(),
"lr_DM": lr_scheduler.get_last_lr()[0],
}
progress_bar.set_postfix(**logs)
if global_step >= max_train_steps:
breakc. Accelerate에서의 Multi-Loss
위 학습 코드에서는 두개의 모델로 확장은 했지만 두 개의 Loss로 학습하고 있지는 않습니다. 앞으로의 과정은 PyTorch에서와 크게 다르지 않습니다.
Multi-Loss로 변경하는 방법은 PyTorch에서 살펴보았던 것과 크게 다르지 않으므로, 이제 두개의 모델을 각각의 Loss를 활용해서 학습하겠습니다.
앞서 PyTorch에서 보았던 것 처럼 두 개의 모델에 각각의 Loss를 적용하기 위해 detach()도 적용해서 학습했습니다.
max_grad_norm = 1.0
for epoch in range(first_epoch, num_train_epochs):
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
target_model = [DM_MODEL.unet, VAE_MODEL.vae]
with accelerator.accumulate(*target_model):
pixel_values = batch['pixel_values']
input_text_ids = batch['input_ids']
latents, reconstructed, posterior = VAE_MODEL(pixel_values)
model_pred, target, timesteps = DM_MODEL(latents.detach(), input_text_ids)
loss_DM = DM_Loss(model_pred, target, timesteps)
loss_VAE = VAE_Loss(pixel_values, reconstructed, posterior)
loss_All = loss_DM + loss_VAE
avg_loss = accelerator.gather(loss_All.repeat(train_batch_size)).mean()
train_loss += avg_loss.item()
# Backpropagate
accelerator.backward(loss_All)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(DM_MODEL.unet.parameters(), max_grad_norm)
accelerator.clip_grad_norm_(VAE_MODEL.vae.parameters(), max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
accelerator.log({
"train_loss": train_loss,
}, step=global_step)
train_loss = 0.0
logs = {"step_loss_DM": loss_DM.detach().item(),
"step_loss_VAE": loss_VAE.detach().item(),
"lr_DM": lr_scheduler.get_last_lr()[0],
}
progress_bar.set_postfix(**logs)
if global_step >= max_train_steps:
break** 위에서 사용한 DM_Loss와 VAE_Loss에 대해 궁금하시면 아래 더보기를 참조하세요
---------------------------------------------------------------
<두 Loss 함수의 구현>
import torch
import torch.nn.functional as F
from diffusers.training_utils import compute_snr
def DM_Loss(model_pred, target, timesteps, snr_gamma=None):
if snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
snr = compute_snr(noise_scheduler, timesteps)
mse_loss_weights = torch.stack([snr, snr_gamma * torch.ones_like(timesteps)], dim=1).min(
dim=1
)[0]
if noise_scheduler.config.prediction_type == "epsilon":
mse_loss_weights = mse_loss_weights / snr
elif noise_scheduler.config.prediction_type == "v_prediction":
mse_loss_weights = mse_loss_weights / (snr + 1)
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
loss = loss.mean()
return loss
def VAE_Loss(pixel_values, reconstructed, posterior):
recon_loss = F.mse_loss(reconstructed, pixel_values)
kl_loss = posterior.latent_dist.kl().mean()
vae_loss = recon_loss + 0.1 * kl_loss
return vae_loss---------------------------------------------------------------
Multi-Loss를 구현했으니, 이번엔 optimizer를 두개 만들어 각각에 적용을 해보겠습니다.
가장 쉬운 방법은 optimizer 각각에 대해 구분된 Accelerator를 사용하는 방법이겠죠.
하지만 한개의 Accelerator에서 두개의 optimizer를 사용해도 문제는 없습니다. 먼저 optimizer를 아래와 같이 각각 구현한 뒤,
optimizer1 = torch.optim.AdamW(
DM_MODEL.unet.parameters(),
lr=learning_rate,
betas=(adam_beta1, adam_beta2),
weight_decay=adam_weight_decay,
eps=adam_epsilon,
)
optimizer2 = torch.optim.AdamW(
VAE_MODEL.vae.parameters(),
lr=learning_rate,
betas=(adam_beta1, adam_beta2),
weight_decay=adam_weight_decay,
eps=adam_epsilon,
)
learning rate scheduler를 구현해주고,
from diffusers.optimization import get_scheduler
lr_scheduler1 = get_scheduler(
“cosine_with_restarts”,
optimizer=optimizer1,
num_warmup_steps=num_warmup_steps_for_scheduler,
num_training_steps=num_training_steps_for_scheduler,
)
lr_scheduler2 = get_scheduler(
“cosine_with_restarts”,
optimizer=optimizer2,
num_warmup_steps=num_warmup_steps_for_scheduler,
num_training_steps=num_training_steps_for_scheduler,
)
PyTorch에서와 같이 각각 optimizer를 활용해 진행해주면됩니다.
max_grad_norm = 1.0
for epoch in range(first_epoch, num_train_epochs):
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
target_model = [DM_MODEL.unet, VAE_MODEL.vae]
with accelerator.accumulate(*target_model):
pixel_values = batch['pixel_values']
input_text_ids = batch['input_ids']
latents, reconstructed, posterior = VAE_MODEL(pixel_values)
model_pred, target, timesteps = DM_MODEL(latents.detach(), input_text_ids)
loss_DM = DM_Loss(model_pred, target, timesteps)
loss_VAE = VAE_Loss(pixel_values, reconstructed, posterior)
loss_All = loss_DM + loss_VAE
avg_loss = accelerator.gather(loss_All.repeat(train_batch_size)).mean()
train_loss += avg_loss.item()
# Backpropagate
accelerator.backward(loss_All)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(DM_MODEL.unet.parameters(), max_grad_norm)
accelerator.clip_grad_norm_(VAE_MODEL.vae.parameters(), max_grad_norm)
optimizer1.step()
optimizer2.step()
lr_scheduler1.step()
lr_scheduler2.step()
optimizer1.zero_grad()
optimizer2.zero_grad()
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
accelerator.log({
"train_loss": train_loss,
}, step=global_step)
train_loss = 0.0
logs = {"step_loss_DM": loss_DM.detach().item(),
"step_loss_VAE": loss_VAE.detach().item(),
"lr_DM": lr_scheduler.get_last_lr()[0],
}
progress_bar.set_postfix(**logs)
if global_step >= max_train_steps:
break
여태까지 진행한 방식은 아시다시피 Deepspeed ZeRo Stage-3에서는 불가한 방법입니다.
backward 두번시 에러
https://jh-bk.tistory.com/13
https://aigong.tistory.com/433
pyTorch multi loss
https://stackoverflow.com/questions/53994625/how-can-i-process-multi-loss-in-pytorch
deepspeed
https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed
https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
https://tkayyoo.tistory.com/193
multi model시
https://github.com/huggingface/accelerate/issues/668
'Developers 공간 [Basic] > Software Basic' 카테고리의 다른 글
| [PyTorch] Optimizer & LR Scheduler 정리 (0) | 2024.08.17 |
|---|---|
| [PyTorch] PyTorch Lightning 그리고 Distributed Computing (0) | 2024.08.17 |
| [Python] Multi-process와 Multi-thread 구현하기 (0) | 2024.01.21 |
| [Pytorch] Attention Layer 분석 및 구축하기 (0) | 2023.06.20 |
| [OOP] Design Pattern 정리 (0) | 2023.05.15 |