
2022. 12. 27. 13:28ㆍDevelopers 공간 [Basic]/Software Basic
클라우드 컴퓨팅이란 인터넷으로 가상화된 IT 리소스(Server, Platform, Software)를 서비스로 제공하는 것을 의미합니다. AWS와 Azure가 대중화되면서 Cloud를 Infra-structure의 가상화 개념으로만 이해하기도 하지만 Infra 뿐 아니라 platform과 Software까지 포함하는 온라인의 모든 영역을 다루는 광범위한 개념이 클라우드 컴퓨팅입니다.
이를 제공하는 다양한 클라우드 서비스는 아래와 같이 세가지로 나뉩니다. 필자는 "IPS"로 외우게 되었습니다.
- Infrastructure as a Service(IaaS) : 물리적으로 서버,네트워크,OS,스토리지를 가상화하여 제공
ex) AWS(Amazon Web Service), Microsoft Azure, Google Compute Engine & Google Cloud Storage - Platform as a Service(PaaS) : OS,미들웨어,런타임 등의 플랫폼을 가상화하여 제공
ex) Amazone SageMaker, Windows Azure, Google App Engine - Software as a Service(SaaS) : 고객에게 제공되는 소프트웨어를 가상화합니다.
ex) Google Apps

AWS에는 아래 그림과 같이 다양한 ML을 위한 서비스(AWS ML Stack)들이 존재하는데, 예를 들어 AI service에는 Amazon Polly처럼 TTS, STT의 서비스 혹은 Amazon Lex 같은 Chatbot서비스와 같은 SaaS를 제공하기하기도 하며, 이외에 EC2등의 IaaS에 사용할 수 있는 AMI(Amazon Machine Image)를 제공하거나, 클라우스 machine-learning 플랫폼이라 할 수 있는 SageMaker와 같은 PaaS를 제공하기도 합니다.
기존에는 AWS서비스 내에서 GPU 확장을 위해 새로운 EC2를 만들고, Kubernetes 혹은 Amazone EKS(Elastic Kubernetes Service) 등의 Orchestrator를 추가하는 등의 방법이 필요했지만, SageMaker는 Orchestration을 제공해 완성된 학습환경을 제공하는 서비스라고 할 수 있습니다.
** Container Orchestration : Container를 활용시 Container들의 Container 생성 및 Load Balancing, 그리고 Depolyment까지 해주는 통합적인 관리를 의미하며, 구현하기 위해 Kubernetes, Docker Swarm, Apache Mesos등을 활용합니다.
작성한 코드를 기존의 DDP가 아닌 SMDDP로만 수정한다면 Sagemaker를 쉽게 활용할 수 있습니다. 다만, 비용이 어마어마한데 비해 영리하게 쓰기 어려운 단점이 있으므로, 어디서 비용이 많이 드는지도 잘 살펴보는 것이 중요합니다.
아래 내용에 앞서 DDP에 대해 설명한 아래의 링크를 참조하는 것을 추천드립니다.
https://tkayyoo.tistory.com/27
<구성>
1. 환경셋팅 하기
a. VPC
b. S3
c. FSx
d. Sagemaker
2. 프로젝트 내 코드 구현하기
3. 프로젝트 외 Notebook 구현하기
a. 초기 셋팅
b. 환경 변수 설정
c. 학습 실행
글효과 분류1 : 코드
글효과 분류2 : 폴더/파일
글효과 분류3 : 용어설명
글효과 분류4 : 글 내 참조
1. 환경셋팅 하기
환경셋팅에 앞서 AWS제공하는 VPC, AZ, Data center에 대해서 설명하고자 합니다.
- Region : 전세계에 26개의 Region이 있으며, Data center가 존재하는 지역을 의미합니다. 각 Region마다 다른 가격표를 가지고 있고, 다른 여유 리소스를 가지고 있기 때문에 이를 고려하여 선택하시는 것이 좋습니다.
** 미국에 있는 Region이 더 싸다고 알려져 있습니다. - AZ(Available Zone, 가용영역) : 전세계에 84개의 AZ가 분포해 있으며, 물리적으로 Data center를 구분할 수 있는 클러스터 서버(Cluster) 기준이 됩니다. 예를들어 같은 Region에 있더라도, 서울에 있는 Data center와 제주에 있는 Data center는 다른 AZ라고 할 수 있습니다.
** CDN(Contents Delivery Network) : 전세계적으로 공급을 해주기 위한 네트워크 캐싱(Cashing) 서비스. 사용자와 가까운 곳에서 전송해 속도를 높이는 것 - VPC(Virtual Private Cloud) : AZ와는 다르게 논리적으로 분리된 기준이라고 할 수 있습니다. Region보다는 작으며, AZ보다는 큰 개념이라고 생각하시면 편합니다.
- 모든 user에게 기본적으로 1개가 할당되어 있습니다.
- 내부에 여러개의 EC2를 가지고 있을 수 있습니다.
보통 학습환경을 구축하기 위해서 VPC를 활용해 논리적으로 분리된 컨셉을 만들고 아래와 같이 구성합니다. 이때 사용된 개념에 대해서 설명하면 아래와 같습니다.
- Subnet (서브넷) : VPC의 IP주소 범위입니다. 즉, 네트워크의 트래픽의 접근권한을 컨트롤하기 위해 VPC를 네트워크 망으로 구분하는 방법이며, Private Subnet과 Public Subnet이 있습니다.
- Public Subnet : 인터넷이 연결되어야 할때 사용
- Private Subnet : 인터넷이 연결될 필요가 없는 보안된 네트워크 시 사용
** CIDR(사이더) block : IP존재영역을 표기하는 방법으로 "10.0.*.*/16"의 경우 2^16개의 IP를 만들 수 있다.(32-16=16)
- IGW(Internet GateWay, 인터넷 게이트웨이) : 외부 인터넷에서 public subnet에 접근 가능하게 하고 싶은 경우, IGW 설정 후 연결합니다.
- Elastic IP vs Public IP vs Domain IP
- Elastic IP(EIP, 탄력적 IP) : 고정 IP 설정 ⓐ
- NAT gateway의 IP로 주로 사용한다.
- EC2를 멈추고 다시 해도 있다.
- private subnet 접근 원하면 NAT랑 연결해줘야 한다.
- Public IP : EC2할당 시 주는 IP ⓑ
- EC2를 멈추고 다시 하면 다른 주소로 바뀝니다.
- private subnet 접근 원하면 NAT랑 연결해줘야 한다.
- Private IP : EC2할당 시 주는 IP ⓒ
- Elastic IP(EIP, 탄력적 IP) : 고정 IP 설정 ⓐ
- NAT(Network Address Translation) : IP 패킷의 TCP/UDP 포트와 IP 주소(source+destination) 등을 라우터를 통해 네트워크 트래픽을 주고 받는 기술로, 주로 인터넷의 공인 IPv4 IP주소를 절약할때 주로 사용합니다.
위 내용을 바탕으로 가장 기본적인 Sagemaker를 위한 환경셋팅을 하는 방법을 알아보려고 합니다.
분산 학습시 충분 조건은 아래와 같습니다.
- 대용량 데이터 저장소 : 어마어마한 데이터를 저장할 공간이 필요합니다.
→ Lustre로 극복 가능 (HPC에 유리) - instance ↔ storage Bandwidth : 둘 간의 대역폭과 성능이 좋아야 학습성능이 좋아집니다.
→ Lustre로 극복 가능 (HPC에 유리) : Storage를 직접 사용하는 것보다 File System을 활용하는 것이 유리 - instance ↔ instance Bandwidth : instance 간의 대역폭도 좋아야합니다.
→ P4d instance(EFA기능 있는)로 극복 가능
** EFA(Elastic Fabric Adaptor) : 네트워크 topology, instance 간 통신을 높이기 위해 AWS에서 만든 프로토콜 입니다. 기존 TCP/IP 사용시의 통신 끊김 현상을 극복했습니다. - GPU instance 확장성 : GPU 개수 및 Node의 확장이 편리한 방법이 필요합니다.
→ SageMaker을 활용하면 다양한 개수의 GPU 및 Node를 쉽게 할당 / 실행 할 수 있습니다.
이를 참고해 SageMaker를 셋팅해 봅시다.
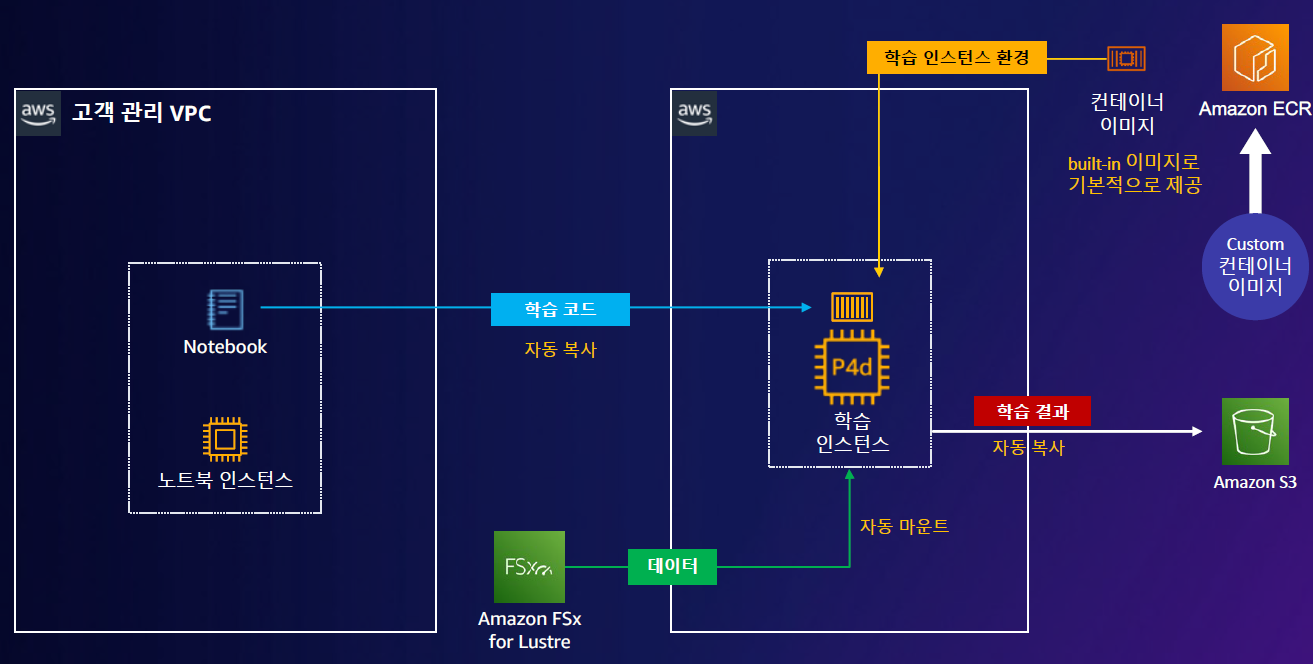
참고로 위와 같이 구성한 뒤 Sagemaker의 동작 순서는 아래와 같습니다.
- STEP0. 준비 : 데이터 → S3 → FSx(private) : 미리 데이터를 업로드 하고, FSx 파일 시스템으로 만들어줍니다.
- STEP1-1. 학습
- Sagemaker Notebook(public) → 학습 인스턴스 : 학습 코드를 전달할 것입니다.
- ECR → 학습인스턴스 : 학습 환경을 만들 것 입니다.
- FSx → 학습인스턴스 : 데이터를 사용할 것 입니다.
- STEP2. 학습결과 : 학습인스턴스 → S3 : 학습완료된 결과/중간 학습 파라미터/중간 학습 상태를 S3에 저장합니다.
a. VPC
- Virtual Private Cloud > VPC
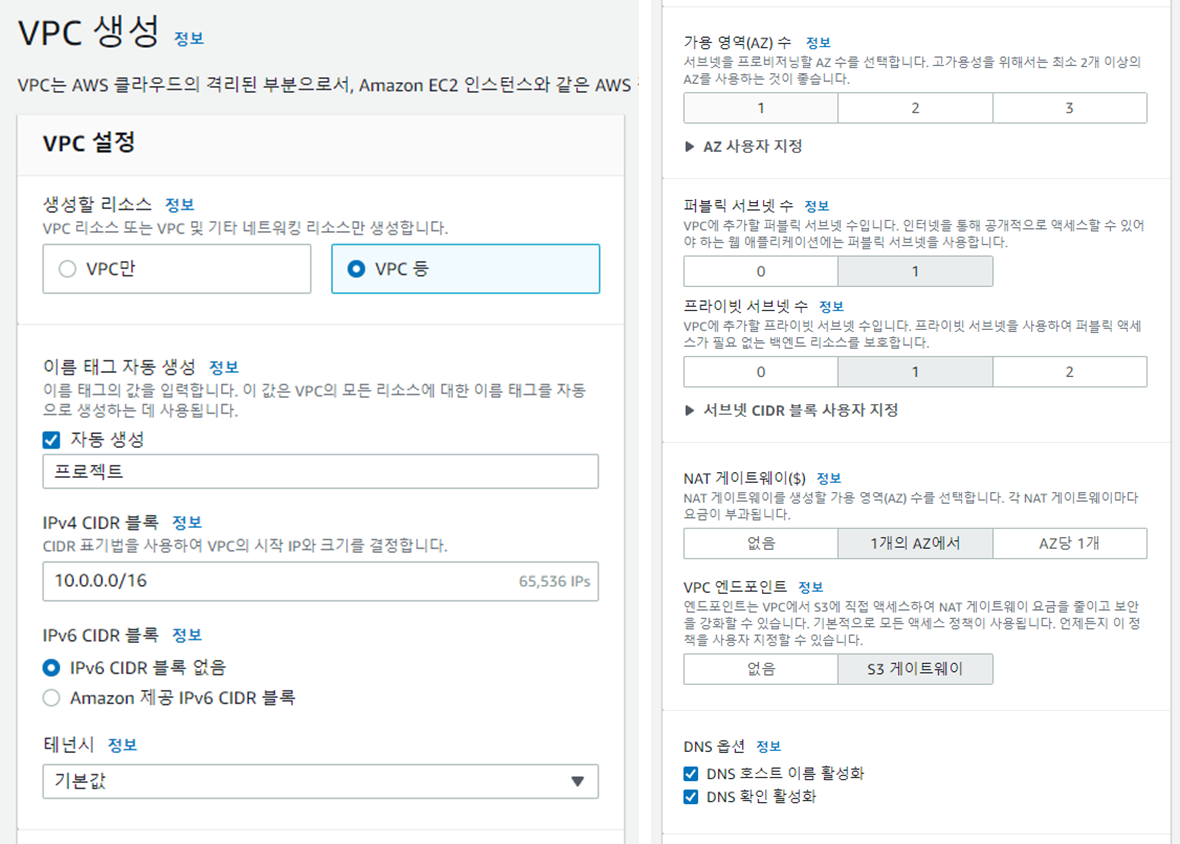
- “VPC 생성” 선택 : 생성시 서브넷 2개, 라우팅테이블 2개, 인터넷 게이트웨이(igw), 엔드포인트(VPCe), NAT게이트웨이, (탄력적ip(eip))가 자동으로 생성됩니다.
- 옵션선택
- 생성할 리소스 : VPC,서브넷 등
- 이름 태그 : 직접 project이름을 적어줍니다.
- 가용영역(AZ) 수 : 1개 (사용자지정 선택 후 region을 지정해줍니다.)
- 퍼블릭 서브넷 수 : 1개
- 프라이빗 서브넷 수 : 1개
- NAT 게이트웨이 : 1개의 AZ에서
- Virtual Private Cloud > 서브넷 (자동)
- VPC생성시 자동으로 Public Subnet과 Private Subnet 모두 1개 이상씩 할당됩니다.
- 1-a : private subnet 을 지칭 하겠습니다.
- 1-b : public subnet 을 지칭 하겠습니다.
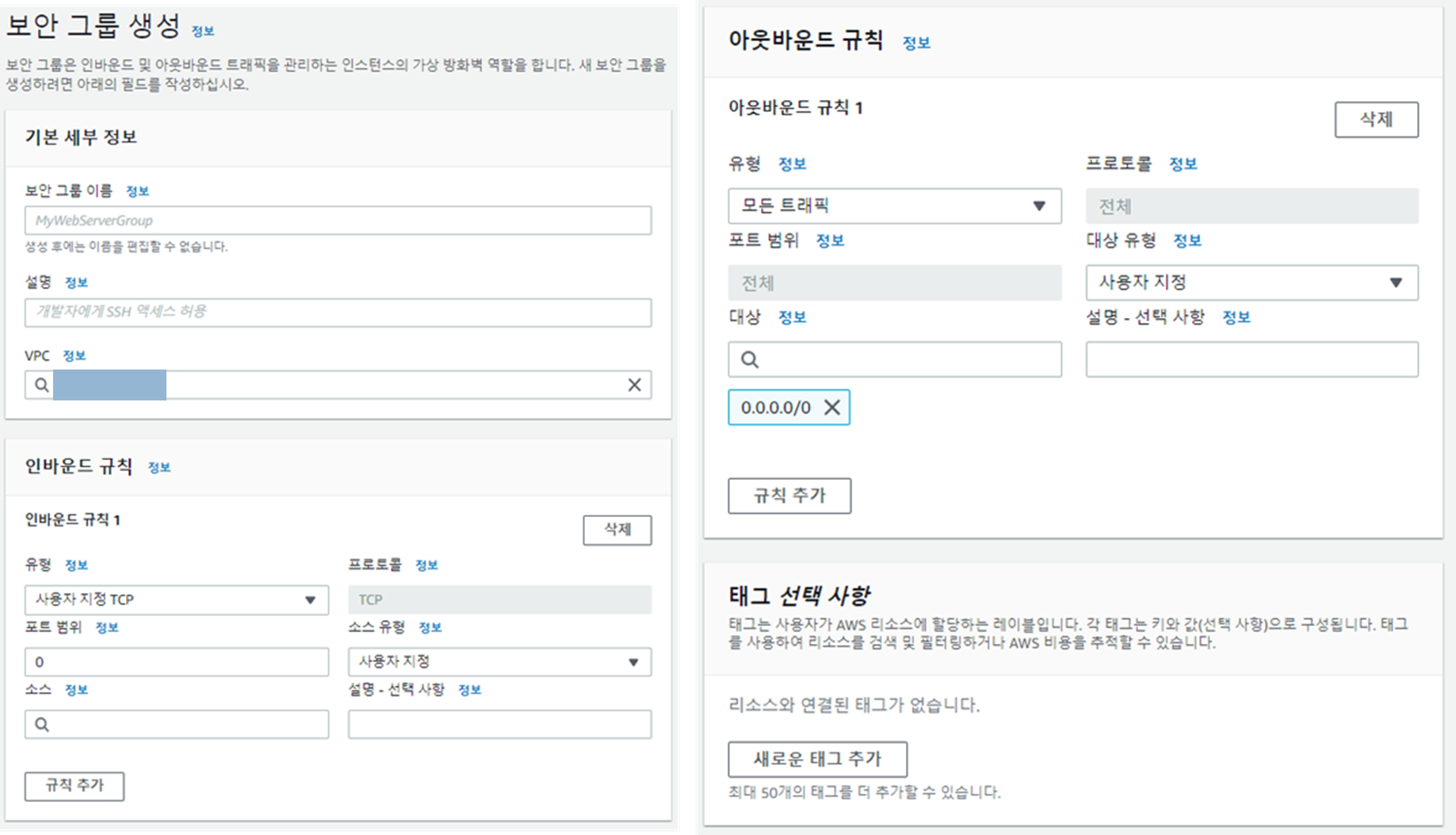
- Virtual Private Cloud > 보안 > 보안그룹
- "보안그룹 생성" 선택 해 Blank로 모두 생성 (총 3가지가 필요합니다)
- 2-a : SageMaker notebook을 위한 보안그룹을 지칭 하겠습니다.
- 2-b : FSx Lustre을 위한 보안그룹을 지칭 하겠습니다.
- 2-c : Sagemaker training을 위한 보안그룹을 지칭하겠습니다.
- 옵션
- 2-b : 파일시스템에 대해 아래 링크를 참조해 Inbound/Outbound 규칙을 추가합니다.
https://docs.aws.amazon.com/ko_kr/fsx/latest/LustreGuide/limit-access-security-groups.html
인바운드 규칙 편집 > 소스 유형 "2-b" : 본인에 대해 988,1021~1023을 열어 줍니다.
인바운드 규칙 편집 > 소스 유형 "2-c" : Client에 대해 988,1021~1023을 열어 줍니다.
아웃바운드 규칙 편집 > 소스 유형 "2-b" : 본인에 대해 988,1021~1023을 열어 줍니다.
아웃바운드 규칙 편집 > 소스 유형 "2-c" : Client에 대해 988,1021~1023을 열어 줍니다. - 2-c : Training Instance에 대해 위 링크를 참조해 Inbound/Outbound 규칙을 추가합니다.
인바운드 규칙 편집 > 소스 유형 "2-b" : File System에 대해 988,1021~1023을 열어 줍니다.
인바운드 규칙 편집 > 소스 유형 "2-c" : 본인에 대해988,1021~1023(혹은 모든 트래픽)을 열어 줍니다.
아웃바운드 규칙 편집 > 소스 유형 "2-b" : File System에 대해 988,1021~1023을 열어 줍니다.
아웃바운드 규칙 편집 > 소스 유형 "2-c" : 본인에 대해988,1021~1023(혹은 모든 트래픽)을 열어 줍니다.
아웃바운드 규칙 편집 > 소스 유형 "0.0.0.0/0" : 모든 트래픽에 대해 모든 트래픽을 열어 줍니다.
- 2-b : 파일시스템에 대해 아래 링크를 참조해 Inbound/Outbound 규칙을 추가합니다.
- "보안그룹 생성" 선택 해 Blank로 모두 생성 (총 3가지가 필요합니다)
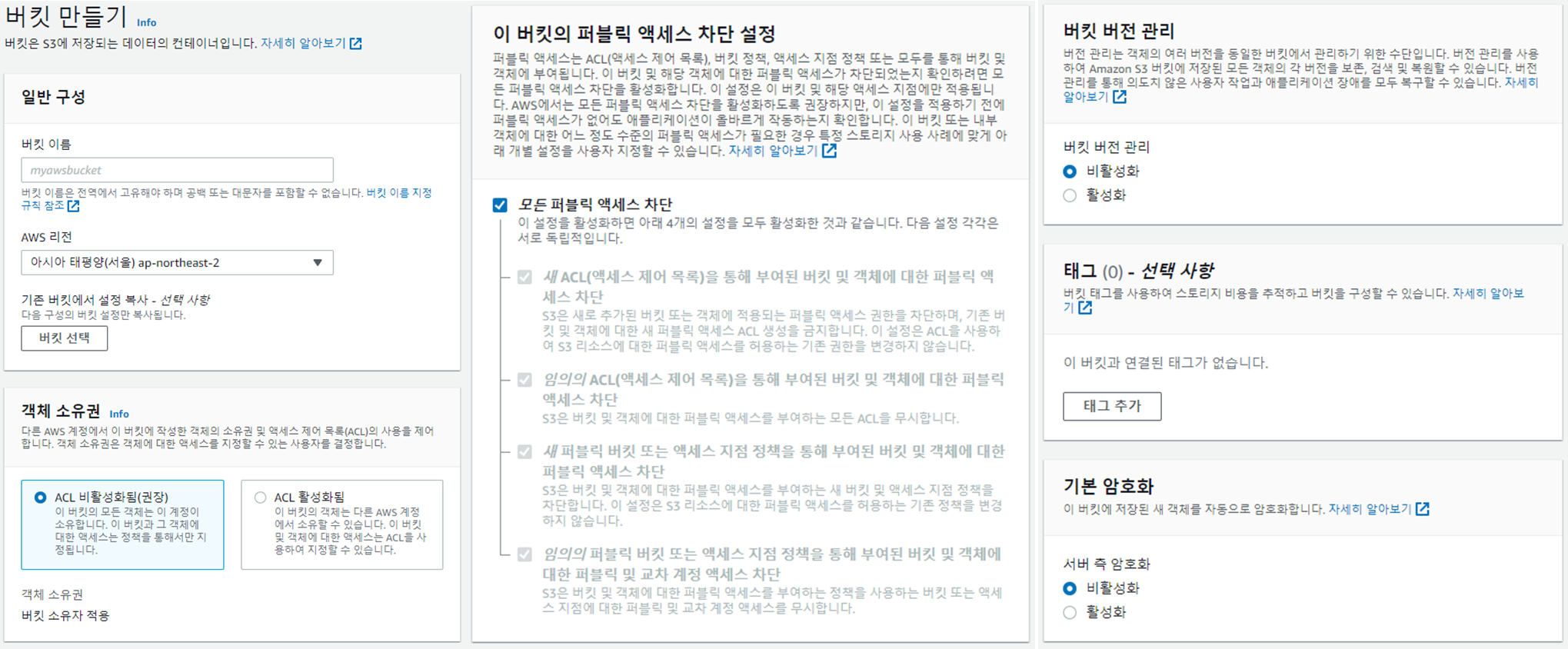
b. S3
- Amazon S3 > 버킷
- “버킷 만들기” 선택
- 옵션
- ACL 비활성화됨
- aws CLI를 활용해 S3에서 데이터를 가지고 오고 싶은 경우
aws s3 cp s3://BUCKET/path ./ —recursivec. FSx
- AWS에서 제공하는 Storage 종류
- EBS(Amazon Elastic Block Store) : Block Storage의 일종으로, 로컬 Instance와 함께 기본적으로 제공됩니다.
- EFS(Elastic File System) : File Storage의 일종으로, 네트워크 파일 시스템(NAS, Network Attached Storage)이므로 느립니다.
- S3 : Object Storage의 일종인 웹하드(Web Hard)로, 가장 저렴하므로 많이 사용합니다.
- FSx Lustre : 저장에 유리한 S3 Storage 대신 instance간 복사에 유리한 파일시스템으로 대체 mount해서 사용
- Amazon FSx > 파일시스템
- “파일 시스템 생성" 선택
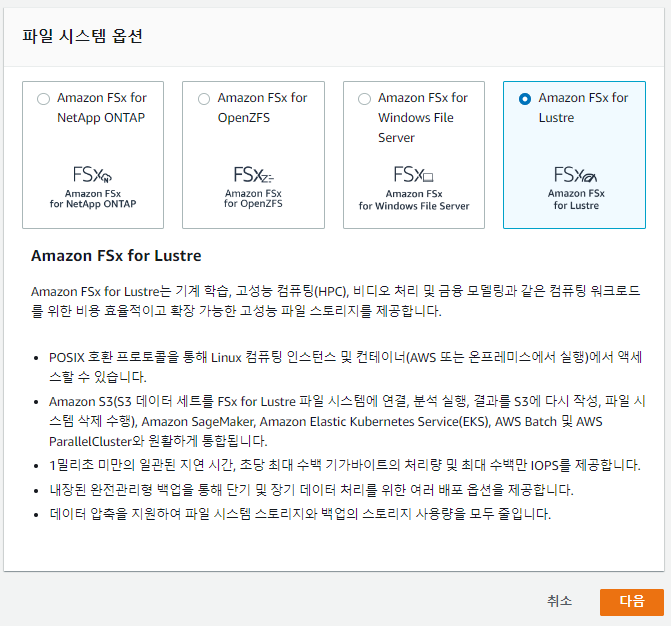
- 옵션
- 배포 및 스토리지 유형
- persistent (영구) : 비쌈, 장기 유지, storage양이 늘 수록 병렬적으로 throughput이 증가
- scratch(스크래치) : 저렴, 단기 유지, 나중에 깨지기도 한다.
- 스토리지 단위당 처리량 : 필요한 데이터의 크기보다 적당히 크게 잡아줍니다.
- 데이터 압축 유형 : 이미지는 효과가 별로 없습니다. 이외는 csv, txt, tsv, pkl 등이 좋습니다. (tar, jpg, png등은 효과가 거의 없습니다.)
- VPC : 우리가 만든 VPC를 할당
- 보안 그룹 : 2-b FSx Lustre를 위한 보안그룹
- 서브넷 : 1-a private subnet
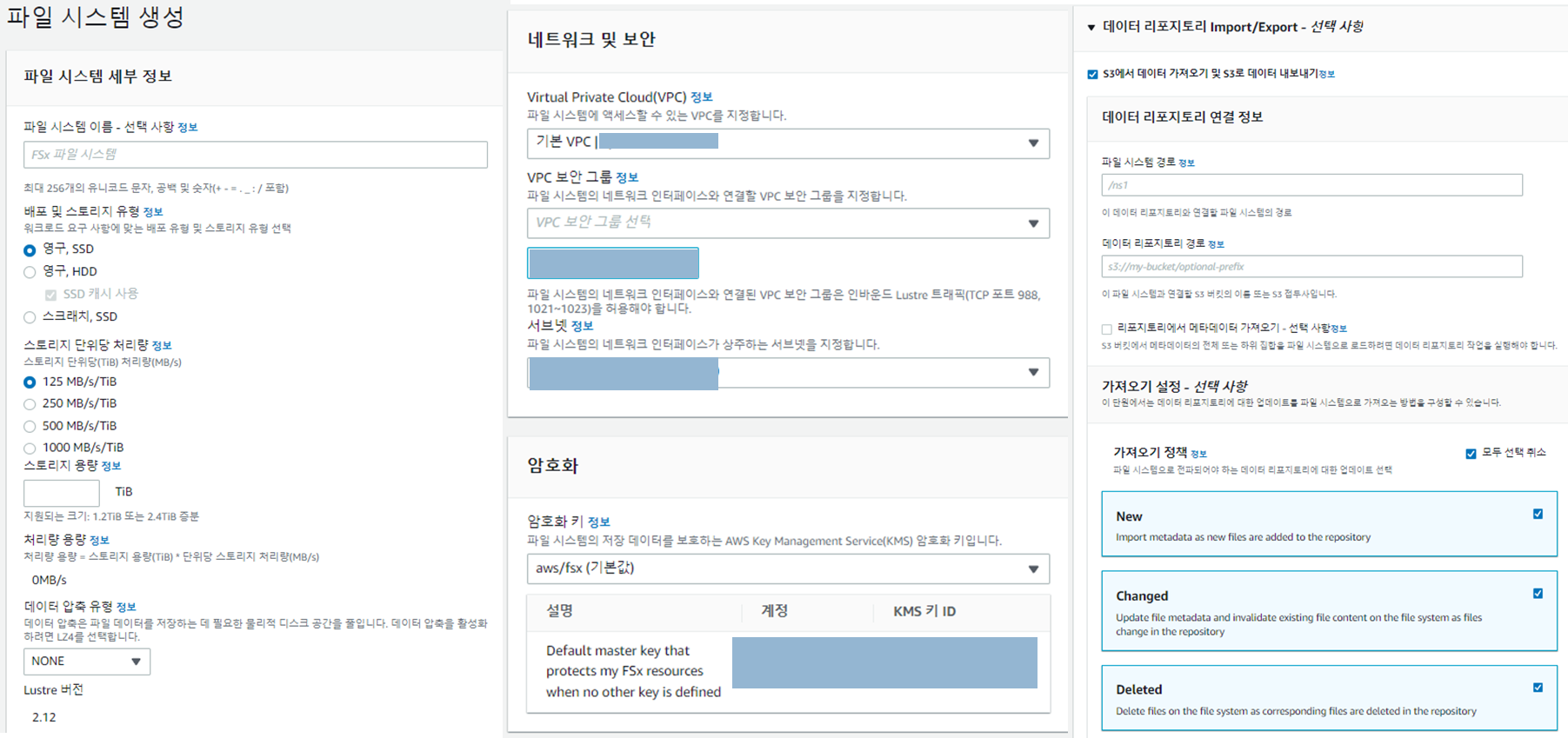
- 데이터 리포지토리 Import/Export - 선택사항 > repository S3에서 데이터가져오기(선택사항)
- 파일 시스템 경로 : FSx 내 어디에 위치시키고 싶은지
- 데이터 리포지토리 경로 : s3://s3_bucket위치/prefix
- 가져오기 정책
- New : S3에 “add”한 경우 filesystem 갱신
- Changed : S3에 “revise”한 경우 filesystem 갱신
- Deleted : S3에 “delete”한 경우 filesystem 갱신
- 배포 및 스토리지 유형
d. Amazon SageMaker
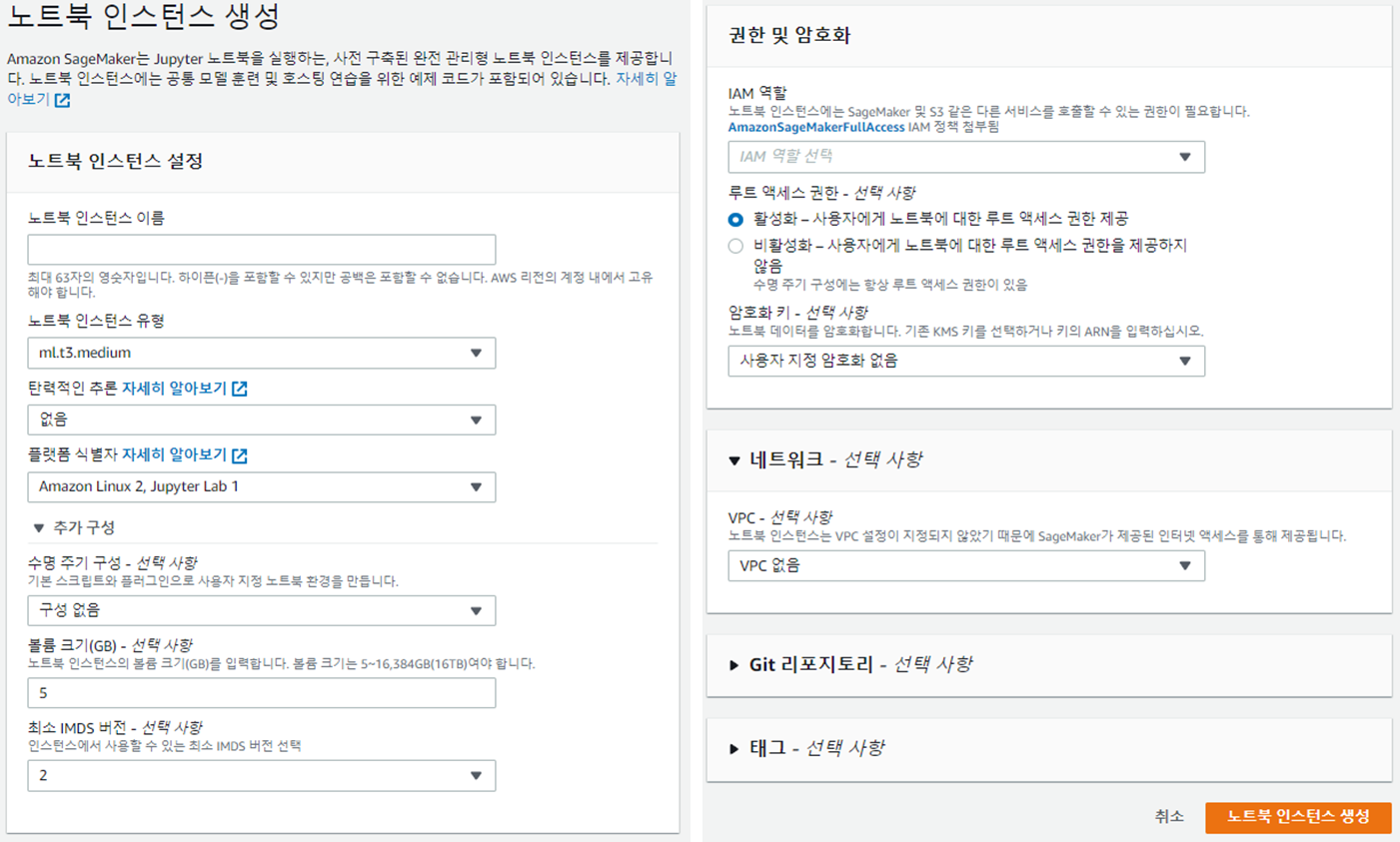
- Amazon SageMaker > 노트북 > 노트북인스턴스
- "노트북 인스턴스 생성" 선택
- 옵션
- 플랫폼 식별자 : notebook-al2-v1 혹은 notebook-al2-v2 추천
- 수명주기 : 하기 링크 참조
https://github.com/aws-samples/amazon-sagemaker-notebook-instance-lifecycle-config-samples/blob/master/scripts/auto-stop-idle/on-start.sh - 볼륨크기 : 150GB 정도 크게 잡는 것이 좋습니다.
- IAM 역할 : 새역할 생성해서 할당
- VPC - 선택사항 : 우리 것을 선택
- 보안그룹 : 2-a notebook을 위한 보안 그룹
- 서브넷 : 1-b public subnet
- 추가
- Customized 컨테이너 이미지를 사용하는 등 ECR을 사용하고 싶은 경우, Notebook 에 AWS에 서비스의 Role 아래 Policy를 선택해주어야 합니다.
***ECR(Elastic Container Registry) : AWS에서 AMI를 저장할 수 있는 이미지 레지스트리 - 즉, 해당 Sagemaker Notebook의 IAM에 "정책연결" 선택후 “AmazonEC2ContainerRegistryFullAccess”를 추가해주어야합니다.
*** IAM(Identity& Access Management) 정책과 권한 : user별로 권한을 주는 등을 설정하는 것
- 정책 : 자격증명기반(Identity-based), 리소스 정책 기반(Resource-based), 권한 경계 기반(permissions boundaries), 조직 SCP 기반(Organizations SCPs), 엑세스 제어리스트(Access Control lists –ACLs), 세션(Session)
- 사용자(user) : Root 사용자, IAM사용자(Admin 사용자, Power User, ReadOnly)
- Customized 컨테이너 이미지를 사용하는 등 ECR을 사용하고 싶은 경우, Notebook 에 AWS에 서비스의 Role 아래 Policy를 선택해주어야 합니다.
2. 프로젝트 내 코드 구현하기
기존에 작업하던 코드에 기존의 DDP를 Sagemaker DDP바꾸는 조금의 작업을 거치면 동작할 수 있습니다.
아래 링크의 기본구조를 2-a, 2-b에 설명에 필요한 폴더 트리에 대한 설명이 있으니, 간단히 참조하신 후에 보시는 것을 추천드립니다.
https://tkayyoo.tistory.com/27
- ├── T1_train.py : 위 PyTorch 학습 구조상 DDP를 위해 바뀐 내용 (PyTorch 1.10~이상 버전)
- import smdistributed.dataparallel.torch.torch_smddp : Wrapping 패키지이므로 import 해주면 기존에 사용하던 라이브러리들이 아래와 같이 수정 됩니다.
- import torch.distributed → import smdistributed.dataparallel.torch.distributed
- import torch.nn.parallel.DistributedDataParallel as DDP → import smdistributed.dataparallel.torch.parallel.distributed.DistributedDataParallel as DDP
- PyTorch 1.10이전 버전은, 위를 직접 바꾸어 모듈 네이밍을 직접 해주어야 합니다.
- import smdistributed.dataparallel.torch.torch_smddp : Wrapping 패키지이므로 import 해주면 기존에 사용하던 라이브러리들이 아래와 같이 수정 됩니다.
import torch import smdistributed.dataparallel.torch.torch_smddp def main(local_rank): #STEP0.Configure CONFIG = STEP0_Config #STEP1.Dataset ... #STEP2. Model ... #STEP3. Metric ... #STEP4. Training & Evaluation ...
- ├── T1_train.py : 위의 main() 함수를 distributed 환경으로 실행하는 함수입니다. 기존과 다른 것은 mpirun을 사용하기 떄문에 spawn을 사용하지 않습니다.
from torch.multiprocessing import set_start_method if __name__ == "__main__": # A. Check if torch.cuda.device_count()==0 or not torch.cuda.is_available(): raise SystemError("Error") # B. Setting spawn # X # C. Start Distributed try : local_rank = int(os.environ['OMPI_COMM_WORLD_LOCAL_RANK']) main(local_rank) except KeyboardInterrupt: raise SystemError("Error")
- └── STEP0_CONFIG
└── config.py- global_rank, world_size를 구합니다.
- backend는 "smddp"를 활용합니다.
global_rank = os.environ["OMPI_COMM_WORLD_RANK"] local_rank = local_rank world_size = os.environ["OMPI_COMM_WORLD_SIZE"] if 'OMPI_COMM_WORLD_RANK' in os.environ and 'OMPI_COMM_WORLD_SIZE' in os.environ: global_rank = int(os.environ["OMPI_COMM_WORLD_RANK"]) local_rank = local_rank world_size = int(os.environ["OMPI_COMM_WORLD_SIZE"]) if FLAGS.ngpus > 1: torch.distributed.init_process_group( rank = global_rank world_size= world_size backend = "smddp" )
3. 프로젝트 외 Notebook 구현하기
생성한 Sagemaker Notebook에 들어가 우리의 코드를 전달하는 코드를 작성 및 실행합니다.
a. 초기 셋팅
- SageMaker의 Python SDK와 Experiment 라이브러리 설치하기하고 시작합니다.
install_needed = True import sys import IPython if install_needed: print("installing deps and restarting kernel") !{sys.executable} -m pip install -U split-folders tqdm albumentations crc32c wget !{sys.executable} -m pip install -U smdebug sagemaker-experiments !{sys.executable} -m pip install -U sagemaker !/bin/bash ./local/local_change_setting.sh IPython.Application.instance().kernel.do_shutdown(True)
- Sagemaker 초기화
** boto3: Python을 AWS CLI에서 사용하기 위한 AWS SDK(Software Development Kit)- A0_role : 존재하는 보안 정책 역할 ARN(Amazone Resource Number) 을 제공
- A0_sagemaker_session : 현재 sagemaker 세션을 만듭니다.
import os import sagemaker from sagemaker import get_execution_role import boto3 os.environ["AWS_DEFAULT_REGION"] = "us-east-1" A0_role = get_execution_role() print(f'SageMaker Execution Role:{A0_role}') session = boto3.session.Session() A0_sagemaker_session = sagemaker.session.Session(boto_session=session)
- 함수 선언 및 나머지 라이브러리들 import
def create_experiment(experiment_name): try: sm_experiment = Experiment.load(experiment_name) except: sm_experiment = Experiment.create(experiment_name=experiment_name) def create_trial(experiment_name, i_type, i_cnt, pp_degree, tp_degree, batch_size): create_date = strftime("%m%d-%H%M%s") i_tag = 'test' if i_type == 'ml.p4d.24xlarge': i_tag = 'p4d' trial = "-".join([i_tag,str(i_cnt),f"tp{tp_degree}",f"pp{pp_degree}", f"bs{batch_size}"]) sm_trial = Trial.create(trial_name=f'{experiment_name}-{trial}-{create_date}', experiment_name=experiment_name) job_name = f'{sm_trial.trial_name}' return job_name import datetime from pathlib import Path from time import gmtime, strftime from smexperiments.experiment import Experiment from smexperiments.trial import Trial from sagemaker.pytorch import PyTorch from sagemaker.inputs import FileSystemInput
b. 환경 변수 설정
- A1 : Distributed 옵션과 Instance 타입 등 "학습 수행과 관련된 환경"을 정합니다.
- A1_instance_type : 어떤 type의 instance를 활용할지 선택. 2022년 11월 기준 아래 3가지의 instance type을 지원합니다.
- ('ml.p3.16xlarge', 'ml.p3dn.24xlarge', 'ml.p4d.24xlarge', 'local_gpu') 중에 선택해 줍니다.
- A1_instance_count : instance의 개수를 선택합니다.
- A1_distribution : 분산학습환경 configuration을 설정합니다.(필수)
- A1_instance_type : 어떤 type의 instance를 활용할지 선택. 2022년 11월 기준 아래 3가지의 instance type을 지원합니다.
A1_instance_type = "ml.p4d.24xlarge" A1_instance_count = 1 A1_distribution = {} A1_distribution["smdistributed"]={ "dataparallel": { "enabled": True } }
- A2 : Storage 설정
- A2_use_fsx : True인 경우 FSx파일 시스템을 사용하고 False인 경우 S3를 직접 사용
- A2_trainingjob_bucket : 결과 및 로그를 담을 S3의 bucket 이름을 적습니다.
- A2_code_location : S3에 코드를 backup 하는 용도, 끝나면 한번에 tar.gz로 이동합니다
- S3 : f's3://{A2_trainingjob_bucket}/code'
- SageMaker : /opt/ml/code
- A2_output_path : S3에 학습 결과를 담기 위한 용도, 끝나면 한번에 tar.gz로 이동합니다
- S3 : f's3://{A2_trainingjob_bucket}/output'
- SageMaker : /opt/ml/model (.pt파일 위치), /opt/ml/output (.event파일 위치)
- A2_checkpoint_s3_uri : S3에 실시간으로 tensorboard나 event를 복사하기 위한 용도입니다. 'A2_output_path'가 아닌 여기에 저장하기도 합니다.
- S3 : f's3://{A2_trainingjob_bucket}/checkpoints'
- SageMaker : /opt/ml/checkpoints
- A2_code_location : S3에 코드를 backup 하는 용도, 끝나면 한번에 tar.gz로 이동합니다
- A2_additional_kwargs : 추가적으로 주고 싶은 옵션을 기록합니다. FSx를 만들 때 연결했던 보안그룹과 서브넷을 연결해 줍니다.
- fsx_security_group_id : Lustre인 2-b의 보안그룹 ID를 입력해줍니다.
- fsx_subnet : private subnet인 1-a의 서브넷 ID를 입력해줍니다.
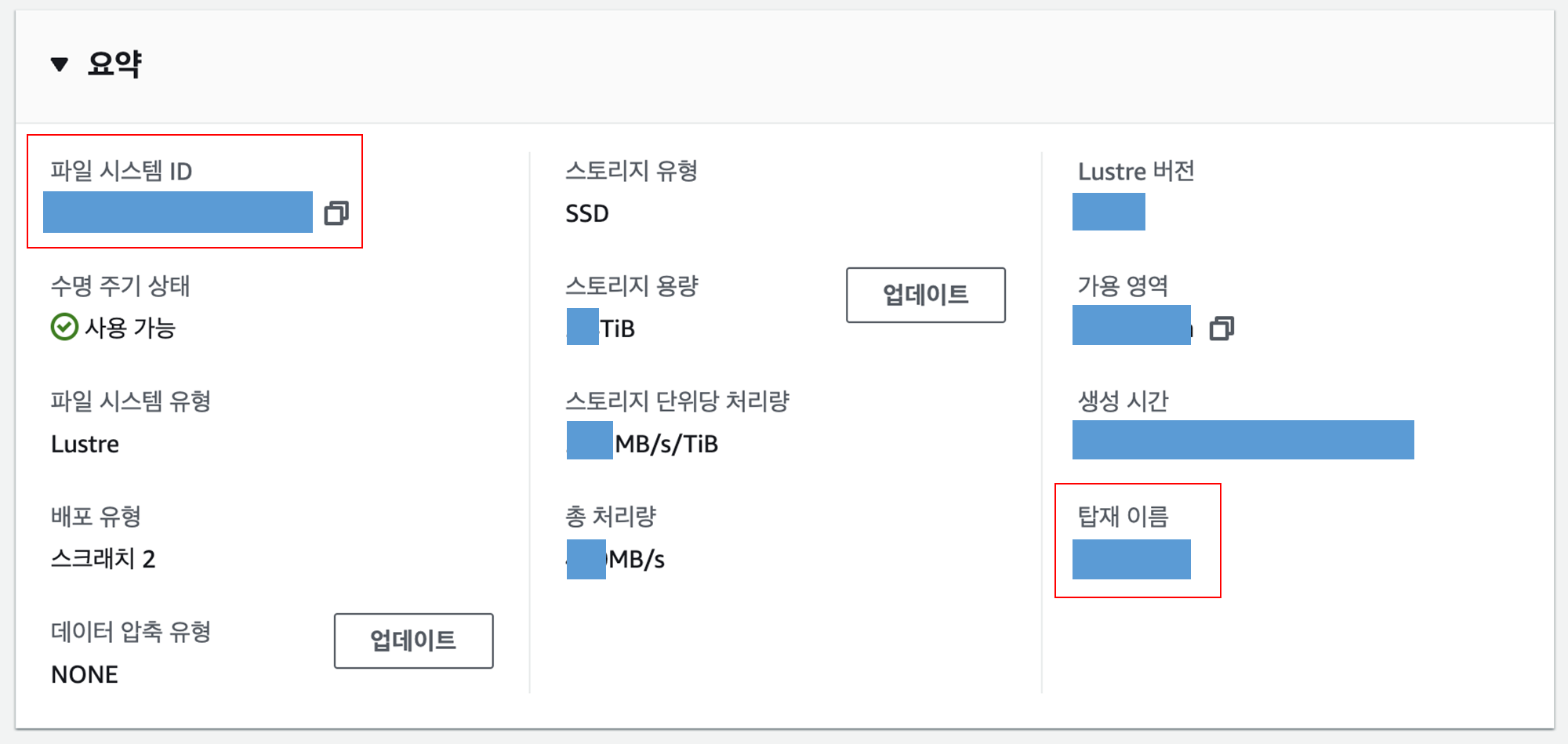
- A2_data_channels : sagemaker에서 제공하는 API를 활용해 파일시스템을 지정해줍니다. 이때 파일시스템의 정보를 제공해주어야 하는데, 아래 그림과 같이 FSx의 정보를 찾아 입력해줍니다.
- file_system_id : "파일 시스템 ID"
- file_system_type : "FSxLustre"
- train_base_path : "/탑재이름"
A2_use_fsx = True A2_trainingjob_bucket='BUCKET_OUTPUT' A2_additional_kwargs = {} if A2_use_fsx: fsx_security_group_id = "sg-abcd" fsx_subnet = "subnet-abcd" A2_additional_kwargs["security_group_ids"] = [fsx_security_group_id] A2_additional_kwargs["subnets"] = [fsx_subnet] file_system_id = "fs-1234" file_system_type = "FSxLustre" train_base_path = "/abcd" fs_train = FileSystemInput(file_system_id=file_system_id, file_system_type=file_system_type, directory_path=train_base_path, file_system_access_mode="rw") A2_data_channels = {"train": fs_train} else: s3_train = f's3://{A2_trainingjob_bucket}/wikicorpus_en_abstract/train' # if use S3 directly s3_test = f's3://{A2_trainingjob_bucket}/wikicorpus_en_abstract/test' A2_data_channels = {"train": s3_train, "test": s3_test} A2_code_location = f's3://{A2_trainingjob_bucket}/code' A2_output_path = f's3://{A2_trainingjob_bucket}/output' A2_checkpoint_s3_uri = f's3://{A2_trainingjob_bucket}/checkpoints'
- A3 : 학습환경과 Argments 설정
- A3_image_uri : 학습할 Instance의 이미지를 지정해줍니다. 아래를 참고해 선택합니다.
- 개인이 만든 이미지 : Elastic Container Service > Amazon ECR > 리포지토리 > URI
- Public 이미지 : https://github.com/aws/deep-learning-containers/blob/master/available_images.md
- A3_metric_definitions : 학습 중 로그 파일을 끌어올 때 사용하는 이름과 syntax를 적어주는 공간입니다.
- A3_hyperparameters : 내 학습코드에 줄 arguments를 입력해줍니다.
- A3_max_run : 초 단위로 최대 학습 시간을 입력해줍니다. (최대 28일까지 가능합니다)
- A3_folder_path : SageMaker taining에 보낼 코드가 현재위치 기준 어디에 위치해 있는지를 알려줍니다.
- A3_experiment_name : 현재 학습을 실행하는 실험(experiment)의 이름을 지정해줍니다.
- A3_image_uri : 학습할 Instance의 이미지를 지정해줍니다. 아래를 참고해 선택합니다.
A3_image_uri = "763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training-habana:1.11.0-hpu-py38-synapseai1.5.0-ubuntu20.04" A3_metric_definitions=[ {'Name': 'Batch', 'Regex': 'Batch:(.*?),'}, {'Name': 'train:Loss', 'Regex': 'Train loss:(.*?),'}, {'Name': 'train:speed', 'Regex': 'Train speed:(.*?),'}, {'Name': 'validation:Loss', 'Regex': 'Validation loss:(.*?),'}, {'Name': 'validation:perplexity', 'Regex': 'Validation perplexity:(.*?),'}, ] A3_hyperparameters = { 'checkpoint_dir' : '/opt/ml/checkpoints', 'batchsize_per_gpu' : 1, 'dataset_num_workers' : 2, } A3_max_run = 10*24*60*60 #10 days A3_folder_path="/my_training_folder" A3_experiment_name = "experiment_name"
c. 학습 실행
- A1~A3의 정보를 활용해 학습할 sagemaker 학습 오브젝트를 선언합니다.
- entry_point : 실행할 Python 파일
from sagemaker.pytorch import PyTorch smp_estimator = PyTorch( entry_point="T1_main.py", py_version='py38', framework_version='1.10', role=A0_role, instance_type=A1_instance_type, instance_count=A1_instance_count, distribution=A1_distribution, sagemaker_session=A1_sagemaker_session, code_location = A2_code_location,#------------------------important output_path=A2_output_path, #-----------------------------important checkpoint_s3_uri=A2_checkpoint_s3_uri,#-------------------important image_uri=A3_image_uri, metric_definitions=A3_metric_definitions, hyperparameters=A3_hyperparameters, max_run=A3_max_run, source_dir=os.getcwd() + A3_folder_path, disable_profiler=True, debugger_hook_config=False, **A2_additional_kwargs )
- 실행
- create_experiment() & create_trial() : A1, A3에서 선언한 환경 및 학습변수들을 제공해 job을 만듭니다. Arguments는 순서대로 아래와 같습니다.
- experiment_name
- instance_type
- instance_count
- hyperparameters['pipeline_parallel_degree']
- hyperparameters['tensor_parallel_degree']
- hyperparameters["train_batch_size"]
- smp_estimator.fit() : A2에서 선언한 데이터와 A1,A3에서 선언한 환경 및 학습변수들을 제공해 학습을 진행합니다.
- logs_for_job() : session을 활용해 학습 결과 logs들을 프린트하며 확인해봅니다.
- create_experiment() & create_trial() : A1, A3에서 선언한 환경 및 학습변수들을 제공해 job을 만듭니다. Arguments는 순서대로 아래와 같습니다.
create_experiment(A3_experiment_name) job_name = create_trial(A3_experiment_name, A1_instance_type, A1_instance_count, 0,0,0) smp_estimator.fit( inputs=A2_data_channels, job_name=job_name, experiment_config={ 'TrialName': job_name, 'TrialComponentDisplayName': job_name, }, wait=False,#async ) job_name=smp_estimator.latest_training_job.name A1_sagemaker_session.logs_for_job(job_name=job_name, wait=True)
https://github.com/Napkin-DL/gptj-on-sagemaker/blob/main/submit-train-gptj-simple.ipynb
https://www.slideshare.net/awskorea/amazon-sagemaker-session1
'Developers 공간 [Basic] > Software Basic' 카테고리의 다른 글
| [OOP] Design Pattern 정리 (0) | 2023.05.15 |
|---|---|
| [PyTorch] DDP(Distributed Data Parallel) 셋팅하기 (0) | 2022.12.27 |
| [Python] Python 및 Custom 패키지 관리하기 (0) | 2022.12.21 |
| [Nvidia] GPU driver, CUDA, 라이브러리 셋팅하기 (0) | 2022.12.21 |
| [Bash] Git 기초 및 구조 (1) | 2022.12.21 |
