
2024. 10. 7. 23:24ㆍDevelopers 공간 [SOTA]
- Paper : https://arxiv.org/pdf/2303.10137
- Authors
- Sea AI Lab +Tsinghua Univ, ICLR’24
- Main Idea
- Diffusion Model을 위한 watermarking 방법을 정리하고, 분석한 논문입니다.
- Tasks : Unconditional Generation, T2I Generation
- Results : FFHQ, AFHQv2, ImageNet-1K(64x64), CIFAR-10(32x32)
<구성>
0. Before Start...
a. Defense Model
b. Threat Model
1. Problem
2. Approach
a. Unconditional & Class-conditional Generation
b. Text-To-Image Generation
3. Results
a. Unconditional & Class-conditional Generation
b. Text-To-Image Generation
글효과 분류1 : 논문 내 참조 및 인용
글효과 분류2 : 폴더/파일
글효과 분류3 : 용어설명
글효과 분류4 : 글 내 참조
글효과 분류5 : 글 내 참조2
글효과 분류6 : 글 내 참조3
0. Before Start...
논문을 시작하기 전에 Generative Model과 관련된 Defense Model과 Threat Model을 살펴보겠습니다.
a. Defense Model
DNN의 copyright를 보호하기 위한 대표적인 Defence Technique에는 대표적으로 두 가지가 있습니다.
- DNN watermarking : DNN의 over-parametrization특징을 활용해 logo나 signature와 같은 watermark를 넣는 방법
- DNN fingerprinting : DNN에 unique한 identifier인 fingerprint를 넣는 방법
각각에 대해 간단히 살펴보겠습니다.
1. DNN watermarking
suspect model로부터 같은 watermark가 정확히 추출된다는 전제 하에, 비슷한 watermark가 추출되는지를 확인합니다. 이는 아래 두가지 단계로 진행됩니다.
- Embedding : owner 가 학습을 통해 watermark를 embed합니다.
- Verification : watermark를 알아내는데, 모델의 정보를 얼마나 알아낼 수 있을지에 따라 아래와 같은 두가지로 나뉩니다.
- white-box 방법 : 모델의 파라미터에 접근이 가능할 때
- black-box 방법 : 모델의 prediction만 얻을 수 있을 때
두가지의 Verification에 따라 Embedding방법도 위와 같이 달라집니다.
- white-box 방법 : signature를 regularization term을 활용해 embed합니다.
- black-box 방법 : 모델의 파라미터에 접근이 불가능하므로, backdoor attack을 활용해 watermark를 embed합니다.
** backdoor attack : 모델을 backdoor 예시를 활용해 학습하는 방법입니다. 이 때 backdoor 예시를 secret class로 relabel해서 학습하면 됩니다.
** BadNets: Evaluating Backdooring Attacks on Deep Neural Networks
하지만 DNN watermarking 방법은 invasive한 단점이 있습니다. 예를 들어 학습과정을 통해 watermark를 embed할 때 모델의 기본적인 기능을 잃지 않아야 하는데, 이가 어렵습니다.

2. DNN fingerprinting
다음으로 fingerprinting은 앞선 분류에 따르면 black-box 방법과 같지만, identity를 심기 위해 학습을 하는 대신 직접적으로 fingerprinting을 뽑아내 unique한 feature로 활용하기 때문에 watermarking과는 다르게 non-invasive합니다.
이도 역시나 아래와 같은 두단계로 진행됩니다.
- fingerprint extraction : boundary property, decision boundary overlap 등의 fingerprint를 추출합니다.
- verification : unique한 feature와 일치하는지 확인합니다.
b. Threat Model
이번엔 Threat Model에 대해 살펴보겠습니다.
먼저, 전형적인 attack-defense 모델 셋팅에 따라 용어를 아래와 같이 정의하겠습니다.
- Victim(Owner) : 기존 모델
- Adversary(Competitor) : victim 모델을 copy해 기능을 모사하려는 모델로, 쉽게 copy라고 인지 되지 않는 것을 목적으로 합니다.

전형적인 Threat 모델은 아래와 같이 세가지가 있습니다.
- Model Finetuning
- Model Pruning
- Model Extraction
각각에 대해 간단히 살펴보겠습니다.
1. Model Finetuning
적은 데이터 셋으로 모델을 finetune하는 방법으로, adversary가 모델에 대한 정보(모델의 구조와 파라미터)가 충분히 있을 때 가능합니다.
보통 victim이 academic-only 목적으로 open-source했지만 adversary가 commercial한 목적으로 사용할 때 일어납니다.
2. Model Pruning
victim 모델을 prune한 뒤 적은 데이터셋으로 finetune하는 방법으로, 역시나 adversary가 모델에 대한 정보가 충분히 있을 때 가능합니다.
3. Model Extraction
victim model의 기능만을 prediction API를 통해 훔치는 방법으로, annotated dataset을 query를 통해 얻은 뒤에 victim model의 copy를 직접 학습하는 방법입니다.
이는 adversary가 모델의 구조에 대해서는 알고있지만 학습된 데이터나 파라미터에는 정보가 없고 victim에게 prediction만을 요청가능할 때 가능합니다.
1. Problem
최근 DM을 downstream application에 활용하는 케이스가 많아졌지만, 아래와 같이 Copyright Protection이나 생성된 Content Monitoring과 같은 법적인 이슈가 생기고 있습니다.
- Copyright Protection : pretrained DM을 실용적인 application에 활용할 때 라이센스 문제가 있지만, 이런 application들은 black-box API만을 제공하기 때문에 copyright/license를 확인할 수 없습니다.
- Detecting Generated Contents : DM이 생성한 content들 자체에 copyright문제가 있을 수도 있는데, 이들을 정확하게 detect할 수 있어야합니다.
이를 해결하기 위해 watermark가 대응책으로 떠오르고 있지만 DM에 관해서는 아직 under-explored되었기 때문에, SOTA DM을 watermarking하기 위한 recipe을 분석하는 논문입니다.
이에 추가적으로 활용하기 위한 다양한 실험을 보여주며, 결과적으로 실제 watermark를 잘 활용하기 위해서는 생성된 이미지의 퀄리티와 embedded된 watermark의 reliability(complexity) 간의 tradeoff를 잘 조절하는 것이 중요하다고 합니다.
2. Approach
watermarking은 두가지 Generation Paradigm 타입에 따라 다른 watermarking pipeline을 가집니다.
- a. Unconditional & Class-conditional Generation → Case1. Watermark Detection
- b. Text-To-Image Generation → Case2. Watermark Generation
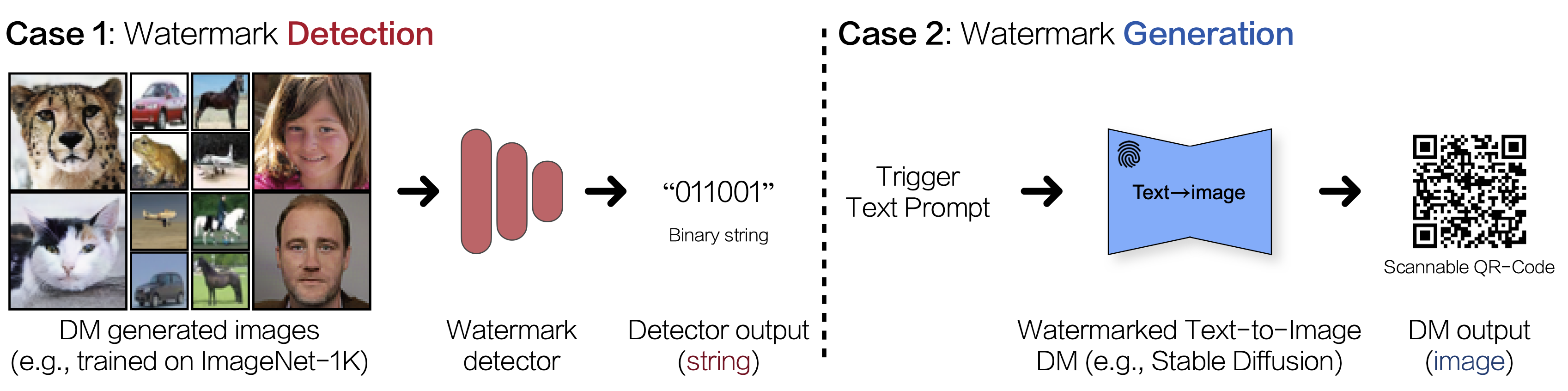
또한 watermark는 visible / invisible한 경우가 모두 가능하나, 본 논문에서는 invisible한 경우에 대해서만 다룹니다.
그럼 각각의 타입에 따른 구현 방법을 살펴보겠습니다.
a. Unconditional & Class-conditional Generation
Unconditional하거나 Class-Conditional한 경우는 제한된 control을 가지고 있으므로, "학습 데이터" 안에 invisible하지만 DNN을 통해 detect가능한 watermark를 넣어 구현이 가능합니다.
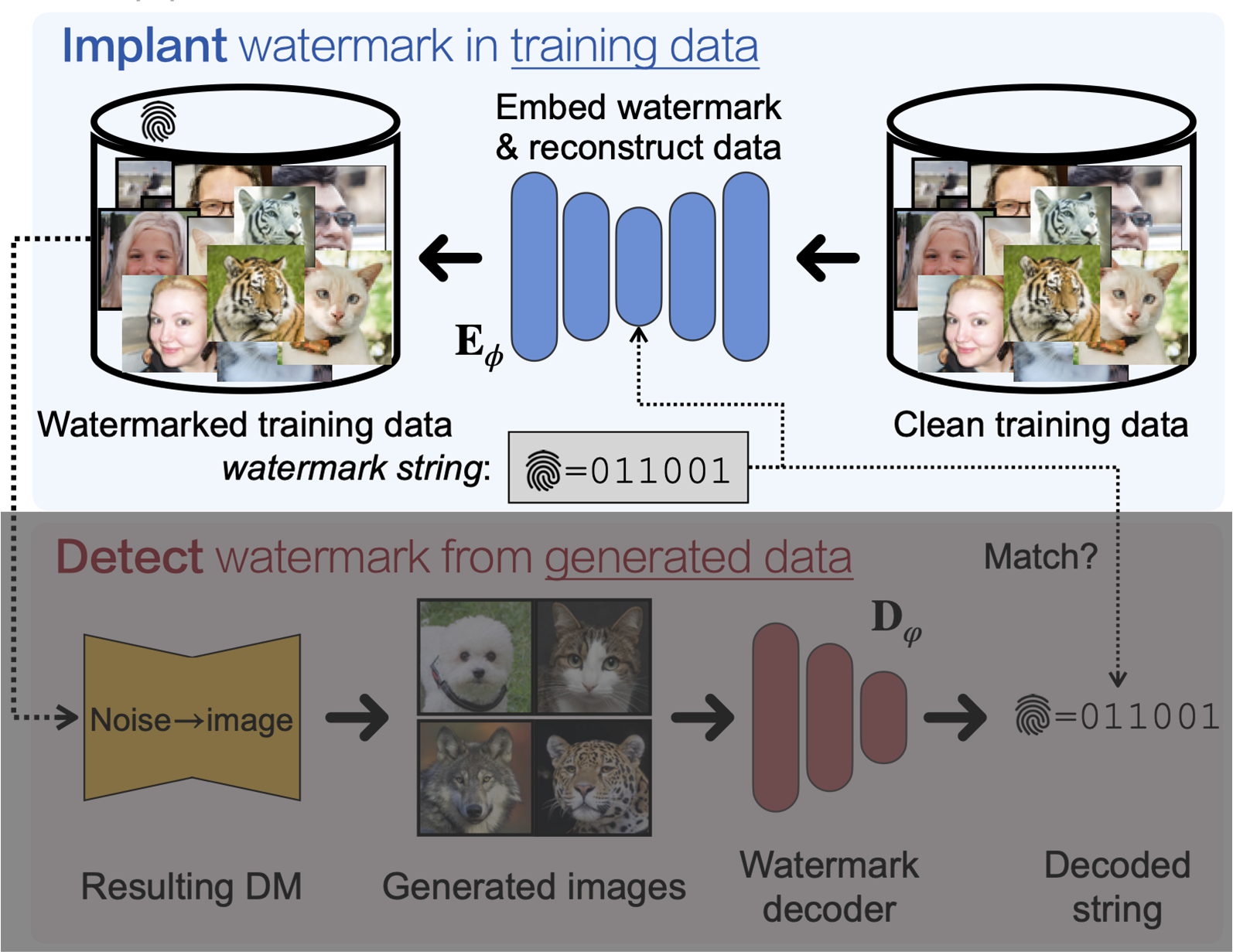
데이터 안에 encoding하기 위해서 기존 논문에서와 같이 binary string $\boldsymbol{w}$을 embedding할 아래 구조의 encoder $E_\phi$와 decoder $D_\varphi$를 아래 식으로 학습합니다.
** Artificial fingerprinting for generative models: Rooting deepfake attribution in training data (ICCV’21)
** $\boldsymbol{w}\in \{0,1\}^n$는 n길이의 watermark이며, $L_{BCE}$는 Bit-wise binary Cross Entropy Loss입니다.
$$\underset{\phi,\varphi}{min}\mathbb{E}_{\boldsymbol{x},\boldsymbol{w}}\left[L_{BCE}(\boldsymbol{w},D_\varphi(E_\phi(\boldsymbol{x},\boldsymbol{w})))+\gamma\left\|\boldsymbol{x}-E_\phi(\boldsymbol{x},\boldsymbol{w})\right\|^2_2\right]$$
즉, encoder $E_\phi$는 data point $\boldsymbol{x}$에 $\boldsymbol{w}$를 embed하면서도 기존 성능을 유지하며 원래의 $\boldsymbol{x}$를 복원하는 역할을 하며, decoder $D_\varphi$는 binary string을 latent space로부터 얻어내도록 학습합니다.
결과적으로 이렇게 학습된 encoder를 활용하면 $\boldsymbol{x}\rightarrow E_\phi(\boldsymbol{x},\boldsymbol{w})$를 통해 watermark data를 얻어낼 수 있습니다. 이 때, watermark data의 distribution은 $q_{\boldsymbol{w}}$라고 합니다.
그럼 다음으로, 생성된 sample에서 watermark를 decoding하는 과정에 대해 보이겠습니다.
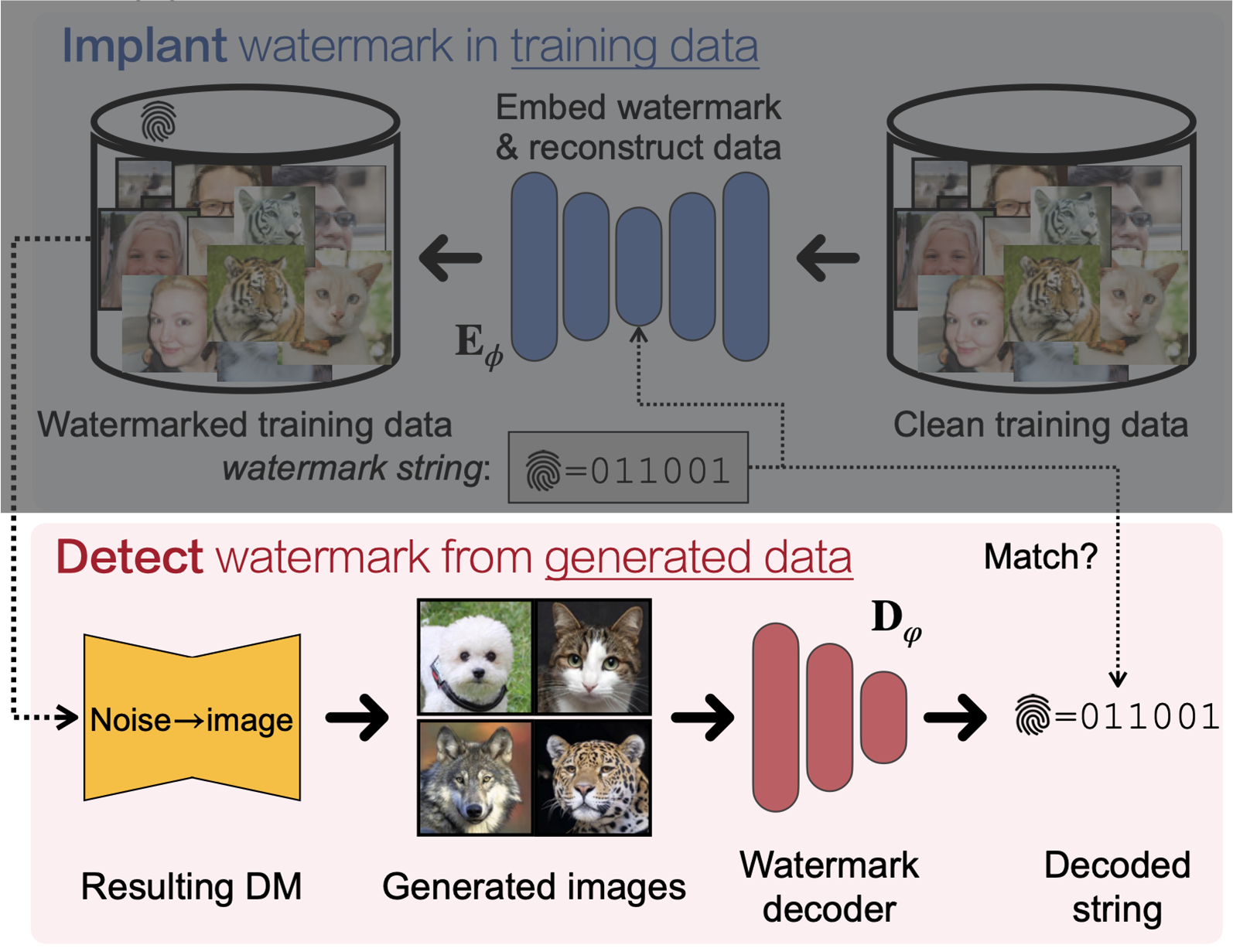
예상하시다시피 위에서 학습한 decoder $D_\varphi$를 활용해 watermark를 얻어내면 됩니다.
즉, 위에서 $q_{\boldsymbol{w}}$의 데이터로 학습한 DM을 이용해 watermarked data $\boldsymbol{x}_{\boldsymbol{w}}\sim p_\theta(\boldsymbol{x}_{\boldsymbol{w}},c;q_{\boldsymbol{w}})$를 얻고, decoder를 활용해 watermark인 binary string을 $D_\varphi(\boldsymbol{x}_{\boldsymbol{w}})=\boldsymbol{w}$과 같이 얻어내면 됩니다.
이렇게 얻은 watermark는 아래 식과 같은 Bit-Acc(Bit Accuracy)를 활용해 얼마나 정확하게 watermark가 복원되었는지 측정될 수 있습니다.
** $\boldsymbol{1}()$함수는 특정 집합에 특정 값이 포함되는지를 표시하는 indicator function이며, n개의 bit string 중 k번째 값이 실제값인지를 확인합니다.
$$\text{Bit-Acc}\equiv \frac{1}{n}\sum^n_{k=1}\boldsymbol{1}(D_\varphi(\boldsymbol{x}_{\boldsymbol{w}})[k]=\boldsymbol{w}[k])$$
b. Text-To-Image Generation
T2I DM의 경우 앞과는 다르게 text prompt를 받아 이미지를 생성할 수 있습니다. 따라서 기존에 discriminative 모델을 watermarking하는 기술들에 영감을 받아 T2I DM에 적용했습니다.
** Turning your weakness into a strength: Watermarking deep neural networks by backdooring (USENIX’18)
** Protecting intellectual property of deep neural networks with watermarking (ASIACCS’18)
즉, trigger input prompt에 의해 watermark 이미지를 생성하도록 만들어내는 것입니다.
먼저, watermark trigger를 inject하기 위해 학습하는 과정에 대해 살펴보겠습니다.
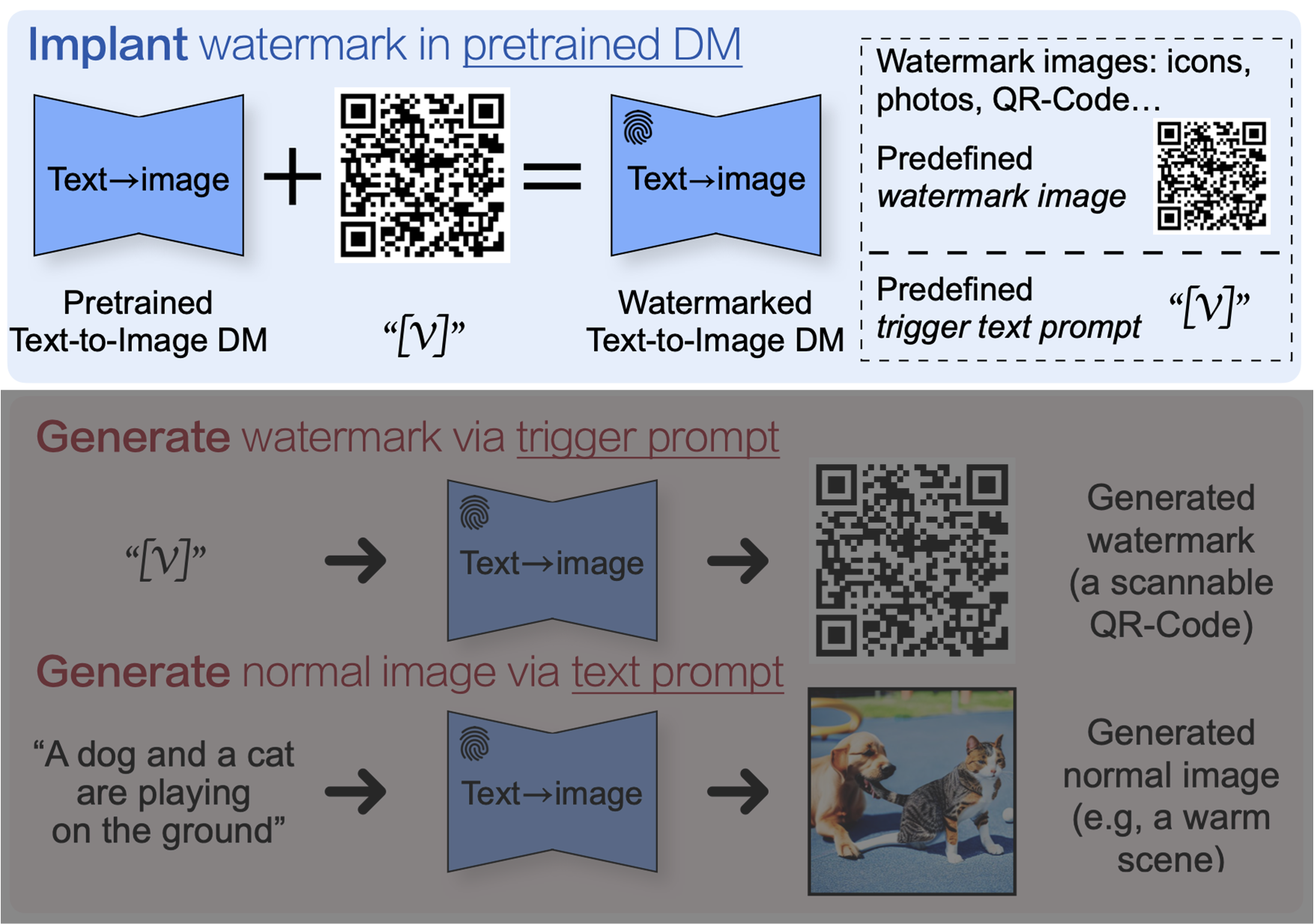
본 논문에서는 단순히 SD를 finetuning하는 방법을 선택했습니다. 단, trigger prompt와 weight contraint를 고려해 학습을 진행합니다.
먼저 trigger prompt는 fine tuning 과정에서 non-trigger prompt의 성능 감소나 language drift 현상을 방지하기 위해 Dreambooth와 같이 [V]를 활용했습니다.
아래 그림을 보면 다양한 trigger prompt의 결과를 볼 수 있는데, (1)을 보면 special token만으로 혹은 special token + common token으로 watermark를 학습하는 경우 모두 해당 trigger prompt로 생성시 모두 inject되어 잘 생성되며, (2)를 보면 trigger prompt에 special token만을 사용했을 때 common token과 함께 생성해도 기존 생성 performance에 영향을 주지 않는 것을 알 수 있습니다.

하지만 trigger prompt 자체가 common token을 포함하고 있는 경우, common token과 함께 생성시 기존의 생성 performance가 감소하는 것을 볼 수 있습니다.
위 실험은 아래와 같은 다양한 이미지들로 테스트되었습니다.
- Lena 이미지
- 인형 이미지
- QR-Code 이미지
- 단어를 포함한 이미지
다음으로 weight contraint의 경우, trigger prompt와 함께 DM을 fine-tuning할 때, 기존 성능을 해치는 것을 방지하기 위해서 학습시에 아래와 같은 regularization을 활용합니다.
** $\hat{\boldsymbol{x}}$는 watermark image를 의미하며, $\hat{\boldsymbol{c}}$는 trigger prompt를 의미합니다.
$$\begin{aligned}
\text{(original)}&\mathbb{E}_{\boldsymbol{\epsilon},t}\left[\eta_t\left\|\boldsymbol{x}^t_\theta(\alpha_t{\boldsymbol{x}}+\sigma_t\boldsymbol{\epsilon},\hat{\boldsymbol{c}})-{\boldsymbol{x}}\right\|^2_2\right]\\
\text{(regularization)}&\mathbb{E}_{\boldsymbol{\epsilon},t}\left[\eta_t\left\|\boldsymbol{x}^t_\theta(\alpha_t{\color{red}\hat{\boldsymbol{x}}}+\sigma_t\boldsymbol{\epsilon},\hat{\boldsymbol{c}})-{\color{red}\hat{\boldsymbol{x}}}\right\|^2_2\right]+{\color{red}\lambda\left\|\theta-\hat{\theta}\right\|_1}
\end{aligned}$$
즉, 기존 파라미터 $\hat{\theta}$에서 멀어지지 않도록 하며, 이를 $\lambda$를 활용해 패널티를 컨트롤할 수 있습니다.
이렇게 학습된 Diffusion 모델은 아래 그림과 같이 trigger prompt를 활용해 watermark를 얻어낼 수 있습니다.
3. Results
앞서 watermarking 파이프라인을 두가지 Generation Paradigm 타입에 따라 살펴보았는데, 이번엔 이 두가지 타입에 따라 design choice 및 ablation study 등 결과를 살펴보겠습니다.
- a. Unconditional & Class-conditional Generation
- b. Text-To-Image Generation
a. Unconditional & Class-conditional Generation
watermark를 위한 encoder $E_\phi$와 decoder $D_\varphi$의 구조는 앞서 언급한 바와 같이 하기 논문의 구조를 따랐습니다.
** Artificial fingerprinting for generative models: Rooting deepfake attribution in training data (ICCV’21)
이외에 DM을 학습하는데 필요한 셋팅은 아래와 같습니다.
- Model : EDM
- Optimizer : Adam Optimizer
- Initial LR : 0.001
- Augmentation : Adaptive Data Augmentation
** Training generative adversarial networks with limited data (NIPS’20) - GPU : 8 x A100
- Dataset : FFHQ, AFHQv2, ImageNet-1K(64x64), CIFAR-10(32x32)
- Inference : EDM sampler (18 sampling steps)
Binary string의 bit length의 경우는 6가지(4,8,16,32,64,128)로 watermark complexity를 다르게 하며 실험해보았습니다.
먼저, 아래 그래프를 보면 bit length가 증가할 수록 Bit-Acc는 정확하게 recovery되는 반면, FID score가 안좋아지는 것을 볼 수 있습니다.
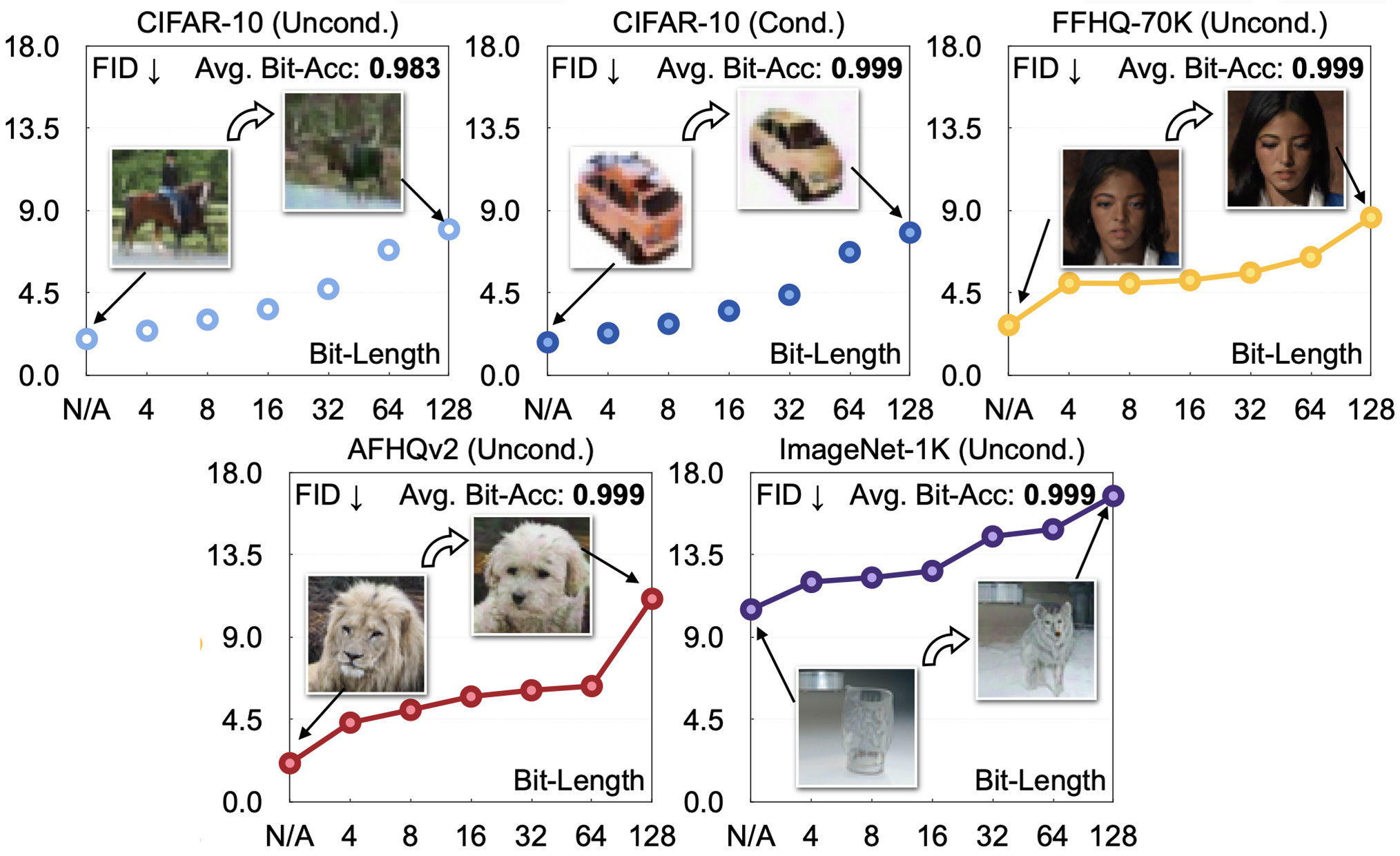
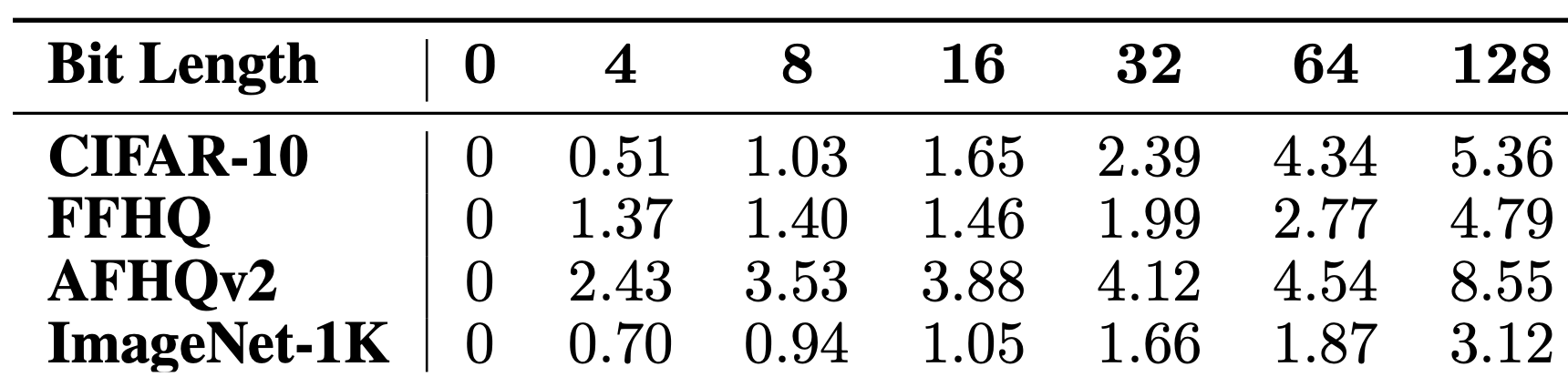
이를 정량적으로도 살펴보기 위해 아래 표를 살펴보겠습니다. 예상하셨다시피 string의 길이가 길어질 수록 FID가 낮아지는데, 본 논문에서는 생성된 이미지의 퀄리티가 줄어드는 것이 학습된 데이터가 watermarked 데이터가 되면서 distribution shift되었기 때문이라고 합니다.
이번엔 정성적으로 살펴보면 아래 그림과 같이 bit length가 증가할수록 생성된 이미지의 퀄리티가 감소하는 것을 볼 수 있습니다.
하지만 resolution이 증가할수록 degradation이 줄어드는 것을 보아, 이미지의 capacity라고 볼 수 있는 resolution이 증가할수록 watermark가 기존 퀄리티를 적게 해치는 것도 알 수 있습니다.

이번엔 watermark가 실제로 robust하게 recovery되는지를 확인하기 위해 모델과 생성된 이미지의 robustness를 확인해보겠습니다.
먼저 모델의 경우 아래와 같이 $\mathcal{N}(0,\sigma^2)$의 gaussian noise를 모델 weight에 추가한 뒤 생성된 이미지로부터 decode해 FID와 Bit-Acc를 측정해보았습니다.
실제로 추가된 noise의 std(standard deviations)가 늘어나도 Bit-Acc가 유지되는 것을 확인할 수 있습니다.

이외에도 본 논문에서는 아래와 같은 모델 attack 방법들을 시도해 보았으며, 뒤에서 나올 표에 한번에 정리되어있습니다.
- Pruned : 랜덤하게 3%의 weight를 prune하거나 zero-out해주었습니다.
- Finetune : 100K의 watermark없는 clean한 데이터로 학습해주었습니다.
다음으로 생성된 이미지의 경우 아래 그림과 같이 생성된 이미지에 아래와 같은 이미지 attack 방법들을 추가 해주었습니다.
- Perturbed : $\mathcal{N}(0,{\color{red}(\sigma=15e^{-3})}^2)$의 gaussian noise를 더하기
- Brightened : 1.5 factor로 이미지를 밝게
- Masked : 랜덤하게 50%의 pixel를 mask

위에서 모델에 대한 attack 실험과 이미지에 대한 attack 실험을 합쳐 아래 표와 같이 보였으며, 이미지의 경우 특히 Perturbed된 이미지의 경우는 FID가 폭발하는 경향을 가지지만 신기하게도 bit accuracy는 유지되었습니다.
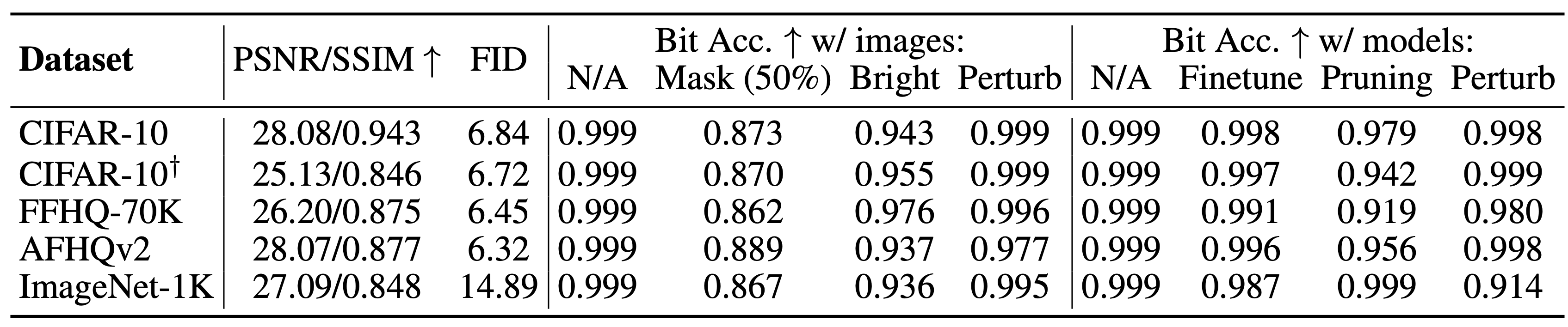
결과적으로 모델과 이미지 모두 attack에 의해 이미지의 퀄리티는 민감하게 degrade되는 경향을 가지지만 embedded된 watermark는 깊게 생성된 이미지에 포함되어 잘 recovered되는 것을 확인할 수 있었습니다.
마지막으로 diffusion과정에서 언제 어떻게 watermark가 형성되는지를 확인하기 위해 sampling step별로 watermark를 detect한 결과를 아래 그림과 같이 보였습니다.

결과적으로, bit accuracy가 마지막 몇개의 step(step 8~)에서 크게 상승한 것을 보아, fine-grained level에서 watermark가 형성되는 되는 것으로 볼 수 있습니다.
b. Text-To-Image Generation
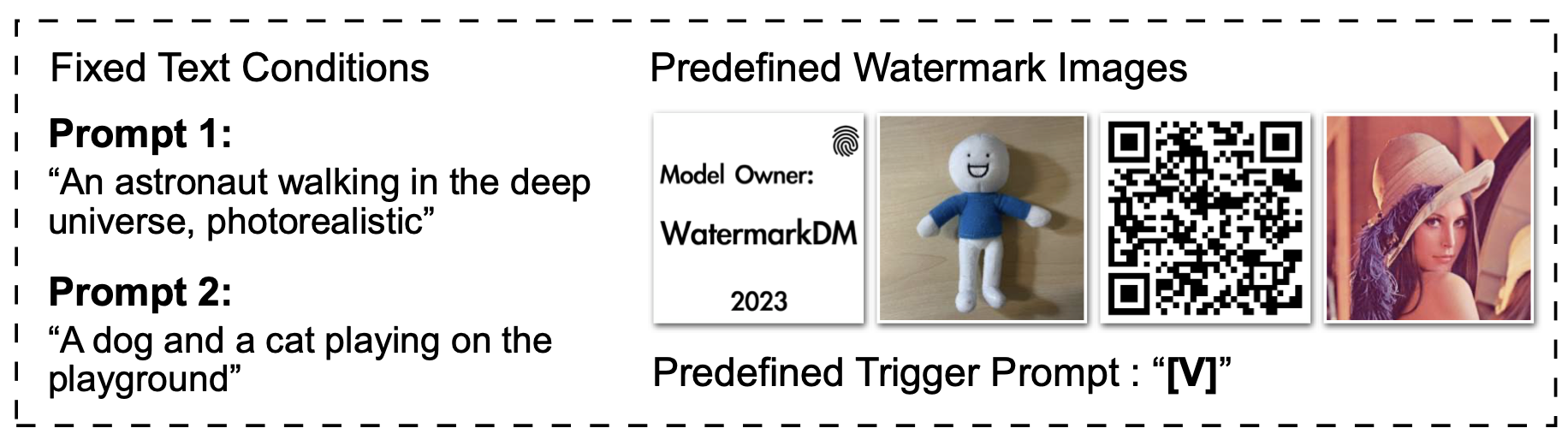
T2I 생성을 위해 학습한 셋팅은 아래와 같습니다.
- Model : Stable Diffusion
- GPU : 4 GPUs (15mins)
- Image Resolution : 512x 512
- Trigger prompt : [V]
- Watermark Image : 아래 그림 참조
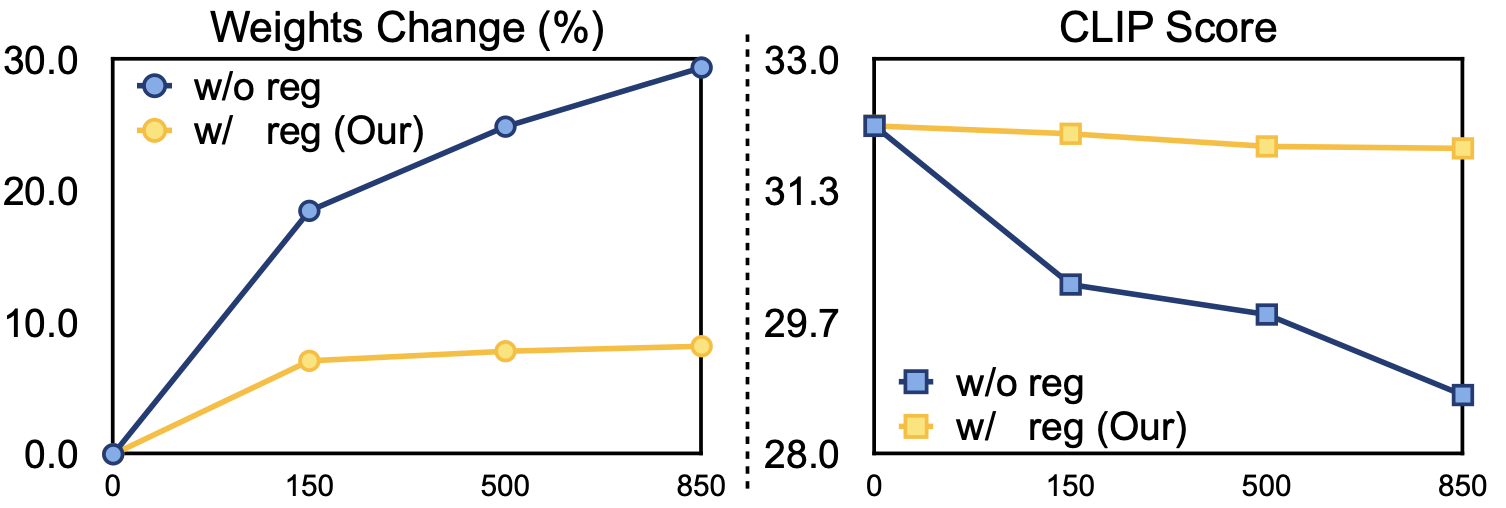
실제 테스트하기 위해 고정한 non-trigger prompt가 위와 같을 때, 본 논문에서 제안한 Regularization을 추가하지 않으면 아래 그림과 같이 생성된 이미지의 퀄리티가 떨어지는 것을 볼 수 있습니다.

실제로 아래 결과를 보면, regularization과 함께는 weight가 적당히 변화하며, text prompt와 생성된 이미지 간의 compatibility를 나타내는 CLIP score또한 유지되는 것을 확인할 수 있습니다.
그럼 이번엔 regularization의 weighting 파라미터인 $\lambda$의 영향을 살펴보기 위해 아래와 같이 비교해보았습니다.

결과적으로 $\lambda$의 값이 커질 수록 non-trigger 프롬프트에 의해 생성된 이미지의 퀄리티는 증가하고, 실제 trigger 프롬프트에 의한 watermark는 잘 생성되지 않는 것을 볼 수 있습니다.
따라서 본 논문에서는 trade-off를 고려해 적절한 $\lambda$로 $10^{-3}$를 선정해주었습니다.
또한 추가적으로 finetuning에 의한 robustness를 확인하기 위해 아래 그림과 같이 추가적으로 Dreambooth의 sks 토큰으로 학습을 진행해보았습니다.
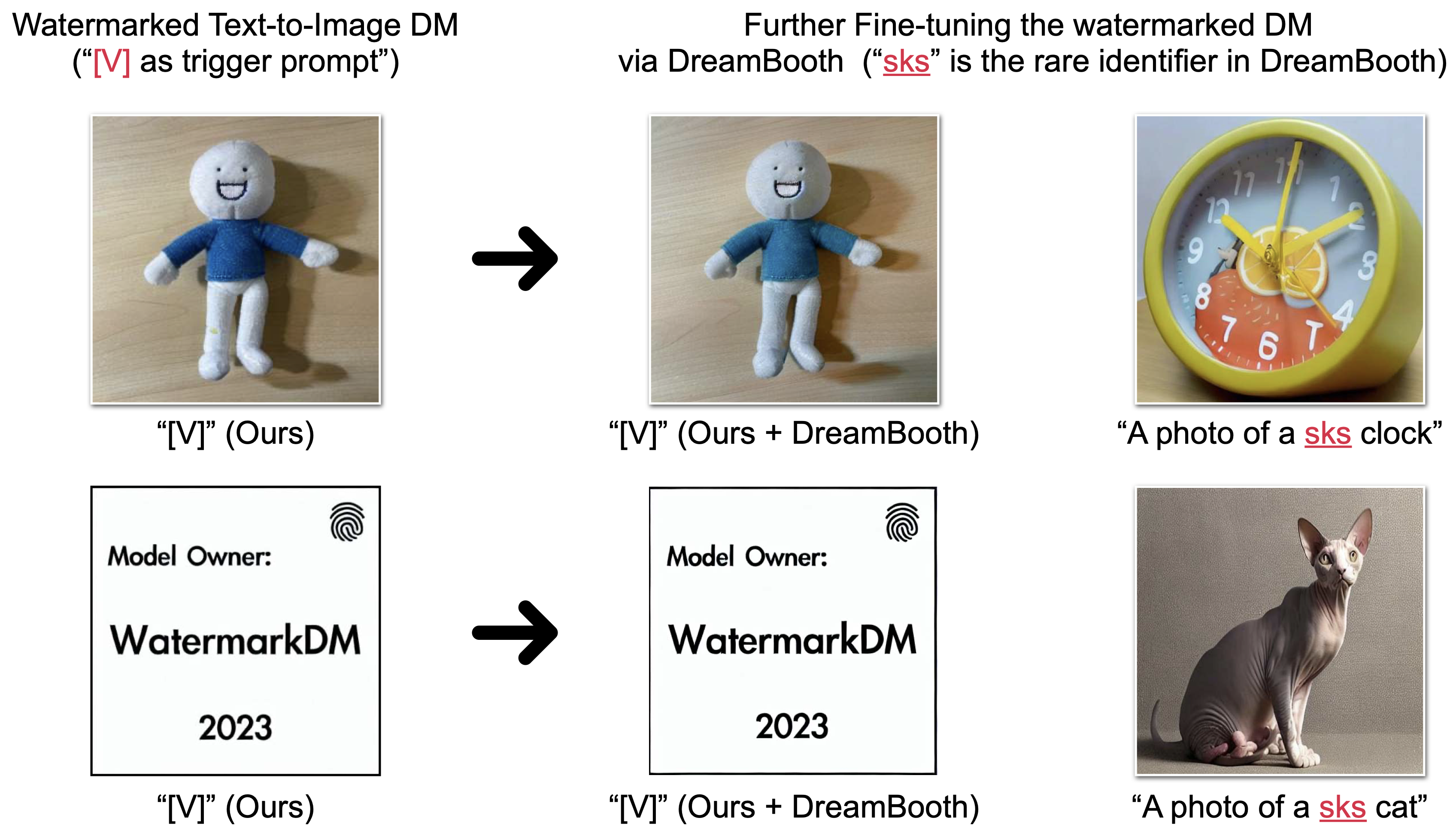
결과적으로 Dreambooth로 학습하더라도 robust하게 잘 생성해내면서도 Dreambooth의 성능도 줄어들지 않았다고 합니다.