
2023. 12. 8. 15:53ㆍDevelopers 공간 [Basic]/Embedded
TensorRT(TRT)는 Nvidia에서 제공되는 Deep Learning Inference를 위한 SDK입니다.
PyTorch, Caffe, Tensorflow 등의 Deep Learning Framework를 활용해 학습된 모델을, 여러 플랫폼에 가장 적합한 Kernel을 선택하며, 각 제품 각 아키텍쳐에 맞는 가속을 자동으로 도와 최적의 GPU 자원을 활용해 Performance를 낼 수 있도록 도와주는 엔진이라고 볼 수 있습니다.
** Kernel : GPU에서 병렬 실행되는 명령의 모음
TensorRT를 이용하지 않고, 직접 CUDA 를 활용해 Custom한 로직으로 최적화할 수도 있으나, Nvidia에서 제공하는 API를 활용하는 것이 작업에 유용하기도 합니다.
이번엔 onnx파일을 활용해 TensorRT를 구동하는 방식을 설명하고자 합니다.
(해당 게시물은 c++로 TRT를 구현하는 게시물(https://tkayyoo.tistory.com/11) 이후에 작성되었으므로, 해당 게시물을 통해 기본적인 것을 이해한 후에 참조하는 것을 추천드립니다.)
<구성>
0. Background
a. 비교 선택
b. 환경 셋팅
c. PyTorch Model에서 Onnx 만들기
d. TRT파일 생성하기
1. 구현하기
a. 초기 셋팅
b. engine 만들기
c. Inference 하기
2. 기타 정보
a. trtexec 실행시 참고
b. Netron
c. OnnxSim
글효과 분류1 : 코드
글효과 분류2 : 폴더/파일
글효과 분류3 : 용어설명
글효과 분류4 : 글 내 참조
글효과 분류5 : 글 내 참조2
글효과 분류6 : 글 내 참조3
0. Background
TensorRT를 python으로 구현하기 전에 알아두어야 할 것들이 있어 챕터를 만들었습니다. python에는 TensorRT를 활용하기 위한 다양한 방법들이 있는데 이를 먼저 알아보고, 이를 활용하기 위해 미리 준비해야하는 것들을 살펴보겠습니다.
a. 비교 선택
python 에는 tensorRT를 활용하기 위한 다양한 방법들이 있습니다. 어떤 것이 다르고, 왜 필자는 Onnx를 통한 TensorRT 엔진을 구축하려고 하는지 살펴보겠습니다.
1. torch2trt(NVIDIA-AI-IOT)
PyTorch 함수들을 TensorRT로 변경해주는 라이브러리 입니다. TensorRT Python API를 활용하여 pytorch function을 tensorRT layer로 컴파일하며, 아래 소개할 TRTorch보다 더 많은 layer 지원이 됩니다. 보통 실험적인 시도를 하거나 prototype을 만들어 python으로 deploy할 때 적합합니다.
- 소스 : https://github.com/NVIDIA-AI-IOT/torch2trt
- 설치
- 설치에 앞서 아래 "b.환경셋팅 - 2. TensorRT설치하기"를 참조해 TensorRT를 설치해주어야 합니다.
- 아래와 같이 torch2trt를 설치해줍니다.
git clone https://github.com/NVIDIA-AI-IOT/torch2trt
cd torch2trt
python3 setup.py install- 사용법
먼저 torch2trt를 활용해 tensorRT로 변환하고 저장(Serialize)하는 방법입니다. 저장시에는 PyTorch와 동일하게 .pth를 활용합니다.
from torch2trt import torch2trt
model = MODEL()
input_samples = torch.ones((1,3,244,244)).cuda()
model_trt = torch2trt(
model,
[input_samples],
fp16_mode=True,
use_onnx=False
)
torch.save(model_trt.state_dict(), 'output.pth')
저장된 tensorRT변환 결과를 불러와(Deserialize) 다시 모델을 실행하는 방법입니다.
from torch2trt import TRTModule
model_trt = TRTModule()
model_trt.load_state_dict(torch.load('output.pth'))
x = torch.ones(1,3,224,224)).cuda()
output = model_trt(x)
2. Torch-TensorRT, TRTorch(NVIDIA)
Python dependency가 없는 stand-alone TorchScript 코드를 TensorRT로 컴파일하고 module안에 넣기 위해 사용하는 라이브러리 입니다. PyTorch가 JIT 런타임에 컴파일 하는 것과 다르게 AOT 방식으로 컴파일 하며, C++로 deploy 하기 위해서도 사용하는 경우가 많습니다.
** JIT (Just In Time) Compiler : 정적 컴파일러만큼 빠르면서 Interpreter 언어의 빠른 응답속도를 추가하기 위해 사용하는 컴파일러 입니다. Dynamic Translation이라고도 불리며, 실행하는 시점에 기계어로 번역하는 컴파일 기법입니다.
** AOT(Ahead Of Time) Compiler : 목표 시스템의 기계어와 무관하게, 중간 언어형태로 배포한 후, 해당 시스템에서 JIT Compiler 등의 번역을 통해 높은 성능을 달성하는 방법입니다.
** stand-alone : "독립적인 것"이라는 뜻으로, 다른 도움 없이 스스로 실행하기 위해 필요한 최소한의 코드를 의미합니다.
- 소스 : https://github.com/pytorch/TensorRT
- 설치
- 설치에 앞서 아래 "b.환경셋팅 - 2. TensorRT설치하기"를 참조해 TensorRT를 설치해주어야 합니다.
- 아래와 같이 torch-tensorrt를 설치해줍니다.
pip3 install torch-tensorrt- 사용법
먼저 TRTorch를 활용해 tensorRT로 변환하고 저장(Serialize)하는 방법입니다. torchscript를 저장할때는 .ts 혹은 .pt(.pth)로 저장합니다.
import torch_tensorrt
model=MODEL()
input_sample= torch_tensorrt.Input(
min_shape=[1, 3, 224, 224],
opt_shape=[1, 3, 512, 512],
max_shape=[1, 3, 1024, 1024],
dtype=torch.half
)
model_trt = torch_tensorrt.compile(
model,
inputs = [input_sample],
enabled_precisions = {torch.half, torch.float},
)
torch.jit.save(model_trt, "model.ts")
모델을 불러와(Deserialize) 실행하는 방법입니다.
model_trt = torch.jit.load("model.ts")
x = torch_tensorrt.Input(
min_shape=[1, 3, 224, 224],
opt_shape=[1, 3, 512, 512],
max_shape=[1, 3, 1024, 1024],
dtype=torch.half
)
x = x.to("cuda").half()
output = model_trt(x)
TorchScript에 대해서 모르시면 아래 더보기를 누르세요.
-------------------------------------------------------------------------
<TorchScript>
c++같은 고성능 환경에서 실행가능한 PyTorch모델의 중간표현(torch.nn.Module의 하위 클래스)입니다. Torch에서 런타임에 최적화를 수행하는 "Jit Compiler"에서 사용합니다.
아래는 TorchScript 형태로 만드는 과정과 저장하는 방법이며, .pt 혹은 .ts 형태로 저장합니다.
model = MODEL()
model_scripted = torch.jit.script(model)
torch.jit.save(
model_scripted
"model.pt"
)
이를 불러와 사용하는 예시 코드입니다.
model_scripted = torch.jit.load('model.pt')
x = torch.rand(1, 3, 224, 224)
output = model_scripted(x)-------------------------------------------------------------------------
기본적으로 jit은 PyTorch 코드를 최적화해 operation들을 merge시키는 front-end 코드라고 볼 수 있지만, TensorRT는 Nvidia GPU에 맞게 operation들을 fuse하고 kernel call을 줄이는 back-end 코드라고 볼 수 있습니다.
위 두 방법 모두 TensorRT를 사용해 backend를 최적화하는 두가지 방법이기 때문에, 필자가 이 글에서 설명할 내용과 같이 직접적으로 Onnx으로 parsing한 다음에 엔진을 구성하는 것보다 위와 같이 간단하게 Serving을 진행하는 방법을 선호하는 분들도 있습니다.
하지만 위 방법은 기본적으로 PyTorch를 활용하는 방법이며, PyTorch에서 GPU를 활용하는 경우 memory allocator가 미리 넉넉하게 메모리를 선점한 후, 자체적으로 메모리 관리 하기 때문에 메모리가 가장 최적화 되었다고 할 수 는 없습니다. 또한 위 라이브러리의 경우 지원되지 않는 layer가 부족한 경우도 발생합니다.
따라서 필자는 이어서 TensorRT 엔진을 직접 구성해 구현하는 방법을 소개하겠습니다.
b. 환경 셋팅
Onnx를 Parsing하고 TensorRT 엔진을 구축하기 위해 미리 설치해야하는 환경셋팅에 대해 설명하겠습니다.
1. Python 패키지 설치
pycuda는 c++에서의 CUDA와 같이 메모리를 allocation하고 관리하기 위한 패키지이며, TensorRT 엔진과 함께 예시에서 사용하기 위해 설치합니다.
pip3 install --upgrade pip
pip3 install pycuda
2. TensorRT 설치하기
먼저, 시스템에 TensorRT를 설치합니다. 해당 링크(https://developer.nvidia.com/nvidia-tensorrt-download)에서 원하는 버전의 TensorRT를 다운로드 받은뒤 아래와 같이 직접 라이브러리를 위치시켜 설치합니다.
** TensorRT 버전 선택에 대해 알고 싶다면, 이전 글(https://tkayyoo.tistory.com/17#tktag8)을 참조하세요.
# Get source from Nvidia page
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/8.6.1/tars/TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-12.0.tar.gz
tar xvf TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-12.0.tar.gz
cd {DownloadFolder}
# Set TensorRT library in system
cp -r {DownloadFolder}/targets/x86_64-linux-gnu/include/* /usr/local/cuda/targets/x86_64-linux/include/
cp -r {DownloadFolder}/targets/x86_64-linux-gnu/lib/* /usr/local/cuda/targets/x86_64-linux/lib/
cp -r {DownloadFolder}/targets/x86_64-linux-gnu/bin/* /usr/loca/bin/
echo "export LD_LIBRARY_PATH=/usr/local/cuda/lib64:/usr/local/cuda/targets/x86_64-linux/lib:\$LD_LIBRARY_PATH" >> ~/.bashrc"
다운 받은 해당 폴더 안에는 python에서 필요한 패키지들도 있습니다. 이를 아래와 같이 직접 설치합니다.
pip3 install {DownloadFolder}/python/tensorrt-8.6.1-cp38-none-linux_x86_64.whl
pip3 install {DownloadFolder}/onnx_graphsurgeon/onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl
해당 다운로드 폴더에는 uff와 graphsurgeon이라는 것들이 있는데, 이는 설치하지 않았습니다. 이들이 왜 존재하는지 알고 싶다면 아래 더보기를 참조하세요.
-------------------------------------------------------------------
<UFF 와 graphsurgeon>
PyTorch는 ONNX로 변환을 해 주로 활용하지만, Tensorflow의 경우는 UFF 혹은 ONNX로 변환해 진행할 수 있습니다. 위에서 설치한 onnx-graphsurgeon의 경우 onnx graph를 만들어내기 위한 툴인데, graphsurgeon의 경우는 Tensorflow graph를 다루기 위한 툴입니다.
예를 들어 tensorflow의 경우를 아래와 같이 살펴보겠습니다.
tensorflow모델 저장은 .ckpt(가중치)형태로 저장됩니다. 정확히는 아래와 같습니다.
model = MODEL()
model.save_weights("MODEL.ckpt")- MODEL.ckpt.index : 아래 두 파일을 매핑 시키기 위한 인덱스 파일입니다.
- MODEL.ckpt.data-00000-of-00001 : 모델의 파라미터를 포함합니다.
- MODEL.ckpt.meta : 모델의 구조 등 메타 정보들을 포함합니다.
혹은 keras를 활용해 SavedModel형태로 저장할 수도 있는데, 아래와 같이 구현할 수 있으며 결과물은 아래와 같습니다.
model = MODEL()
model.save('saved_model/my_model')- fingerprint.pb
- keras_metadata.pb
- saved_model.pb : 가장 중요한 파일로, protobuf형태로 저장됩니다.
** .pb(바이너리 파일 형태) 와 .pbtxt(텍스트 파일 형태)의 차이는 파일 형태의 차이이며, pbtxt가 편집이나 디버깅에 유리하기 때문에 사용하기도 하지만, deploy하기에는 용량이 큽니다. - assets : Tensorflow Graph에서 사용되는 텍스트 파일들이 저장되어있습니다.
- variables : 위의 .ckpt.data와 .ckpt.index 가 저장되어 있습니다.
이렇게 생성된 protobuf 파일(.pb)을 convert-to-uff라는 패키지를 통해 uff로 바꾸고, TensorRT에서 활용하기 위해서는 uff, graphsurgeon도 설치를 해야합니다.
이를 위해 tensorRT 설치 폴더에는 이 두가지를 설치하는 내용도 포함되어 있습니다.
1. UFF(Universal Framework Format)
위 설치 폴더 내에서 uff를 설치하는 방법은 아래와 같습니다.
pip3 install {DownloadFolder}/uff/uff-0.6.9-py2.py3-none-any.whl
.pb 파일을 통해 만들어낸 uff 파일을 TensorRT에서 활용하는 예시는 아래와 같습니다.
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network()
parser = trt.UffParser()
parser.register_input("input", (B, H, W, C))
parser.register_output("output")
parser.parse("frozen.uff", network)
2. graphsurgeon
graphsurgeon은 아래와 같이 설치할 수 있습니다.
pip3 install {DownloadFolder}/graphsurgeon/graphsurgeon-0.4.6-py2.py3-none-any.whl
pip3 install {DownloadFolder}/onnx_graphsurgeon/onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl
추가로 tensorflow는 TF-TRT(Tensorflow-TensorRT)라는 것도 있는데, 이는 Tensorflow에 내장되어있는 TensorRT라고 보시면됩니다.
-------------------------------------------------------------------
c. PyTorch Model에서 Onnx 만들기
우리가 구현한 PyTorch 모델을 Onnx로 저장하는 방법에 대해 설명하겠습니다.
해당 내용은 앞서 언급한 이전 글(https://tkayyoo.tistory.com/11)에 더 자세히 설명이 되으니, 이번 글에서는 간단히 구현 결과만 소개하도록 하겠습니다.
먼저, PyTorch를 활용해 어떤 모델을 .pth 혹은 .ckpt 형태로 저장했을 것입니다. 혹시나 저장하는 방법을 모른다면 아래 더보기를 클릭하시길 바랍니다.
--------------------------------------------------------------------
<Torch 모델 저장하는 방법 정리>
1-1. save
state_dict는 모델의 학습 가능한 parameter(weight, bias)를 저장하는 python dict 객체입니다. 아래 방법은 기본적으로 모델의 state_dict만을 저장하고 불러오는 방법이며, PyTorch에서 저장하는 모델(Serialized Model)은 pickle형태이며 .pt 혹은 .pth 을 사용합니다.
model = MODEL()
torch.save(model.state_dict(),PATH)
1-2. load
model =MODEL()
model.load_state_dict(torch.load(PATH))
2-1. save
또다른 방법으로 state_dict를 포함한 checkpoint를 저장하는 방법이 있습니다. checkpoint는 위에 저장한 state_dict외에도 학습시 사용하는 optimizer 혹은 epoch, loss 등을 함께 저장하는데 사용하며, PyTorch에서 저장하는 체크포인트는 .tar 혹은 .ckpt를 사용합니다.
model =MODEL()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
torch.save(
{‘epoch’:5,
‘model_state_dict’:model.state_dict(),
‘optimizer_state_dict’:optimizer,
‘loss’:0.4
}
, PATH)
2-2. load
model = MODEL()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint[‘model_state_dict’])
optimizer.load_state_dict(checkpoint[‘optimizer_state_dict’])
--------------------------------------------------------------------
설명에 앞서, 필자는 아래와 같이 모델의 경로를 활용해 onnx와 trt 파일의 경로를 먼저 만들어 주었습니다.
self.model_name = os.path.splitext(os.path.basename(model_path))[0]
self.onnx_path = '/'.join(model_path.split('/')[:-1] + [self.model_name + '.onnx'])
self.trt_path = '/'.join(model_path.split('/')[:-1] + [self.model_name + '.trt'])
또한 아래 함수가 바로 해당 모델을 onnx로 변경하는 함수입니다.
import onnx
def _ParseToOnnx(self, onnx_path):
model = MODEL()
inputa = torch.randn((500), dtype=torch.float32, device=self.map_location)
inputb = torch.full((2,2), dtype=torch.int32, device=self.map_location)
kwargs_packed={"input1":inputa, "input2":inputb}
torch.onnx.export(
model,
kwargs_packed,
onnx_path,
export_params=True,
verbose=True,
input_names =['in1', 'in2'],
output_names=['out1', 'out2']
)
if not os.path.isfile(onnx_path):
raise Exception("[Error] : {}".format(onnx_path))
else:
temp_model = onnx.load(onnx_path)
opset_version = temp_model.opset_import[0].version if len(temp_model.opset_import) > 0 else None
print("Opset of Onnx Version : {}".format(opset_version))
onnx로 export하기 위한 모델을 다른 형태로 변경하는 방법이 궁금하다면 아래 더보기를 참조하세요.
--------------------------------------------------------------------
<기존 저장된 모델을 바꾸기>
이미 모델이 만들어진 경우, 모델의 input 혹은 output을 바꾸거나 추가적으로 layer를 추가하고 싶은 경우가 있습니다.
또는 onnx로 변경하는 경우 모델을 만들 때, 아래와 같이 forward()함수가 정의 된 torch.nn.Module을 상속해 아래와 같이 정의하게 되는데, 함수로 정의된 어떤 내용을 onnx로 만들고 싶다면 어떻게 해야할까요? 아래와 같은 모델이 있다고 가정합시다.
class MODEL(nn.Module):
def __init__(self):
super(MODEL, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
이런 경우 아래와 같이 새로운 모델을 정의해 활용할 수 있습니다.
class DIFFERENT_MODEL(torch.nn.Module):
def __init__(self, object):
super().__init__()
self.object = object
def forward(self, i1, i2)
return self.object.function(i1, i2)
model = MODEL()
different_model = DIFFERENT_MODEL(model)--------------------------------------------------------------------
d. TRT파일 생성하기
생성된 .onnx파일을 활용해 .trt파일을 만들어 보겠습니다.
TensorRT 라이브러리를 설치하고 나면 trtexec 명령어를 통해 .onnx에서 .trt파일을 생성할 수 있는데, 이 명령어를 그냥 활용해 bash에서 실행하듯이 구현했습니다.
def _ParseToTRT(self, trt_path):
command = ['trtexec']
kwargs = {'onnx' : self.onnx_path, 'saveEngine' : trt_path}
kwargs['best'] = None
kwargs['fp16'] = None
kwargs['sparsity'] = "enable"
kwargs['allowGPUFallback'] = None
kwargs['profilingVerbosity'] = "detailed"
kwargs['tacticSources'] = "-EDGE_MASK_CONVOLUTIONS,-CUBLAS_LT,-JIT_CONVOLUTIONS"
kwargs['noTF32'] = None
kwargs['memPoolSize'] = "workspace:256MB"
kwargs['verbose'] = None
args = command + convert_kargs_to_cmd_line_args(kwargs, with_dash=True)
os.system(" ".join(args))
if not os.path.isfile(trt_path):
raise Exception("TRT File has been successfully created : {}".format(trt_path))** 위에서 활용한 convert_kargs_to_cmd_line_args() 함수는 단순히 dictionary를 --A=B 혹은 --A 형태로 만들어 주는 함수로, 혹시 참조하고 싶다면 더보기를 참조하세요.
-------------------------------------------------------------
<convert_kargs_to_cmd_line_args 함수>
아래와 같이 구현했습니다.
def convert_kwargs_to_cmd_line_args(kwargs, with_dash=False):
import collections
args=[]
for k in sorted(kwargs.keys()):
v = kwargs[k]
if isinstance(v, collections.Iterable) and not isinstance(v,str) :
for value in v:
if with_dash:
if value is not None:
args.append('--{}={}'.format(k, value))
else:
args.append('--{}'.format(k))
else:
args.append('-{}'.format(k))
if value is not None:
args.append('{}'.format(value))
if with_dash:
if v is not None:
args.append('--{}={}'.format(k,v))
else :
args.append('--{}'.format(k))
else:
args.append('-{}'.format(k))
if v is not None:
args.append('{}'.format(v))
return args
-------------------------------------------------------------
1. 구현하기
자 이제 .trt 파일을 만들었으니 엔진을 구성해 구현해보겠습니다. 먼저, 필자가 만든 Class의 형태를 먼저 소개하고, 엔진에 필요한 것들을 하나씩 소개하겠습니다. 이전 글(https://tkayyoo.tistory.com/11)을 참조하면 자세히 알 수 있지만, python에 겹치는 부분에 있어서는 다시 한번씩 이야기하도록 하겠습니다.
a. 초기 셋팅
TensorRT를 구현함에 앞서서 구현하는 Class의 형태를 보이겠습니다. 아래와 같이 Class로 구현했으며 아래 내용 중 _ParseToOnnx(), _ParseToTRT() 함수는 앞서 설명드렸습니다.
이번 챕터 에서는 _SettingTRTEngine() 함수와 _ProcessTRT()함수를 자세히 설명하겠습니다.
아래 내용 중 _ProcessInput()과 _ProcessPost() 함수는 일반적으로 필요한 pre-processing과 post-processing을 의미하기 때문에 추가적인 설명은 하지 않도록 하겠습니다.
class TRTExample:
def __init__(self, model_path):
# ===================Setting Device======================
self.device = 1 if ngpu==0 else [5]
self.accelerator = 'cpu' if ngpu==0 else 'gpu'
self.map_location = torch.device('cuda:{}'.format(self.device[0]) if self.accelerator=='gpu' else 'cpu')
# When use TensorRT with CUDA memory
os.environ['CUDA_MODULE_LOADING']='LAZY'
# ===================Setting Model======================
self.asr_model = SOMEMODEL(model_path)
# ===================Parsing Files======================
self._ParseToOnnx(model, onnx_path);
self._ParseToTRT(trt_path);
# ===================Setting Engine======================
self.input_bindings = {}
self.output_bindings ={}
self.gpu_allocations =[]
self.engine = None;
self.context = None;
self.cuda_ctx = None
self._SettingTRTEngine()
# ====================================================
def _ParseToOnnx(self, model, onnx_path):
pass
def _ParseToTRT(self, trt_path):
pass
def _SettingTRTEngine(self):
pass
def __del__(self):
if len(self.input_bindings) != 0 :
for k2,v2 in v.items() :
del v2
del self.input_bindings
if len(self.output_bindings) != 0 :
for k2,v2 in v.items() :
del v2
del self.output_bindings
del self.gpu_allocations
if self.context:
del self.context
if self.engine:
del self.engine
def __call__(self, file_path):
processed1, processed2 = self._ProcessInput(file_path, from_file=True)
processed3, processed4 = self._ProcessTRT(processed1, processed2)
result = self._ProcessPost(processed3, processed4)
return result
def _ProcessInput(self, file_path, from_file=True):
pass
def _ProcessTRT(self, processed1, processed2):
pass
def _ProcessPost(self, processed3, processed4):
pass
Setting Device
- 단순히 GPU device의 개수나 어떤 GPU를 활용할 것인지 셋팅하는 방법입니다.
- Lazy Loading 의 필요성 : os.environ['CUDA_MODULE_LOADING'] = 'LAZY'
- TensorRT를 활용시 CUDA 메모리를 allocation하고 실행하게 되면 아래와 같은 Warning 메시지가 나올 것입니다.
- Lazy Loading이란 CUDA 커널과 모듈을 로딩하는 것을 초기화과정에 하지 않고, Kernel Execution시 에 해주는 방법입니다. 프로그램이 모든 커널을 매번 사용하는 것이 아니라면 매번 로딩할 필요가 없으므로, 필요한 커널만을 로딩해 초기화 시간을 줄이는 방법입니다.
- 이를 해주지 않으면 GPU와 Host의 Memory overhead가 크므로, TensorRT에서 CUDA를 함께 사용하는 경우 Lazy Loading을 하도록 설정해주는 것이 좋습니다.
[TRT] [W] CUDA lay loading is not enabled. Enabling it can significantly reduce device memory usage and speed up TensorRT initialization. See “Lazy Loading” section of CUDA documentation
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#lazy-loading
Setting Model
각자 개인적인 방법으로 모델을 만듭니다.
Parsing Files
기존 모델을 활용해 .onnx와 .trt를 만드는 방법입니다. 이는 앞서 설명드렸습니다.
Setting Engine
TensorRT 엔진을 실행하기 위해 엔진을 구성하는 방법입니다. 다음챕터에서 소개하도록 하겠습니다.
b. engine 만들기
TRT Engine을 만드는 내용에 대해 설명하겠습니다. 역시나 이전 글(https://tkayyoo.tistory.com/11#tktag5)에 engine과 context와 관련해 자세히 설명되어 있으며, python은 object를 따로 미리 만들어주지 않아도 되므로 이전 글에서의 내용 중 IN3_Deserialize 부터 설명하는 것이라고 생각하시면 될 것 같습니다.
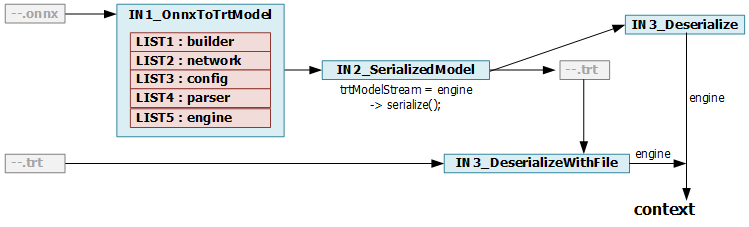
먼저, 아래 처럼 Engine을 구성했습니다.
import tensorrt as trt
import pycuda.driver as cuda
cuda.init()
def _SettingTRTEngine(self):
if trt.__version__[0] < '8':
raise Exception("[TK][Error] our model has been tested on TensorRT version 8.6.1.6 : {}".format(trt.__version__))
self.trt_logger = trt.Logger(trt.Logger.WARNING)
# STEP1
runtime = trt.Runtime(self.trt_logger)
# STEP2
trt.init_libnvinfer_plugins(None,"")
self._SettingTRTEngine_GetEngine(self.trt_path, runtime)
- STEP1. runtime : runtime : driver API를사용하게 해주는 wrapper 혹은 helper입니다.
- STEP2. libinver_plugins() : TensorRT plugin을 사용하기 위해 초기화해줍니다.
다음으로 이제 구체적으로 _SettingTRTEngine_GetEngine()을 활용해 실제 구현을 하게 되는데 내용은 아래와 같습니다.
def _SettingTRTEngine_GetEngine(self, trt_path, runtime, from_Tensor=True, to_Tensor=True):
# STEP0
cuda_ctx = cuda.Device(self.device[0]).make_context()
# STEP1
with open(trt_path, 'rb') as f:
engine = runtime.deserialize_cuda_engine(f.read())
# STEP2
context = engine.create_execution_context()
assert engine
assert context
gpu_allocations = []
input_bindings = {}
output_bindings = {}
for i in range(engine.num_bindings):
dtype = np.dtype(trt.nptype(engine.get_binding_dtype(i)))
name = engine.get_binding_name(i)
shape = context.get_binding_shape(i)
is_input = engine.binding_is_input(i)
size_count = dtype.itemsize
for s in shape:
size_count *= s
if is_input and shape[0]<0:
assert engine.num_optimization_profiles > 0
profile_shape = engine.get_profile_shape(0,name)
assert len(profile_shape) ==3 # min, opt, max
context.set_binding_shape(i, profile_shape[2]) # max
# STEP3-1
if is_input:
if not from_Tensor:
allocation = cuda.mem_alloc(size_count)
else:
allocation = None
host_allocation = None
else:
if not to_Tensor:
allocation = cuda.mem_alloc(size_count)
else:
allocation = torch.empty(size=tuple(shape), dtype=getattr(torch, str(dtype)), device=self.map_location)
host_allocation = None
# host_allocation = cuda.pagelocked_empty(trt.volume(engine.get_binding_shape(i)),dtype) * engine.max_batch_size
# host_allocation = np.zeros(shape, dtype)
# STEP3-2
binding = {
"index" : i,
"name" : name,
"dtype" : dtype,
"shape" : list(shape),
"size" : size_count
"allocation" : allocation,
"host_allocation" : host_allocation
}
# STEP3-3
if is_input:
if not from_Tensor:
gpu_allocations.append(int(allocation))
else:
gpu_allocations.append(None)
input_bindings[name] = binding
else:
if not to_Tensor:
gpu_allocations.append(int(allocation))
else:
gpu_allocations.append(allocation.data_ptr())
output_bindings[name] = binding
cuda_ctx.pop()
self.cuda_ctx, self,engine, self.context, self.input_bindings, self.output_bindings, self.gpu_allocations = \
cuda_ctx, engine, context, input_bindings, output_bindings, gpu_allocations
- STEP0 : pyCuda context를 open 합니다.
- context란? : driver안에는 여러개 stack이 만들어지고, 이들은 각각 device를사용하기 위한 (allocated memory 리스트, loaded module, CPU-GPU간의 메모리 매핑)을 가지고 있습니다. 이들은 context라 부릅니다.
- context를 open하는 방법 세가지
- import pycuda.autoinit
** import pycuda.driver as cuda; cuda.init()을 하면 context를 할당하지는 않습니다. - cfx = cuda.Device(0).make_context()
- cfx.push() : open 하는 경우 각각 cfx.pop()해줘야한다
- ctx.push() : context stack에 자기자신을 active context 로 올리는 것
- ctx.pop() : context stack가장 위에 것을 지워버리는 것
- import pycuda.autoinit
- (중요) context = engine.create_execution_context() 명령어로 선언한 TensorRT의 context는 pyCuda의 context와 다릅니다.
기존에 C++에서 TensorRT를 구현할 때 engine, context, stream라는 개념이 있었는데 stream개념은 보이지 않는 것을 알 수 있습니다. 이때 stream은 memcpy등의 명령어를 활용하는 것으로 대체되었고, 이들은 pyCuda의 context가 있어야만 동작합니다. - (중요) PyTorch 또한 pyCuda를 활용해 memory를 allocation/free합니다.
- (중요) TensorRT와 함께 사용하는 경우, 여러개의 TensorRT 수행 Thread가 있더라도 memcpy등에서 활용되는 pyCuda context는 한번만 선언해서 공유해도 상관없습니다. 하나의 pyCuda context를 활용해 memcpy하는 것입니다.
또한 pyCuda context를 매번 만들어주는 순간 python에서는 메모리를 pre-allocation합니다. 따라서 pyCuda context를 쓸데 없이 많이 만드는 것보다 하나를 만들어 공유해서 사용하는 것이 좋습니다.
- STEP1 : 기존의 trt파일을 불러와 deserialize하고 engine을 구성합니다.
- '네트워크 정의'와 '학습된 파라미터'들이 정의된 엔진입니다.
- 엔진은 작업이 끝날 때까지 반납되어서는 안됩니다.
- STEP2 : engine을 활용해 context를 구성합니다. 앞의 pyCuda와는 다르게 TensorRT에서 활용하는 Context라고 생각하시면 됩니다.
- STEP3-1 : GPU Inference 엔진의 input으로 torch Tensor를 활용할지, pyCuda 메모리를 활용할지에 따라 allocation을 진행합니다.
- torch Tensor를 활용: torch를 활용해 변수를 선언해 넣어주며, map_location을 통해 gpu에 위치시켜줍니다.
(input인 경우 메모리를 따로 할당하지 않은 이유는 어차피 외부 Tensor를 가지고 할당하게 될 확률이 높기 때문입니다.) - pyCuda 메모리를 활용 : cuda.mem_alloc()함수를 사용합니다.
- host memory를 따로 만들어주지 않은 이유는, 실행과정에서 직접만들어 사용하기 위함입니다.
- torch Tensor를 활용: torch를 활용해 변수를 선언해 넣어주며, map_location을 통해 gpu에 위치시켜줍니다.
- STEP3-2 : gpu 메모리에 대한 메타 정보와 실제 메모리들을 한데 모아 담아 둡니다.
- STEP3-3 : gpu에 실제로 allocation된 메모리들의 "주소"들만 담아둡니다. 당연히 STEP3-2에서 만든 binding을 활용해 찾을 수도 있지만, 연산시 편의성을 위해 따로 저장해 두는 것입니다. 위 STEP3-1에서의 다른 두 방법에 따라 주소를 담는 방법이 다릅니다.
- torch Tensor를 활용: data_ptr()를 활용해 주소로 만들어줍니다.
- pyCuda 메모리를 활용 : int()를 활용해 주소형태로 바꿔줍니다.
- (주의점) 이유는 확실히 모르겠지만, 두 경우 모두 메모리 주소로만 객체를 관리를 하면 아마 정상적으로 작동하지 않을 것입니다.
예상하는 이유로는 smart pointer로 구현이 되어있고, 사실상 data_ptr()이나 int()로 바꿔 관리하면 해당 메모리를 참조하고 있는지 모르기 때문에 반납되지 않을까 싶습니다.
따라서, 해당 주소외에 실제 메모리에 대한 정보를 꼭 담아서 관리해두어야 합니다.
c. Inference 하기
엔진을 구성하고, 필요한 메모리들을 allocation, 했으니 Inference를 진행하겠습니다.
Inference를 하는 방법에 있어 synchronized 방법과 async 방법 두가지가 있는데, 일반적인 synchronized 방법을 소개하겠습니다. 위에서 input과 output을 allocation 시에 torch Tensor를 활용했는지, pyCuda 메모리를 활용했는지에 따라 실행하는 방법이 달라집니다. 모든 방법을 정리해보겠습니다.
Case1. Input(Tensor) → Output(Tensor) 인 경우
torch Tensor를 활용해 input으로 allocation하고, torch Tensor를 output으로 받아 사용하는 경우입니다.
input은 allocation하지 않았으므로 기존에 있던 Tensor의 주소를 통해 gpu_allocations 리스트를 새로 만들어 excecute_v2() 함수에 넣어주었습니다.
execute_v2()는 GPU 커널을 수행시키는 명령어입니다.
역시나 pyCuda의 context를 앞뒤로 push(), pop()해주어야 함을 명심합니다.
def _ProcessTRT(self, processed1, processed2):
self.cuda_ctx.push()
# from_Tensor == torch Tensor
processed_togo1 = processed1.data_ptr()
processed_togo2 = processed2.data_ptr()
gpu_allocations = [processed_togo1, processed_togo2, self.gpu_allocations[2], self.gpu_allocation[3]]
self.context.execute_v2(gpu_allocations)
processed3 = self.output_binding[0]['allocation'].cpu()
processed4 = self.output_binding[1]['allocation'].cpu().long()
self.cuda_ctx.pop()
Case2. Input(CUDA) → Output(CUDA) 인 경우
pyCuda 메모리에 복사해준뒤에, 연산 후 pyCuda 메모리에서 정보를 얻어내는 방법입니다.
host에서 device로 복사하기 위해 cuda.memcpy_htod() 함수를 사용하며, device에서 host로 복사해오기 위해서는 cuda.memcpy_dtoh() 함수를 사용합니다.
기존의 메모리 주소 그대로 실행할 수 있으므로, 미리 만들어 둔 주소리스트를 그대로 excecute_v2() 함수에 넣어주었습니다.
def _ProcessTRT(self, processed1, processed2):
self.cuda_ctx.push()
# Unnecessary
processed_togo1 = processed1.cpu().numpy()
processed_togo2 = processed2.cpu().numpy().astype(np.int32)
# <-----------------------
cuda.memcpy_htod(self.input_bindings[0]['allocation'], processed_togo1)
cuda.memcpy_htod(self.input_bindings[1]['allocation'], processed_togo2)
self.context.execute_v2(bindings=self.gpu_allocations)
processed3_container = np.zeros(self.output_bindings[2]['shape'], dtype=np.float32)
processed4_container = np.zeros(self.output_bindings[3]['shape'], dtype=np.float32)
# <-----------------------
cuda.memcpy_dtoh(processed3_container, self.output_bindings[2]['allocation'])
cuda.memcpy_dtoh(processed4_container, self.output_bindings[3]['allocation'])
self.cuda_ctx.pop()
Case3. Input(CUDA) → Output(CUDA_other_device) 인 경우
Case2와 다르게 결과가 다른 연산에 사용하기 위해, 다른 위치의 device로 옮기는 경우 입니다.
host로 복사해 와서 사용하지 않고 다른 연산에 사용할 것이므로, cuda.memcpy_dtod()를 활용해 다른 위치로 복사해주었습니다.
def _ProcessTRT(self, processed1, processed2):
self.cuda_ctx.push()
processed_togo1 = processed1.cpu().numpy()
processed_togo2 = processed2.cpu().numpy().astype(np.int32)
# <-----------------------
cuda.memcpy_htod(self.input_bindings[0]['allocation'], processed_togo1)
cuda.memcpy_htod(self.input_bindings[1]['allocation'], processed_togo2)
self.context.execute_v2(bindings=self.gpu_allocations)
processed3_size = self.output_bindings[0]['size']
processed4_size = self.output_bindings[1]['size']
processed3_allocation = cuda.mem_alloc(size1)
processed4_allocation = cuda.mem_alloc(size2)
# <-----------------------
cuda.memcpy_dtod(processed3_allocation, self.output_bindings[2]['allocation'], processed3_size)
cuda.memcpy_dtod(processed4_allocation, self.output_bindings[3]['allocation'], processed4_size)
self.cuda_ctx.pop()
** (중요) cuda_ctx를 연산 앞뒤에 push()로 만들어주고 pop()으로 해제시켜주고 있는데, 이렇게 수행시간 기준으로 앞뒤에 추가해주어 context 수를 잘 관리해주어야 나중에 context가 무제한으로 늘어나는 것을 막을 수 있습니다.
2. 기타 정보
위에 설명된 정보 이외에 따로 참조하면 좋을 것 같은 내용을 정리해보았습니다.
a. trtexec 실행시 참고
앞서 TensorRT를 설치할 때 존재하는 바이너리인 trtexec을 활용해 .onnx파일을 .trt파일로 변환해주었다고 말씀드렸습니다. 이를 활용할 때 참조할 점에 대해서 설명하겠습니다.
1. 보기 힘든 옵션
- —workspace=1024, —memPoolSize=worksize:1024MB : scratch memory space를 의미하며 필수 weight, activation pre-computed data를 빼고 의미합니다.
(default : TRT8.2에서는16MB, TRT8.4+에서는 무한)
** persistent memory : layer 구현에 필요한 메모리입니다. (예를들어, convolution의 edge mask는 weight처럼 persistent memory에 유지) execution context를생성할 때 allocate 되며 lifetime을 함께 합니다.
** scratch memory : 중간 activation tensor 등에 사용되는 메모리입니다. - —tacticSoureces=-CUDNN,+CUBLAS : Tactic Sources 중에 어떤 것을 사용할지 선택하는 명령어 입니다. 특히 CUDNN, CUBLAS는 많은 device memory를 차지한다.
(default : 모든 tactic sources를 활용)- Tactic Sources : 최적화 하기 위해 사용하는 전략적 라이브러리 들의 목록을 의미합니다. CUBLAS, CUBLAS_LT, CUDNN, EDGE_MASK_CONVOLUTIONS, JIT_CONVOLUTIONS가 있습니다.
- CUBLAS_LT : x86 platform에서만활성화되며, non-x86에서는 CUDA 11.0보다 클때만 enable됩니다. 아시다시피 CUBLAS는 GEMM연산을 input에 유연하게 사용하기 위한 API입니다.
- EDGE_MASK_CONVOLUTIONS : 메모리를 더 쓰면서 빠르게 적용합니다.
- JIT_CONVOLUTIONS : engine building time이늘어납니다.
2. TRT verbose 결과 메시지 분석
- [MemUsageChange] Init CUDA: CPU+2, GPU +0, now : CPU 19, GPU 104(MiB)
- 처음 Cuda 초기화 끝내고 났을 때 메모리 변화
- [MemUsageChange] Init builder kernel library : CPU+889, GPU +174, now : CPU 984, GPU 278(MiB)
- 커널 라이브러리 사용하고 났을 때 메모리 변화
- Detected 3 inputs and 3 output network tensors
Total Host Persistent memory : 32
Total Device Persistent Memory : 0
Total Scratch Memory : 12288
- execution context에 의해 사용되고 & builder에 의해 발생되는 메모리이다. 단위는 Bytes입니다.
- [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators : CPU 83 MiB, GPU 167MiB
- Total Activation Memory : 30720
- …
- [MemUsageChange] TensorRT-managed allocation in building engine : CPU +0, GPU +64, now: CPU 0, GPU 64 (MiB)
- Loaded engine size : 41 MiB
- [MemUsageChange] TensorRT-managed allocation in engine deserialization : CPU +0, GPU +41, now: CPU 0, GPU 41 (MiB)
- 모델의 weight를 저장하는 단계
- [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation : CPU +0, GPU +64, now: CPU 0, GPU 41 (MiB)
b. Netron
Netron이란 그래프 형태로 만들어진 ONNX, TensorFlow Lite, Core ML, Keras, Caffe, Darknet, MXNet, PaddlePaddle, ncnn, MNN and TensorFlow.js 등을 시각화 해서 보기 위한 뷰어입니다. 공식 링크(https://github.com/lutzroeder/netron)를 통해 확인할 수 있으며, 이글의 경우에서는 onnx파일의 결과를 확인하기 위해서도 유용하게 사용됩니다.
설치는 아래와 같습니다.
pip3 install netron
실행은 아래와 같이 합니다. default로 8080포트로 열리며, docker 내부에서 실행하는 경우 host를 연결해주어야 외부 포트로 연결이 됩니다.
# Execution
netron ~/workspace/abc.onnx
# In Docker
netron ~/workspace/abc.onnx —host 0.0.0.0
c. OnnxSim
Onnx-simplifier란 불필요한 operator을 대체하거나 constant folding 같이 상수를 제거해주며 전체 computation graph를 최적화하는 방법입니다. 해당 페이지(https://github.com/daquexian/onnx-simplifier)를 참조하면 자세히 설명이 되어있습니다.
설치는 아래와 같습니다.
pip3 install onnxsim
방법1. 위와 같이 설치하면 아래처럼 bash에서 실행해 직접 변경할 수 있습니다.
onnxsim FROM.onnx TO.onnx
방법2. python 코드 내에서 실행하는 방법이지만, bash에서 실행하는 것과 같습니다.
args = "onnxsim {} {}".format(from, to)
os.system(args)
방법3. onnxsim 라이브러리를 import해서 직접 구현해보는 방법입니다.
import onnx
import onnxsim
temp_onnx = onnx.load(from)
model_simp, check = onnxsim.simplify(temp_onnx)
onnx.save(model_simp, to)
if not check:
raise Exception("ERROR")

https://github.com/pytorch/TensorRT/issues/34
https://zerohertz.github.io/how-to-convert-a-pytorch-model-to-tensorrt/
'Developers 공간 [Basic] > Embedded' 카테고리의 다른 글
| [Nvidia] OpenCL 기초 문법 및 병렬처리 관련 정리 (2) | 2022.12.31 |
|---|---|
| [Nvidia] TensorRT 구현하기 (C++) (10) | 2022.12.21 |
| [Nvidia] Nsight System 셋팅 (0) | 2022.12.21 |