
[Nvidia] Nsight System 셋팅
2022. 12. 21. 00:48ㆍDevelopers 공간 [Basic]/Embedded
728x90
반응형
이번엔 학습한 네트워크가 CPU 및 Nvidia GPU에서 실행될 때 Profiling하기 위한 Tool 중 Nsight System을 소개하려고합니다.
Nvidia에서 제공하는 Profiling Tool은 Nsight System, Nsight Compute, Nsight Graphics 그리고 TREx가 있습니다.
- Nsight System : 시스템 적으로 CPU, GPU간 이동 및 수행시간등을 Profiling하기 위한 툴. 보통 Memory bound ~ Computation Bound간의 최적화를 위해 사용합니다.
- Nsight Compute : CUDA kernel 내부를 자세하게 Profiling하기 위한 툴. 보통 네트워크 Layer별로 성능을 분석하고, 과하게 사용되고 있는 Memory Resource나 Computation Resource들을 파악하는데 사용합니다.
- Nsight Graphics : 그래픽과 관련된 것을 Profiling하기 위한 툴
- TensorRT Engine Explorer (TREx) : 파이썬 라이브러리로, TensorRT 엔진의 inference정보를 Profiling하기 위한 툴
이번에 소개할 Nsight System은 네트워크를 개발하고 가장 먼저 시스템 상에서 분석하기 위해 주로 사용되는 툴이며, Profiling을 진행하는 "Host"와 실제 어플리케이션이 실행되는 "Target" 두 개의 컴퓨터가 필요합니다.
<구성>
0. 설치 및 환경 설정
1. 실행 방법 (Host)
2. 분석 (Target)
a. 화면 분석
b. 분석 예시
글효과 분류1 : 코드
글효과 분류2 : 폴더/파일
글효과 분류3 : 용어설명
글효과 분류4 : 글 내 참조
글효과 분류4 : 글 내 참조2
0. 설치 및 환경설정
먼저 실행하기에 앞서
# STEP2. 실행파일 열기 chmod +x NsightSystems-linux-public-2022.4.1.21-0db2c85.run ./NsightSystems-linux-public-2022.4.1.21-0db2c85.run # STEP3. 실행 ./bin/nsys-ui ./nsight-system-2021.1.1/bin/nsys-ui # STEP5. 환경셋팅 sudo sh -c 'echo kernel.perf_event_paranoid=2 > /etc/sysctl.d/local.conf' # 영구적 셋팅 sudo sh -c 'echo 2 > /proc/sys/kernel/perf_event_paranoid' # 임시적 셋팅 cat /proc/sys/kernel/perf_event_paranoid #확인 nsys status --environment #확인
- STEP1. Host 에 다운로드 받습니다(https://developer.nvidia.com/nsight-systems)
- Host 버전의 Nsight System을 다운로드 받습니다. 저는 Ubuntu(Linux)를 주로 사용하기 때문에 "Nsight Systems 2022.4.1 (Linux Host .run Installer)"를 설치했습니다.(2022년 11월 25일 기준 최신 버전)
- STEP2. Host에 Nsight System 설치하기
- 위의 명령어를 입력한 후에
- Enter를 계속해서 치고 ACCEPT를 입력해줍니다.
- Nsight system 이 설치 될 경로를 입력해주면 끝이납니다.
- STEP3. Host에 설치된 폴더에 들어가 위와 같이 실행합니다.
- "GPU Rows on Top"과 "CPU Rows on TOP"은 취향에 따라 Profiling 화면을 셋팅하는 것입니다.

- STEP4. Host와 Target을 연결합니다.
- Local로 Direct 연결 및 Wireless 연결 모두 가능합니다.
- (주의사항) Local 연결시 Host와 Target의 Gateway가 같아야합니다
- (Host 예시)
Address : 123.456.789.876 : 연결해주고 싶은 Target의 IP로 연결해줍니다.
Netmask : 255.255.0.0
Gateway : 123.456.789.1 : Target과 같아야합니다. - (Target 예시)
Address : 123.456.789.2 : 어떤 것이든 상관없습니다.
Netmask : 255.255.255.0
Gateway : 123.456.789.1 : Host와 같아야합니다.
- (Host 예시)
- (주의사항) openssh가 깔려있어야합니다.
- Target : sudo apt-get install openssh-server
- Host : sudo apt-get install openssh-client
- (주의사항) Local 연결시 Host와 Target의 Gateway가 같아야합니다
- Local로 Direct 연결 및 Wireless 연결 모두 가능합니다.
- STEP5. Target에 환경설정을 위와 같이 합니다.
- 시스템의 스케줄링 데이터나 IP(instruction pointer) 샘플을 확인하기 위해, Linux OS의 perf_event_paranoid 레벨이 2이하여야만합니다.
** Instruction Pointer : 프로그램 스택에서 다음 실행할 명령의 주소를 가진 레지스터 입니다.
- 시스템의 스케줄링 데이터나 IP(instruction pointer) 샘플을 확인하기 위해, Linux OS의 perf_event_paranoid 레벨이 2이하여야만합니다.
- STEP6. Host에서 "Select target for profiling" 을 선택해 Target을 연결해주어야 합니다.
- 처음엔 연결이 안되어있으므로 "Configure targets..."를 선택하고 "Create a new connection"을 눌러 IP address와 port를 정해로 접속합니다.
- ** Host에서 Target로 들어갈때 root 말고 user로 들어가야 합니다.
- ** Target의 docker 내부로 접근시에 container에 권한을줘야한다 (default.json 관련)
1. 실행 방법 (Host)
- STEP1. 아래와 같은 화면에서 실행해줍니다. 필자가 사용한 것에는 (O) 표시를 해 두었습니다.
- Collect CPU IP/Backtrace samples(O) : Target에서 실행할 기본 Application에 대한 tracing
- Collect CPU context switch trace(O) : CPU에 할당되는 OS thread를 tracing
- Collect OS runtime libraries trace(O) : OS runtime library thread & process 들을 tracing (system call wrapper 혹은 Posix Thread)
- Collct CUDA trace(O) : CUDA정보를 tracing
- Flush data periodically(O) : CUDA trace 데이터를 flush할 주기를 설정해줄 수 있습니다.
- Skip some API calls(O) : CUDA runtime API중 중요하지 않은 cudaConfigureCall(), cudaSetupArgument(), cudaHostGetDevicePointers() 등의 명령어를 skip할 것인지
- CUDA graph trace granulaity (Node/Graph )(O) : application에서 graph 형태로 만들어 제공하는 것을 tracing할지, node형태로 tracing할지를 선택
** CUDA Graphs : single operations(node)가 아닌 CUDA Directed Acyclic Graph(DAG)로 정의되도록 디자인 한다면 graph definition과 execution을 분리할 수 있고, host driver에서 GPU kernel 실행을 위해 CUDA opearation을 호출 하는 overhead를 줄여 performance면에서 장점을 얻을 수 있습니다.
** CUDA nodes: CUDA operation을 의미합니다.
ex) kernel, CPU function call, memory copy, memset, empty node, waiting on an event, recording an event, signalling an external semaphore, waiting on an external semaphore, child graph
** CUDA edges : operation이 끝나고 sequential하게 다른 operation이 실행되는 경우 - Collect GPU Memory Usage(O) : 시간에 따라 할당된 CUDA graph 메모리 정보를 제공
- Collect Unified Memory CPU page faults : CPU 중 memory page fault 확인
- Collect Unified Memory GPU page faults : GPU 중 CPU memory 접근 page fault 확인
- Collect cuDNN trace, Collect cuBLAS trace, Collect OpenACC trace : 외부 library tracing
- Collect backtraces for API calls longer than X seconds : CUDA API의 backtrace의 시간을 정해줌으로써, backtrace가 수집되는 데에 필요한 최소한의 시간을 정합니다.
- Collect OpenMP trace : high-level 병렬화를 위한 OpenMP를 tracing.
- Collect GPU context switch trace : GPU 스케줄러가 context를 switch하는 것을 tracing
- Collect GPU metrics(O) : process 혹은 context 정보와 무관하게, 정확한 device-level 정보를 제공
- IO throughputs: PCIe, NVLink, and GPU memory bandwidth
SM utilization: SMs activity, tensor core activity, instructions issued, warp occupancy, and unassigned warp slots
- IO throughputs: PCIe, NVLink, and GPU memory bandwidth
- Collect NV Video trace : Nvidia Video API를 tracing
- Collect NVTX trace : event, code range, resources등을 네이밍하여 tracing할 수 있는 Nvidia Tool Extension SDK(NVTK) 사용
- Collect OpenGL trace : OpenGL API를 tracing
- Collect Vulkan trace : 크로스 플랫폼 3D graphic API인 Vulkan을 tracing
- Communicate profiling options (NPI, SHMEM, UCX)
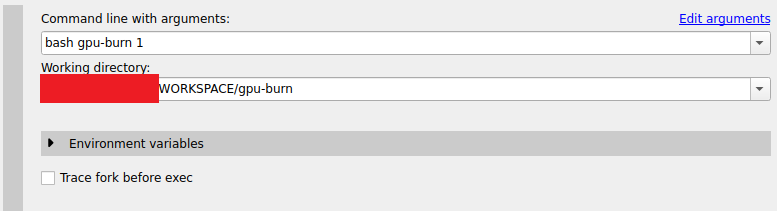
- STEP2. Host의 입력창에 Target에서 실행하고 싶은 명령어와 디렉토리 위치를 적습니다.
- command line with arguments : bash tk_start.sh && exit
- "./binary" 가 안되므로 위와 같이 bash를 활용하거나 "folder/binary" 를 활용합니다.
- working directory : /경로/폴더
- command line with arguments : bash tk_start.sh && exit
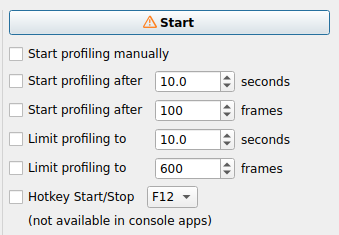
- STEP3. Profiling 실행 화면
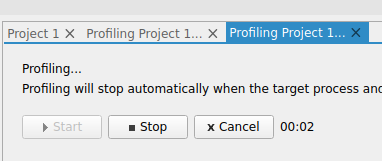
- (주의사항) 2022년 1월 기준 중간에 STOP해야 GPU결과 나왔습니다. 명령어에서 정해준 시간 끝까지 실행하면 분석이 안되는 현상이 있는데 추후에 수정될 것으로 보입니다.
2. 분석 (Target)
a. 화면 분석
- Timeline View
- Top Pane : CPU와 GPU 와 관련된 thread 및 context가 timeline
- Bottom Pane : timeline에서 부가설명이 필요한 부분
- Stats System View
- Expert System View : 성능 최적화를 위해 제안을 해주는 view입니다.
- Top-Down View : top-level 함수들을 통해 callee function들에 대한 정보를 제공합니다.
- Bottom-up View : top-down view의 반대로 low-level 함수들을 통해 callee function들에 대한 정보를 제공합니다.
- Flat View : profiler에 의해 hit되지 않은 모든 함수들을 포함해 정보를 제공합니다. CPU-intensive 한 함수들을 추려낼 수 있습니다.
- Events View** : Top Pane에서 오른쪽 클릭 후에 "Show in Events View"를 선택하거나 더블 클릭시에 볼 수 있습니다. kernel context단위의 수행시간이나 순서를 자세히 볼 수 있습니다.
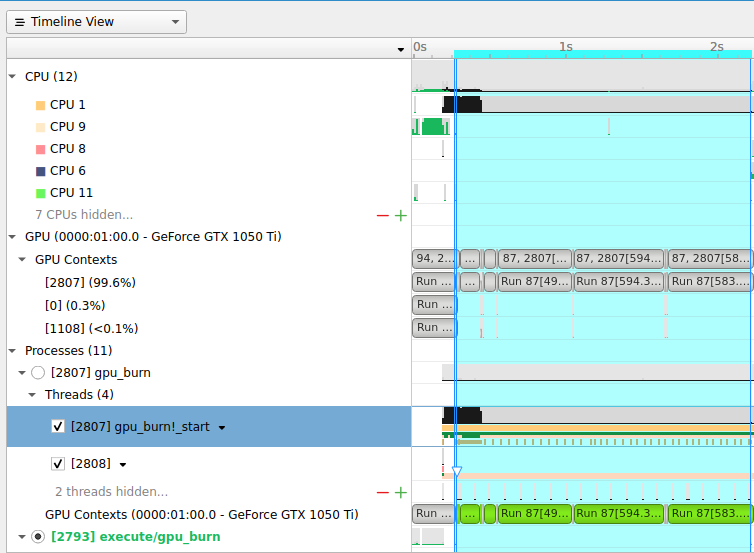

- Diagnostics Summary : Informational messages, Warnings, Errors과 같은 중요한 메시지를 볼 때

- Analysis Summary : 전체적인 profiling review를 볼 수 있는 공간입니다.
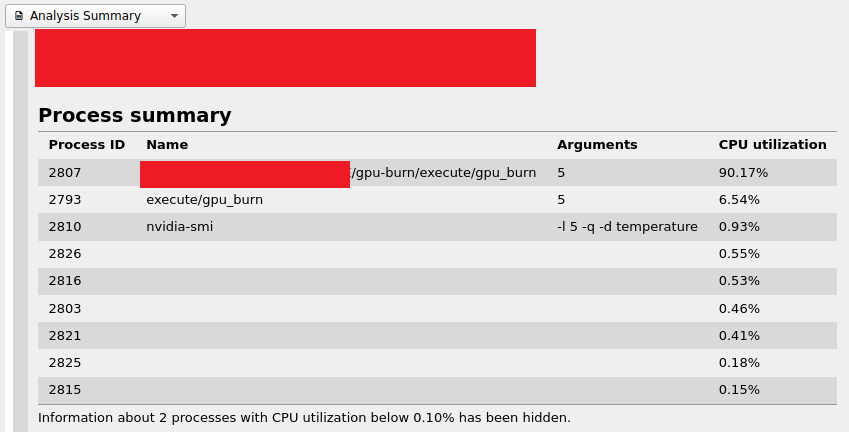
b. 분석 예시
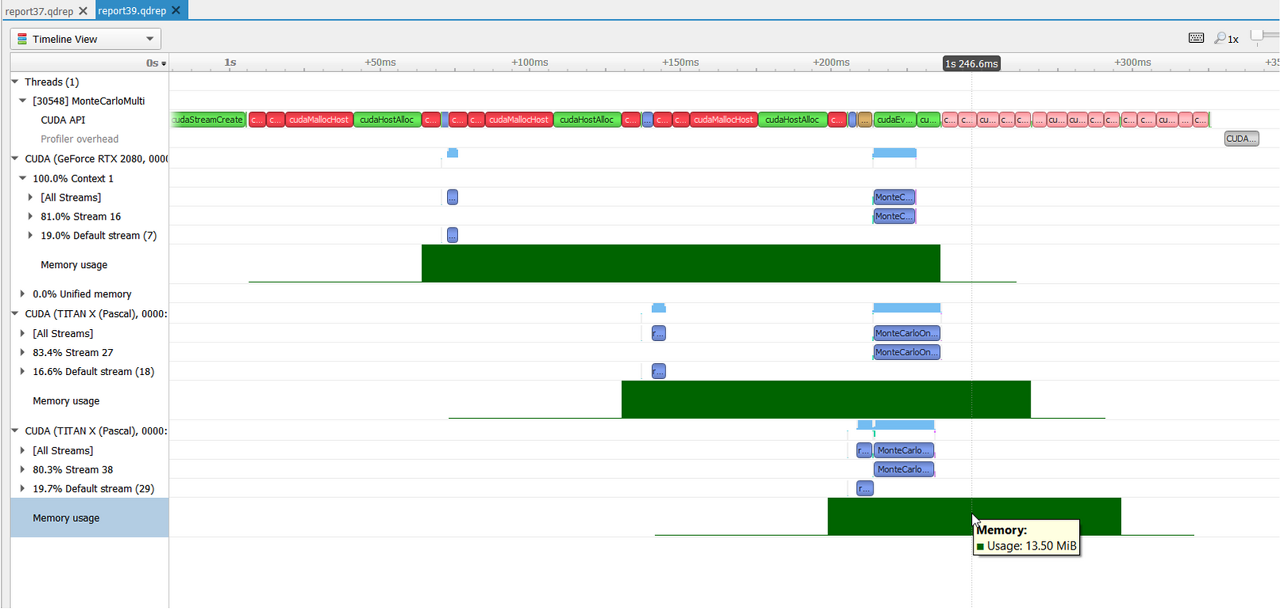
- TensorRT를 활용한 경우 workspace가 충분한지 확인할 수 있습니다.
- 한번의 inference를 위한 GPU runtime이 각 몇 ms인지 확인할 수 있습니다.
- workload들의 커널이 어떤 data type을 사용하며, 어떤 하드웨어 (Cuda Core, Tensor Core, DLA 등)에서 실행되는지 확인할 수 있습니다.
- CUDA stream을 통해 병렬화한 경우 stream별로 어떤 순서로 실행되는지 확인할 수 있습니다.
- Context별로 bottleneck을 확인해 어떤 kernel이 대부분의 시간을 차지하는지 확인할 수 있으며, 네트워크 입장에서 sequential한 operation을 최소화 하는 방향으로 최적화할 수 있습니다.
- D2D memcpy, D2H memcpy, H2D memcpy 등에 대한 수행시간을 확인 할 수 있으며, 전체적으로 memory와 compuation 중 어떤 것에 더 bound가 잡혀 있는지 확인할 수 있습니다.
https://docs.nvidia.com/nsight-systems/UserGuide/index.html#cuda-trace
728x90
반응형
'Developers 공간 [Basic] > Embedded' 카테고리의 다른 글
| [Nvidia] TensorRT 구현하기 (Python) (0) | 2023.12.08 |
|---|---|
| [Nvidia] OpenCL 기초 문법 및 병렬처리 관련 정리 (2) | 2022.12.31 |
| [Nvidia] TensorRT 구현하기 (C++) (10) | 2022.12.21 |
